







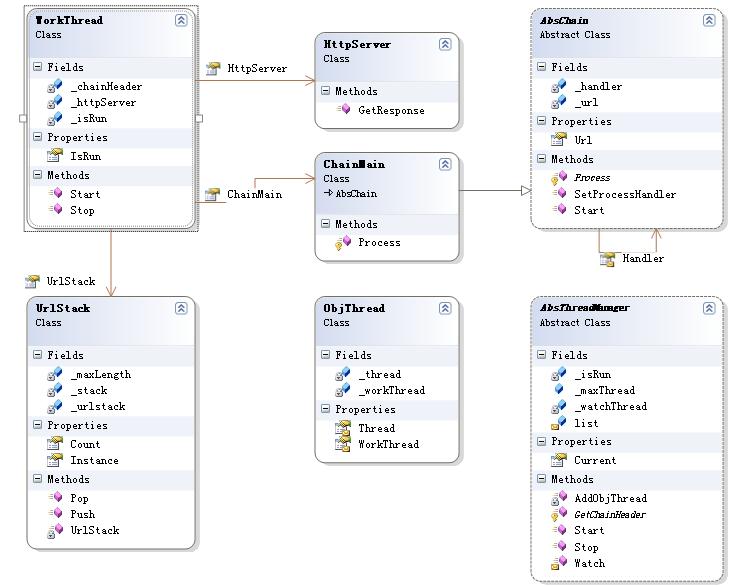
WorkThread类:
WorkThread类是工作线程类,每个工作线程类都包括一个职责链的头节点ChainMain、一个HttpServer类和一个UrlStack,其中UrlStack类采用了单构件设计模式,所以对于整个应该用程序都是使用一个UrlStack对象。
源代码如下:
namespace WebSpider
{
/// <summary>
/// 工作线程
/// </summary>
internal class WorkThread
{
private ChainMain _chainHeader = new ChainMain();
private HttpServer _httpServer = new HttpServer();
private bool _isRun = false;
/// <summary>
/// 职责链的头节点
/// </summary>
public ChainMain ChainMain
{
get
{
return _chainHeader;
}
}
public HttpServer HttpServer
{
get
{
return _httpServer;
}
}
public bool IsRun { get { return _isRun; } }
public UrlStack UrlStack
{
get
{
return UrlStack.Instance;
}
}
/// <summary>
/// 工作线程入口函数
/// </summary>
/// <param name="url">种子url</param>
public void Start()
{
try
{
_isRun = true;
while (_isRun)
{
//从地址堆栈中取出url
string url = UrlStack.Pop();
if (!string.IsNullOrEmpty(url))
{
string html = _httpServer.GetResponse(url);
if (!string.IsNullOrEmpty(html))
{
ChainMain.Url = url;
ChainMain.Start(html);
}
}
}
}
catch
{
}
}
/// <summary>
/// 停止工作线程
/// </summary>
public void Stop()
{
_isRun = false;
}
}
}
Start方法是工作线程的入口方法,它从UrlStack中取出url,并调用HttpServer的GetResponse方法取出Url对应网页的HTML代码,并将HTML代码传递给职责链的头节点ChainMain,由它的Start方法开始处理。回忆一下AbsChain的Start()方法,它是先调用自身类的Process方法,然后再调用_handler.Start()方法,就这样把处理过程传递下去。
UrlStack类:
UrlStack类非常的简单,它采用单构件设计模式,并维护了一个数据结构,该数据结构用来存储需要爬虫抓取的Url
源码如下:
namespace WebSpider
{
public class UrlStack
{
private static UrlStack _urlstack = new UrlStack();
private Queue<string> _stack = new Queue<string>();
private readonly int _maxLength = Convert.ToInt32(System.Configuration.ConfigurationManager.AppSettings["MaxLength"]);
private UrlStack() { }
public static UrlStack Instance
{
get { return _urlstack; }
}
public void Push(string url)
{
lock (this)
{
if (!_stack.Contains(url))
{
if (_stack.Count >= _maxLength)
{
_stack.Dequeue();
}
_stack.Enqueue(url);
}
}
}
public string Pop()
{
lock (this)
{
if (_stack.Count > 0)
{
return _stack.Dequeue();
}
else
{
return "";
}
}
}
public int Count { get { return _stack.Count; } }
}
}
在源码中我用的是一个队列,当然,用户也可以改成其它的数据结构,比如:Stack<T>,用队列就有点像广度优先搜索,用堆栈就有点像深度优先搜索。
未完,待续……















 2085
2085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









