









在解析X.509格式的数字证书时,有时候从证书中提取出的 commonName、countryName 等项的值类型是 BMPString,特别当这些值是中文的时候。此时如果在 Windows 的控制台下使用使用 wprintf() 输出这些值,显示的结果是乱码。
为了搞清楚产生乱码的原因,找到一张证书,查看其中的 countryName,对应的 ASN.1 编码类型是BMPString,编码是:0x1E, 0x4, 0x4E, 0x2D, 0x56, 0xFD,对应值为“中国”。在网上查询了”中国“对应的 Unicode 编码是 {0x4E, 0x2D, 0x56, 0xFD},0x4E, 0x2D 对应字符“中”,0x56, 0xFD 对应字符“国” 。将字符 0x4E, 0x2D, 0x56, 0xFD 顺序放入一个字符数组,依次调用 setlocale() 、wprintf() 函数,输出为乱码。
在网上查了一下,对于BMPString 的 ASN.1 编码,其负载部分采用 Unicode 编码中的 UTF-16 编码方式,一个字符的编码占两个字节。但是这两个字节中哪一个用来存放编码的高 8 位、哪一个用来存放编码的低 8 位,在不同的地方有不同处理方式。在 ASN.1 编码中,一般对于负载部分的编码都采用 big-endian 顺序,所以从数字证书中提取出来的“中国”对应的编码为 {0x4E, 0x2D, 0x56, 0xFD},其顺序是 Big-endian 顺序。在 Intel 的 CPU 上通常使用 little-endian 字节顺序,Windows 中处理数据也采用 little-endian 顺序,所以在 Windows 中试图输出Big-endian 顺序编码的字符,当然会产生乱码。(顺便说一句,对于 UniversalString 的ASN.1 编码,其负载部分采用Unicode 编码中的 UTF-32 编码方式,一个字符的编码占四个字节。)
要解决输出乱码的问题,方法是在输出前,先将 Big-endian 顺序编码的字符转换为 little-endian 顺序编码的字符,然后再输出,就不会产生乱码了。下面给出一个示例程序:
/**************************************************
* Author: HAN Wei
* Author's blog: http://blog.csdn.net/henter/
* Date: Oct 30th, 2014
* Description: demonstrate how to print BMPString
on Windows console
**************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <locale.h>
/**************************************************
*函数名称:InterchangeEndianOrder
*功能: 颠倒 BMPString 编码中每一个 UTF-16 字符 的 endian 顺序
*参数:
BMPString [in]
BMPString_len [in] BMPString 的长度,以字节为单位
*返回值:
0 成功
-1 失败
*备注:
BMPString 通常由 UTF-16 字符组成,UTF-16 字符有时采用 big-endian 顺序,
有时采用 little-endian 顺序,本函数的功能是颠倒 endian 顺序
**************************************************/
int InterchangeEndianOrder(unsigned char *BMPString, unsigned int BMPString_len)
{
int i;
unsigned char *p, temp;
if ( (BMPString_len % 2) != 0 )
{
#ifdef _DEBUG
printf("Invalid BMPString byte length: %d.\n", BMPString_len);
printf("BMPString byte length must be multiple of 2!\n");
#endif
return (-1);
}
p = BMPString;
for (i=0; i < (int)( BMPString_len/2); i++)
{
temp=*p;
*p=*(p+1);
*(p+1)=temp;
p+=2;
}
return 0;
}
/**************************************************
*函数名称:PrintBMPString
*功能: 在 Windows 控制台界面下输出 BMPString
*参数:
BMPString [in]
BMPString_len [in] BMPString 的长度,以字节为单位
*返回值:
0 成功
-1 失败
**************************************************/
int PrintBMPString(unsigned char *BMPString, unsigned int BMPString_len)
{
unsigned char *buffer;
unsigned int buffer_len;
buffer_len = BMPString_len + 2; /* 缓冲区大小比 BMPString 的字节长度多出两个字节,
这两个字节用来存放 UTF-16 编码的字符串结束符 \0,
其对应编码是 0x0, 0x0 */
if ( !(buffer=(unsigned char *)malloc(buffer_len)) )
{
#ifdef _DEBUG
printf("malloc() function failed!\n");
#endif
return (-1);
}
memset(buffer, 0, buffer_len);
memcpy(buffer, BMPString, BMPString_len);
setlocale(LC_ALL, "chs");
if ( InterchangeEndianOrder(buffer, BMPString_len) )
{
printf("BMPstring is invalid!\n");
}
else
wprintf(L"BMPString: %ls\n", (wchar_t *)buffer);
free(buffer);
return 0;
}
int main(void)
{
int error_code;
unsigned char BMPString_data1[]={0x4e, 0x2d, 0x56, 0xfd}; /* 中文字符串"中国"对应的 Unicode 编码 */
unsigned char BMPString_data2[]={0x0, 0x55, 0x0, 0x73, 0x0, 0x65, 0x0, 0x72}; /* 英文字符串"User"对应的 Unicode 编码 */
wchar_t str[]=L"中国";
unsigned char *p;
int i;
if ( error_code = PrintBMPString(BMPString_data1, sizeof(BMPString_data1)) )
{
printf("Print BMPstring on Windows console failed!\n");
return (-1);
}
if ( error_code = PrintBMPString(BMPString_data2, sizeof(BMPString_data2)) )
{
printf("Print BMPstring on Windows console failed!\n");
return (-1);
}
/* 下面给出了说明 unicode 编码的字符在 Windows 中是如何存放的一个例子,
从显示结果可以看出每一个 UTF-16 字符都是以 little-endian 顺序存放 */
printf("\n");
setlocale(LC_ALL, "chs");
wprintf(L"%ls\n", str);
p=(unsigned char *)str;
printf("Wide character number is: %d\n", wcslen(str));
printf("Unicode encode on Windows platform: ");
for (i=0; i < (int)(wcslen(str)*2); i++)
{
printf("0x%x ", *p);
p++;
}
printf("\n");
system("pause");
return 0;
}
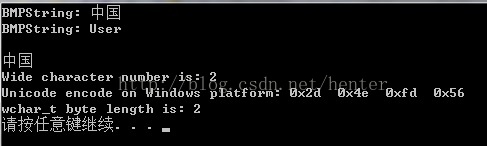
输出结果如下图:















 72
72

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









