







数据集:某企业销售的6种商品所对应的送货及用户反馈数据
参考及来源:基于机器学习的物流预测可视化(附源码)_可视化和仓库预测模型-CSDN博客
- 分析该企业配送服务是否存在问题
原文章利用该数据集解决了3种问题,本文针对原文章的第一个问题(评估某物流企业配送服务质量)进行算法尝试,改用决策树算法进行评估。
决策树算法对交货时间进行预测,并与实际交货情况进行比较,以评估配送服务的准时性和延迟情况,数据集共1161条订单信息

import matplotlib.pyplot as plt
import pandas as pd
import warnings
# 忽略警告信息,警告非报错,不影响代码执行
warnings.filterwarnings("ignore")
data = pd.read_csv(r'D:\桌面下载\decision tree\logisctics prediction\logistics prediction ML\data_wuliu\data_wuliu.csv', encoding='gbk')
data.info()输出结果: <class 'pandas.core.frame.DataFrame'> RangeIndex: 1161 entries, 0 to 1160 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 订单号 1159 non-null object 1 订单行 1161 non-null int64 2 销售时间 1161 non-null object 3 交货时间 1161 non-null object 4 货品交货状况 1159 non-null object 5 货品 1161 non-null object 6 货品用户反馈 1161 non-null object 7 销售区域 1161 non-null object 8 数量 1157 non-null float64 9 销售金额 1161 non-null object dtypes: float64(1), int64(1), object(8) memory usage: 90.8+ KB
通过info()识别缺失值、无关列检查可以看出 1.订单号、货品交货情况、数量:存在缺失值,但是缺失量不大,可以删除 2.订单行,对分析无关紧要,没有实质意义,可以考虑删除 3.销售金额格式有问题(万元|元,逗号问题),数据类型需要转换为int|float
数据清洗
# 删除重复记录,遇到重复保留第一行,删除后代替源数据
data.drop_duplicates(keep='first', inplace=True)
# 删除缺失值(有na的整行数据,axis=0,how='any'默认)
data.dropna(axis=0, how='any', inplace=True)
# 删除‘订单行’这一列,第二次运行删除操作会报错
data.drop(columns=['订单行'], inplace=True, axis=1)
# 更新索引:drop=True:把原来的索引index列删除,重置index,原来的索引因为删除了行数据变乱
data.reset_index(drop=True, inplace=True)
data# 取出‘销售金额’列,对每个数据进行清洗,自定义map函数处理万元|元
# 编写自定义过滤函数:1.删除逗号,2.转成float:如果是万元则删除万元再*10000,否则,删除元
def data_deal(number):
# 找到带有万元的,取出数字,去掉逗号,转成float,*10000
if number.find('万元') != -1:
# number[:number.find('万元')]去掉万元
# number[:number.find('万元')].replace(',','')将逗号替换为空
number_new = float(number[:number.find('万元')].replace(',','')) * 10000
pass
else: #找到带有元的,删除元,删除逗号,转成float
if number.find('元') != -1:
number_new = float(number.replace('元','').replace(',',''))
pass
return number_new
data['销售金额'] = data['销售金额'].map(data_deal)
data异常值处理
data.describe()count,1137.000000,1.137000e+03
mean,76.655673,1.226091e+05
std,591.709671,1.118837e+06
min,1.000000,0.000000e+00
25%,1.000000,2.940000e+03
50%,1.000000,9.402000e+03
75%,4.000000,3.577300e+04
max,11500.000000,3.270000e+07
销售金额最小值为0,有异常值
# 销售金额==0,采用删除方法,因为数据量很小
data = data[data['销售金额'] != 0]
data.describe()数据规整
增加一项辅助列:月份
data.loc[:, '销售时间'] = pd.to_datetime(data['销售时间'])
data.loc[:, '月份'] = data['销售时间'].apply(lambda x: x.month)
datadata1 = data.copy() 数据分析
根据数据评估该企业配送服务质量
-
可以使用决策树算法对交货时间进行预测,并与实际交货情况进行比较,以评估配送服务的准时性和延迟情况。
-
可以建立一个基于CART算法的决策树分类模型来预测和评估配送服务是否存在问题,将"货品交货状况"作为目标变量,其他列作为特征变量。先对目标变量进行编码,然后创建模型分类器进行训练和预测。
# 导入所需的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import RandomizedSearchCV# 数据预处理
# 将字符串类型或非数值型类别标签 转换为唯一的整数编码
le = LabelEncoder()
data1['销售区域'] = le.fit_transform(data1['销售区域'])
data1['货品'] = le.fit_transform(data1['货品'])
data1['货品用户反馈'] = le.fit_transform(data1['货品用户反馈'])
# 将日期特征转换为天数差
# 可以将时间序列特征转化为数值型特征,便于决策树模型处理。天数差能反映时间间隔长短对交货状况的影响。
data1['销售时间'] = (pd.to_datetime(data1['销售时间']) - pd.to_datetime('2016-07-01')).dt.days
data1['交货时间'] = (pd.to_datetime(data1['交货时间']) - pd.to_datetime('2016-07-01')).dt.days
# 创建特征向量X和目标变量y
X = data1.drop(['订单号', '货品交货状况'], axis=1)
y = data1['货品交货状况']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练模型
model = DecisionTreeClassifier(random_state=42)
# 使用决策树分类器
model.fit(X_train, y_train)
# 预测
# y_pred表示模型对输入数据 X_test(测试集特征)的预测结果
y_pred = model.predict(X_test)
print(y_pred)# 结果展示
a = pd.DataFrame()
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
print(a.head())# 预测概率
y_pred_proba = model.predict_proba(X_test)
print(y_pred_proba[0:5])# 特征重要性分析
features = X.columns
importances = model.feature_importances_
importance_df = pd.DataFrame({'特征': features, '特征重要性': importances})
importance_df = importance_df.sort_values('特征重要性', ascending=False)
importance_df# 参数调优
# 定义决策树的参数网格
param_dist = {
'max_depth': [None, 5, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'criterion': ['gini', 'entropy']
}
# 构建分类器
clf = DecisionTreeClassifier(random_state=42)
clf_random = RandomizedSearchCV(
estimator=clf,
param_distributions=param_dist,
n_iter=10,
cv=3,
verbose=2,
random_state=42,
n_jobs=1
)
# 传入数据进行调优
clf_random.fit(X_train, y_train)
# 输出调优结果
print("最好的模型参数:", clf_random.best_params_)
print("最好的模型:", clf_random.best_estimator_)
print("最好的分数:", clf_random.best_score_)print("最好的分数:", clf_random.best_score_)
#%%
# 准确度评估
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
if accuracy > 0.8:
print("配送服务正常")
else:
print("存在配送服务问题")结果分析:模型根据已知数据学习,预测是否按时交货的准确率为0.856;配送服务正常。
决策树模型评价和可视化
# 决策树可视化
from sklearn.tree import plot_tree
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体显示中文
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示异常问题
plt.figure(figsize=(60,60))
plot_tree(model, filled=True, feature_names=X.columns, class_names=y.unique())
plt.show() # 保存时提升分辨率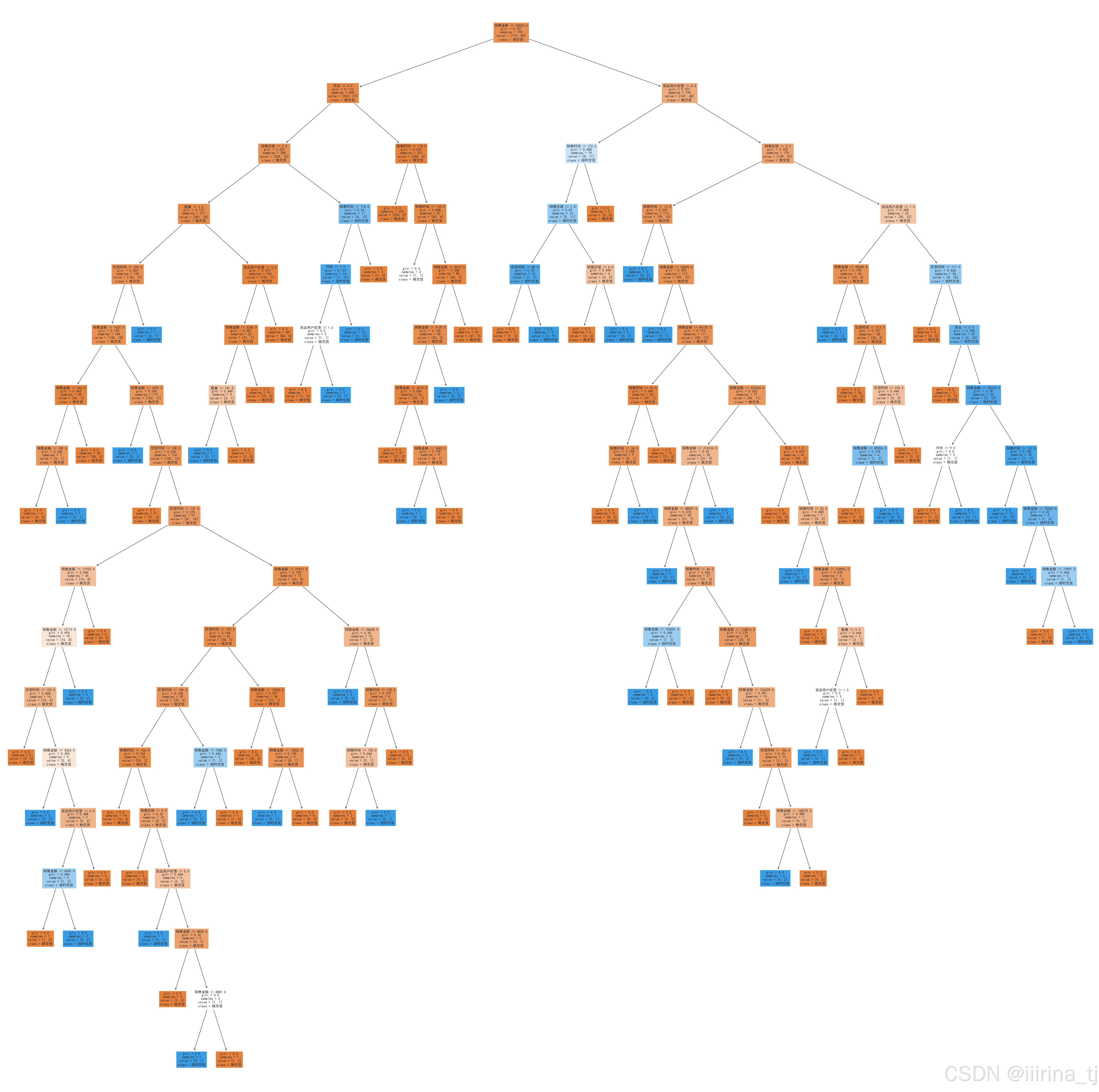
混淆矩阵模型评价
# 绘制混淆矩阵
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
# 对目标变量 y 进行标签编码
le_y = LabelEncoder() # 创建独立的 LabelEncoder 实例
y = le_y.fit_transform(data1['货品交货状况']) # 编码目标变量
# 检查编码后的类别名称(重要!)
print("目标变量编码后的类别顺序:", le_y.classes_)
# 输出应为 ['按时交货', '晚交货'] 或其他实际类别(注意顺序)
# 生成混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 确保类别名称与编码顺序一致
class_names = le_y.classes_ # 使用LabelEncoder的classes_属性
# 绘制热力图
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=class_names,
yticklabels=class_names)
# 手动设置刻度位置和标签
plt.xticks(ticks=[0.5, 1.5], labels=class_names, rotation=0) # 根据类别数量调整
plt.yticks(ticks=[0.5, 1.5], labels=class_names, rotation=0) # 确保位置对齐
plt.title('混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.show()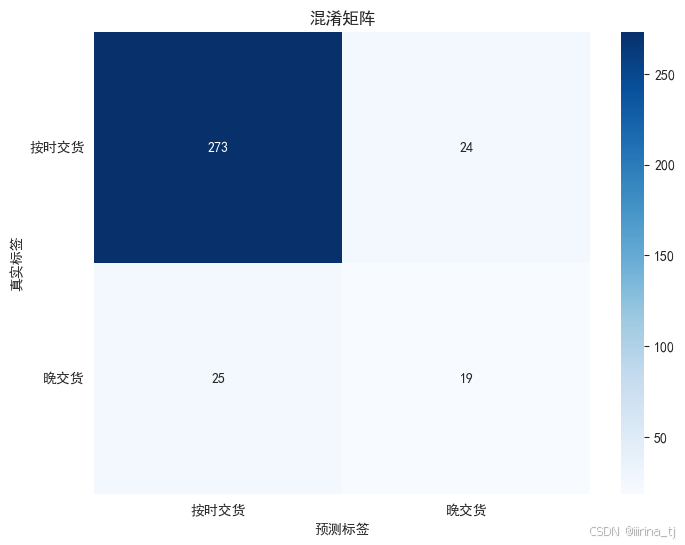
# 分析混淆矩阵
print("\n模型性能分析:")
print(f"1. 按时交货准确率:{cm[0][0]/(cm[0][0]+cm[0][1])*100:.1f}%")
print(f"2. 总体准确率:{accuracy*100:.1f}%")模型性能分析:
1. 按时交货准确率:91.9%
2. 总体准确率:85.6%
这里的晚交货率过低,需要进一步在数据预处理阶段优化
# 模型不纯度
model = DecisionTreeClassifier(random_state=10)
path = model.cost_complexity_pruning_path(X_train, y_train)
print("模型不纯度:", max(path.impurities))#输出最大的模型不纯度模型不纯度: 0.19097345832838886
Alpha(α)是决策树中成本-复杂度剪枝的核心参数,用于平衡模型复杂度和拟合能力
# 绘制图形观察"叶节点总不纯度随alpha值变化情况"
fig, ax = plt.subplots()
plt.rcParams['font.sans-serif'] = ['SimHei']#解决图表中中文显示问题
ax.plot(path.ccp_alphas, path.impurities, marker='o', drawstyle="steps-post")
ax.set_xlabel("有效的alpha(成本-复杂度剪枝参数值)")
ax.set_ylabel("叶节点总不纯度")
ax.set_title("叶节点总不纯度随alpha值变化情况")
plt.show()
总结: 如果希望树的分类效果更好(不纯度低),可以选择较小的alpha值。 如果希望树的结构更简单(避免过拟合),可以选择较大的alpha值
# 绘制图形观察“节点数和树的深度随alpha值变化情况”
models = []
for ccp_alpha in path.ccp_alphas:
model = DecisionTreeClassifier(random_state=10, ccp_alpha=ccp_alpha)
model.fit(X_train, y_train)
models.append(model)
print("最后一棵决策时的节点数为: {} ;其alpha值为: {}".format(
models[-1].tree_.node_count, path.ccp_alphas[-1]))#输出最path.ccp_alphas中最后一个值,即修剪整棵树的alpha值,只有一个节点
node_counts = [model.tree_.node_count for model in models]
depth = [model.tree_.max_depth for model in models]
fig, ax = plt.subplots(2, 1)
ax[0].plot(path.ccp_alphas, node_counts, marker='o', drawstyle="steps-post")
ax[0].set_xlabel("alpha")
ax[0].set_ylabel("节点数nodes")
ax[0].set_title("节点数nodes随alpha值变化情况")
ax[1].plot(path.ccp_alphas, depth, marker='o', drawstyle="steps-post")
ax[1].set_xlabel("alpha")
ax[1].set_ylabel("决策树的深度depth")
ax[1].set_title("决策树的深度随alpha值变化情况")
fig.tight_layout()
plt.show()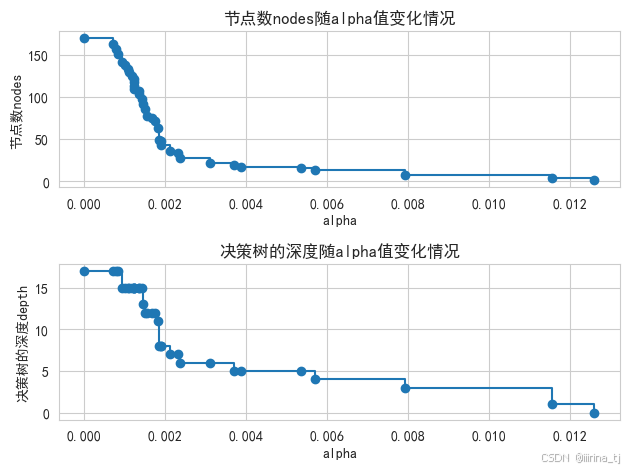
当alpha值较小时,树的深度较大,结构复杂。 随着alpha值的增加,树的深度迅速减少,结构简化。 在alpha值较大的范围内,深度趋于稳定,进一步增加alpha值对深度的影响较小
# 绘制图形观察“训练样本和测试样本的预测准确率随alpha值变化情况”
train_scores = [model.score(X_train, y_train) for model in models]
test_scores = [model.score(X_test, y_test) for model in models]
fig, ax = plt.subplots()
ax.set_xlabel("alpha")
ax.set_ylabel("预测准确率")
ax.set_title("训练样本和测试样本的预测准确率随alpha值变化情况")
ax.plot(path.ccp_alphas, train_scores, marker='o', label="训练样本",
drawstyle="steps-post")
ax.plot(path.ccp_alphas, test_scores, marker='o', label="测试样本",
drawstyle="steps-post")
ax.legend()
plt.show()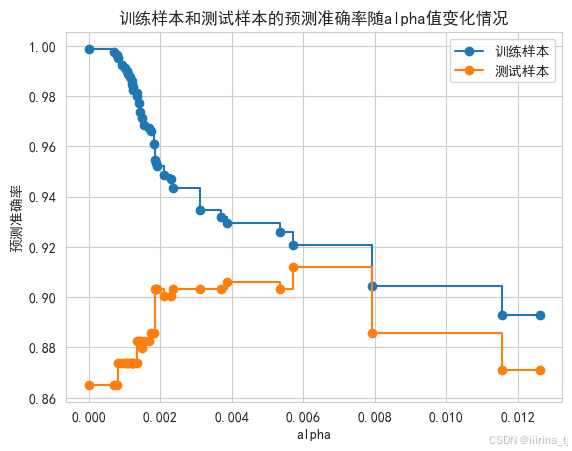
# 交叉验证法寻找最优aplhpa
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
param_grid = {'ccp_alpha': [0.001, 0.002, 0.004, 0.006, 0.008, 0.01]}
model = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5)
model.fit(X_train, y_train)
print("最优 Alpha:", model.best_params_['ccp_alpha'])找到最优alpha值后可以继续在过拟合和欠拟合之间探索平衡点,使模型的泛化能力最佳
总结 模型通过销售时间和交货时间的天数差作为特征,预测近期订单的交货状态,从而评估企业的配送服务质量 训练集占70%(test_size=0.3),测试集占30% 模型分析数据准确率达85.6%,若低于80%则判定存在显著配送服务问题 对于特征重要性来说 销售金额与数量特征重要性排名最高,高金额或大批量订单易导致晚交货(可能因物流资源不足或优先级分配不均); 在交货时间差方面,交货周期较长的订单更易延迟(需优化仓储与运输链路效率); 而区域与货品类型上,特定区域(如偏远地区)或特殊货品(如易损品)的配送问题突出 针对混淆矩阵的数据表示,“晚交货”的召回率较低,表明需针对性优化异常订单处理流程 模型后续可以根据alpha为0.06的剪枝策略继续平衡模型复杂度与泛化能力,避免过拟合历史数据
模型存在一定的问题,后续需进行进一步优化,性能低于随机森林模型



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









