






Cifar10/100数据集
从8000万个微小图像数据集中抽取出来的数据子集
Cifar10是完成10个分类的任务,Cifar100是完成100个分类的任务
Cifar10数据集的10个类别:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )
有50000张训练集,10000张测试集
图片大小32*32(尺寸比较小)
下载:
http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
格式解读
python脚本将数据转换成字典格式
一定要将图片存下来,分析哪些图片识别错了,深挖识别错的原因以提高识别正确率
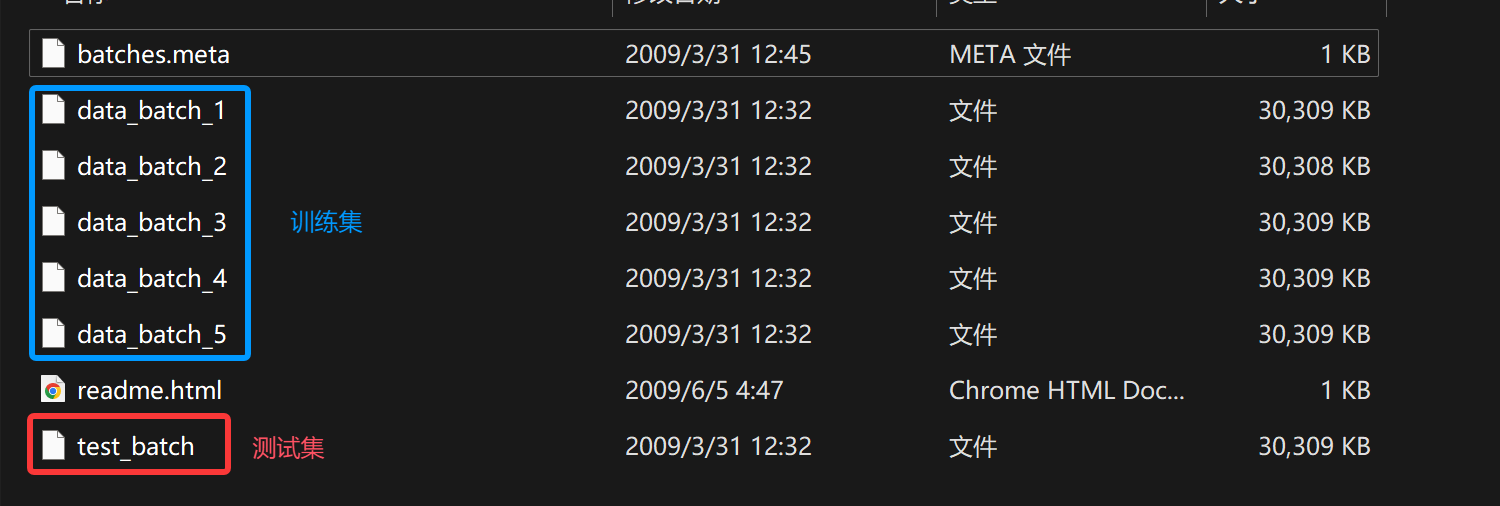
每个训练集下面都存放了10000张图片(一共5个训练集共50000张图片),每个测试集下面也存放了10000张图片 (一共一个测试集,一共10000张图片)
将数据进行解析,解析出的图片统一存放在两个分类文件夹下,分别为TRAIN和TEST
解析数据这一方法的代码实现:
def unpickle(file):
with open(file,'rb') as fo:
dict = pickle.load(fo,encoding='bytes')
return dict定义10个类别:
#定义10个类别的标签名数组
label_name = ["airplane",
"automobile",
"bird",
"cat",
"deer",
"dog",
"frog",
"horse",
"ship",
"truck"
]cifar10数据解析实现
global文件匹配
找到数据集文件夹的存放路径
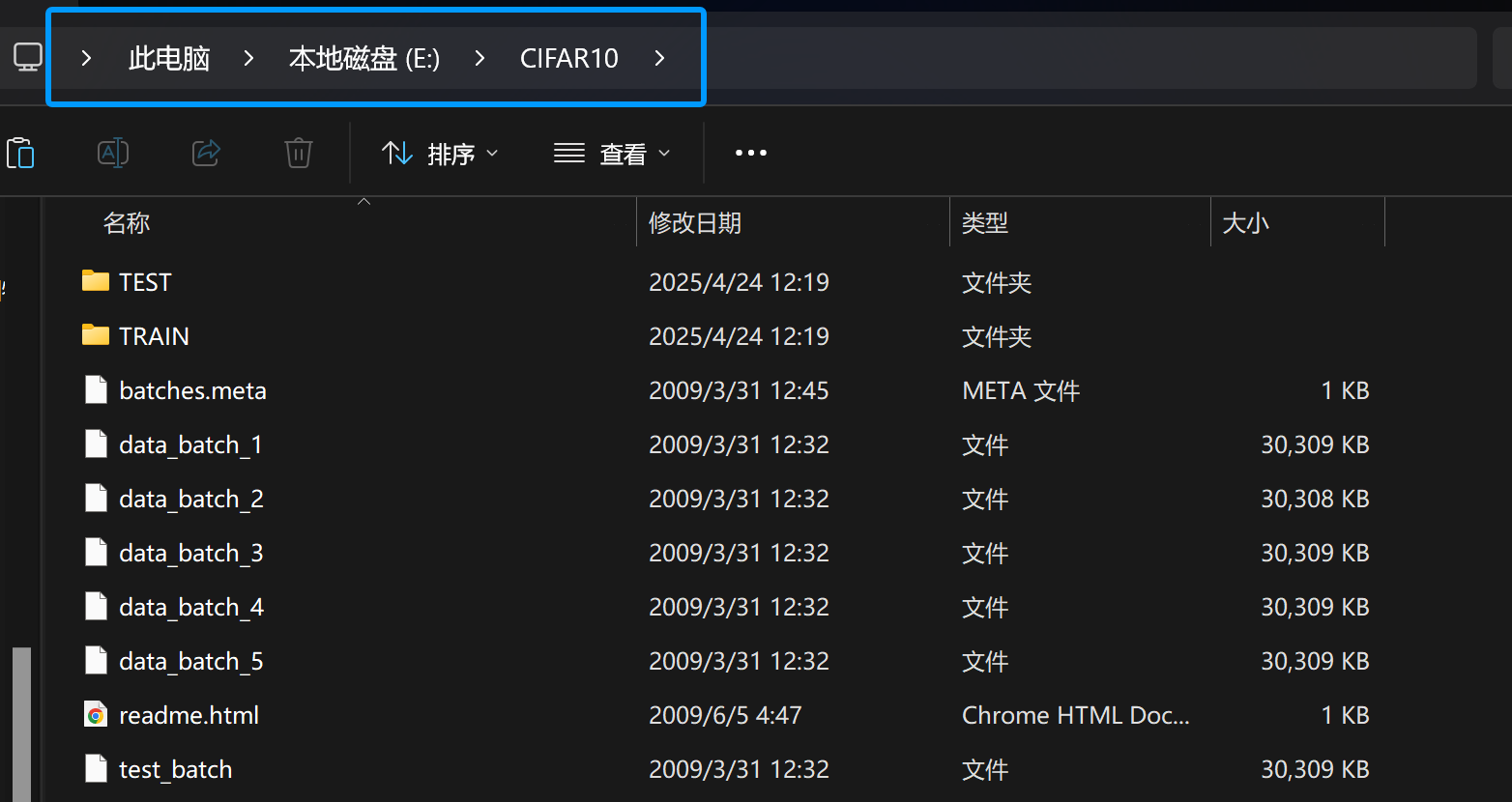
我存放到了E盘下的CIFAR10文件夹下
脚本:
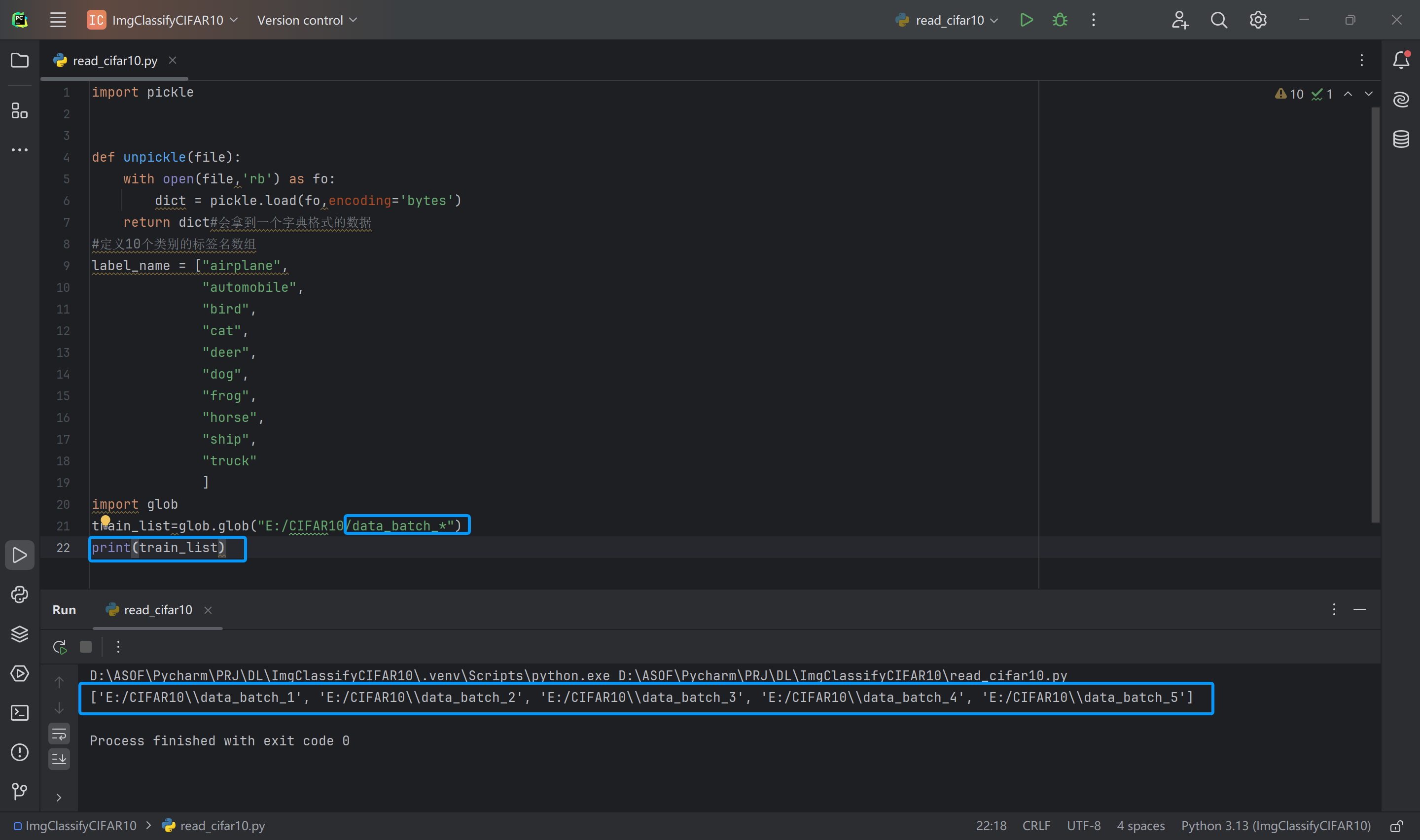
import glob
train_list=glob.glob("E:/CIFAR10/data_batch_*")
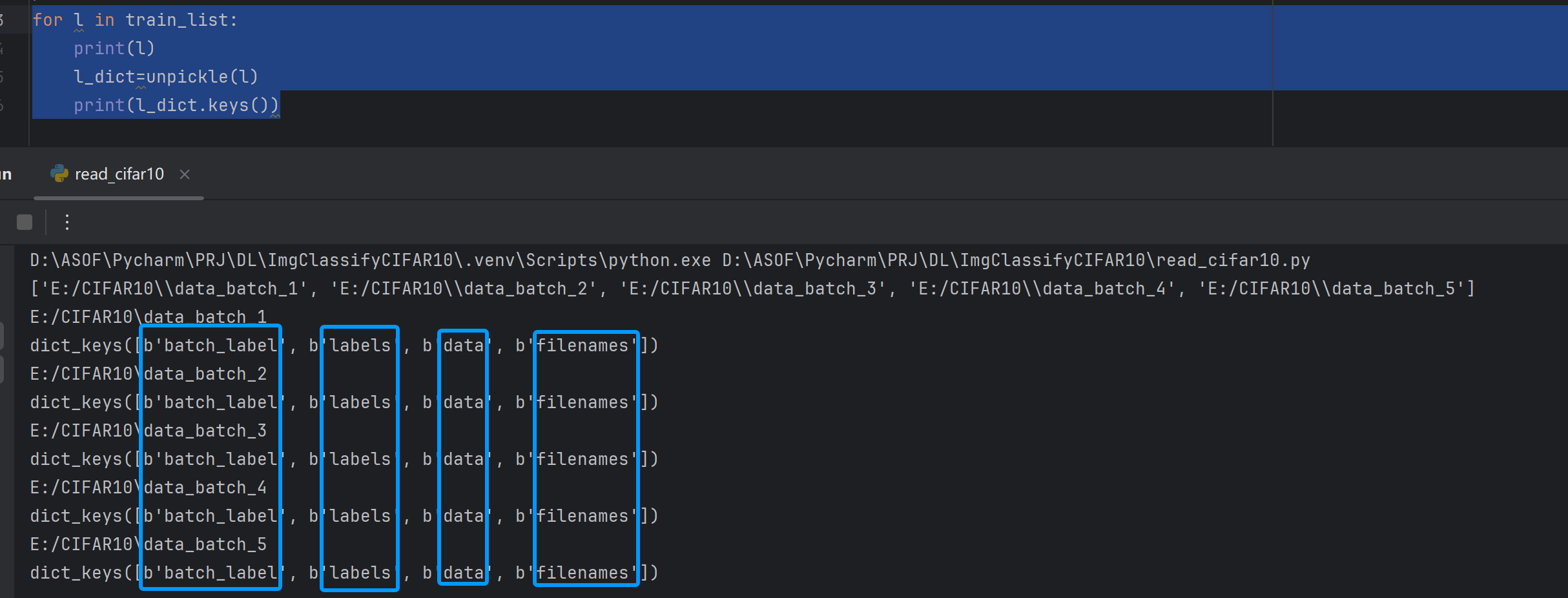
print(train_list)运行脚本,控制台显示打印出了5个数据集文件
遍历打印字典数据集的keys关键字:
for l in train_list:
print(l)
l_dict=unpickle(l)
print(l_dict.keys())结果:
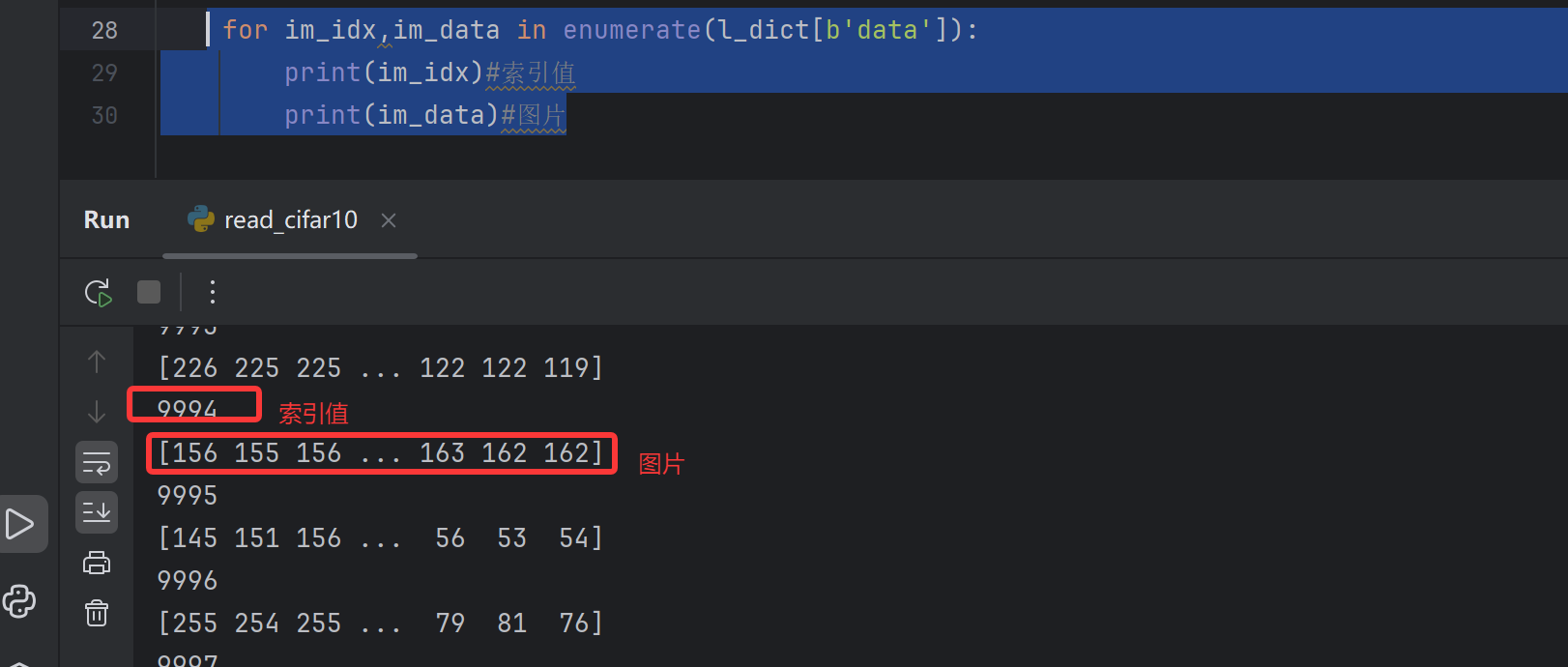
下面这个是遍历打印图片的索引值以及数据
for im_idx,im_data in enumerate(l_dict[b'data']):
print(im_idx)#索引值
print(im_data)#图片结果:如下图片数据是一个向量,因此要将图片进行reshape,因为图片是通道优先,因此要reshape成32*32,对数据进行转换成3*32*32
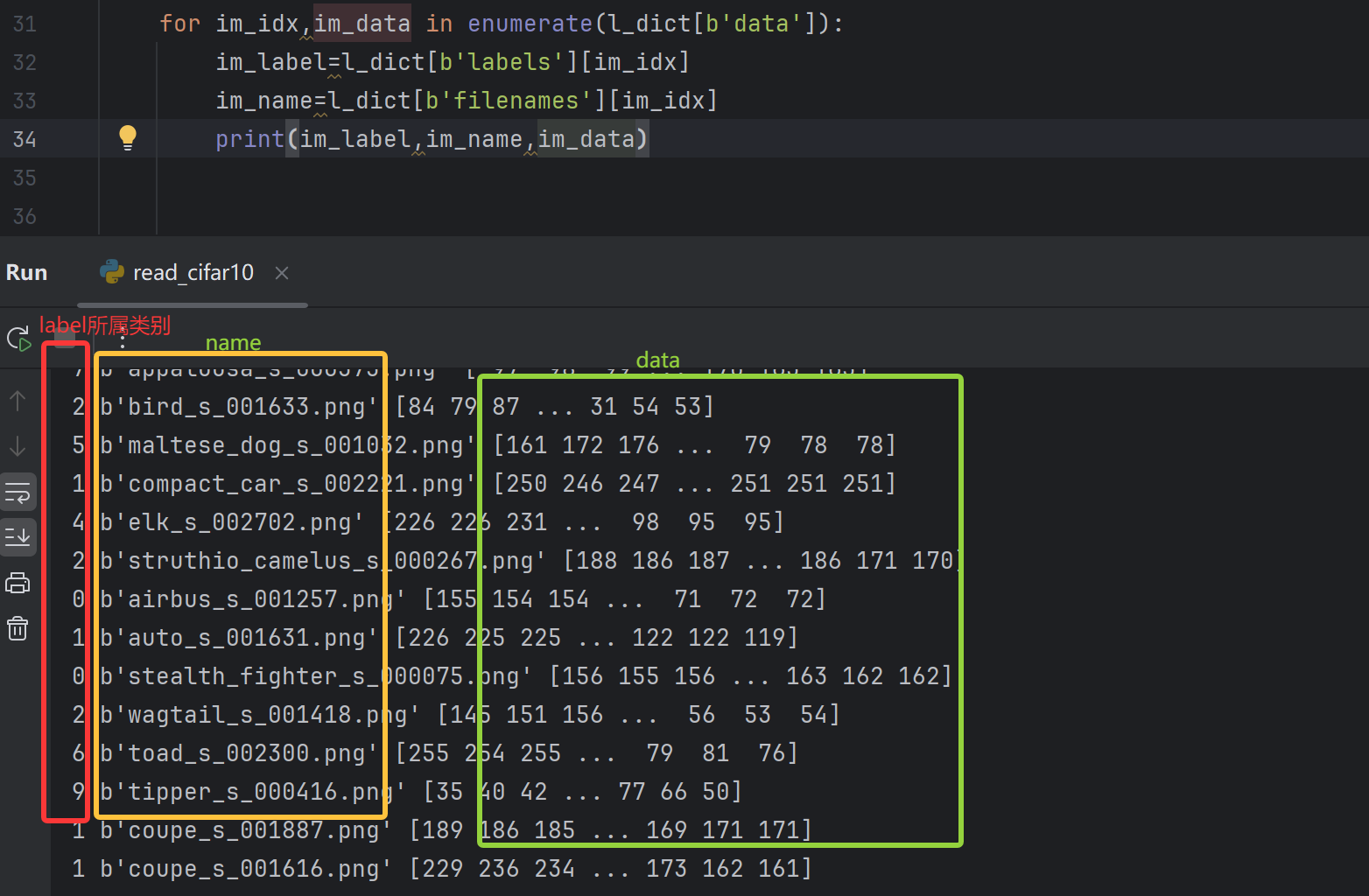
代码:
for im_idx,im_data in enumerate(l_dict[b'data']):
im_label=l_dict[b'labels'][im_idx]
im_name=l_dict[b'filenames'][im_idx]
print(im_label,im_name,im_data)结果:
实现数据可视化
首先在控制台输入:
pip install opencv-contrib-python
再导入cv2:
import cv2
以实现数据可视化
waitKey(0)以防图片被刷掉,这样做以后只有按空格的时候才会跳转到下一张
代码实现:
for im_idx,im_data in enumerate(l_dict[b'data']):
im_label=l_dict[b'labels'][im_idx]
im_name=l_dict[b'filenames'][im_idx]
print(im_label,im_name,im_data)
im_label_name=label_name[im_label]
im_data=np.reshape(im_data,[3,32,32])
im_data=np.transpose(im_data,(1,2,0))
cv2.imshow("im_data",cv2.resize(im_data,(200,200)))
cv2.waitKey(0) 结果:如下右边出现了图片,按空格切换到下一个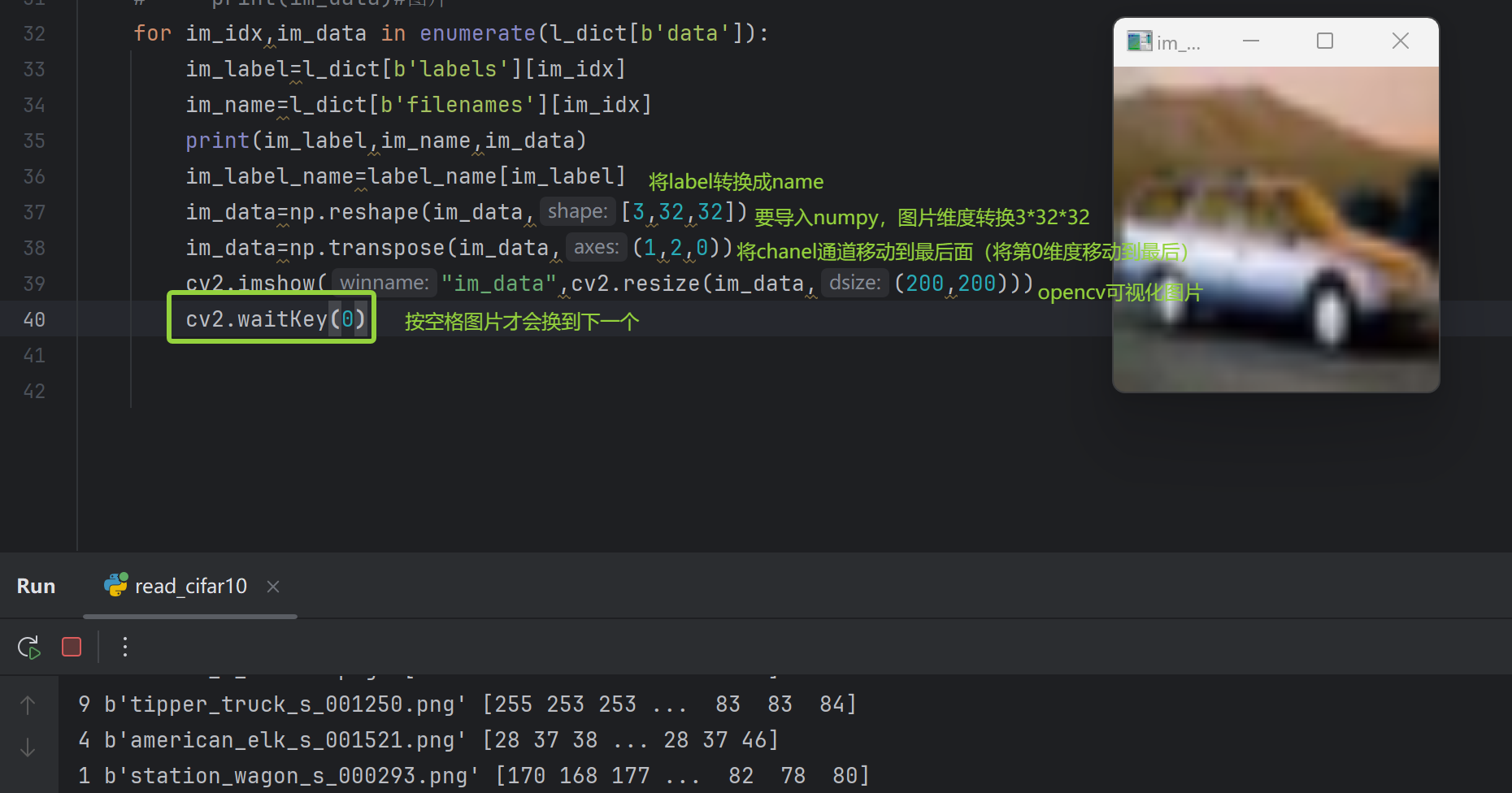
训练集图片存储到TRAIN目录
接下来将图片进行存储:
拿到label_name
01创建文件夹
os库可进行文件的创建
代码:
import os
save_path="E:/CIFAR10/TRAIN"
for im_idx,im_data in enumerate(l_dict[b'data']):
im_label=l_dict[b'labels'][im_idx]
im_name=l_dict[b'filenames'][im_idx]
print(im_label,im_name,im_data)
im_label_name=label_name[im_label]
im_data=np.reshape(im_data,[3,32,32])
im_data=np.transpose(im_data,(1,2,0))
# cv2.imshow("im_data",cv2.resize(im_data,(200,200)))
# cv2.waitKey(0)
if not os.path.exists("{}/{}".format(save_path,im_label_name)):
os.mkdir("{}/{}".format(save_path,im_label_name))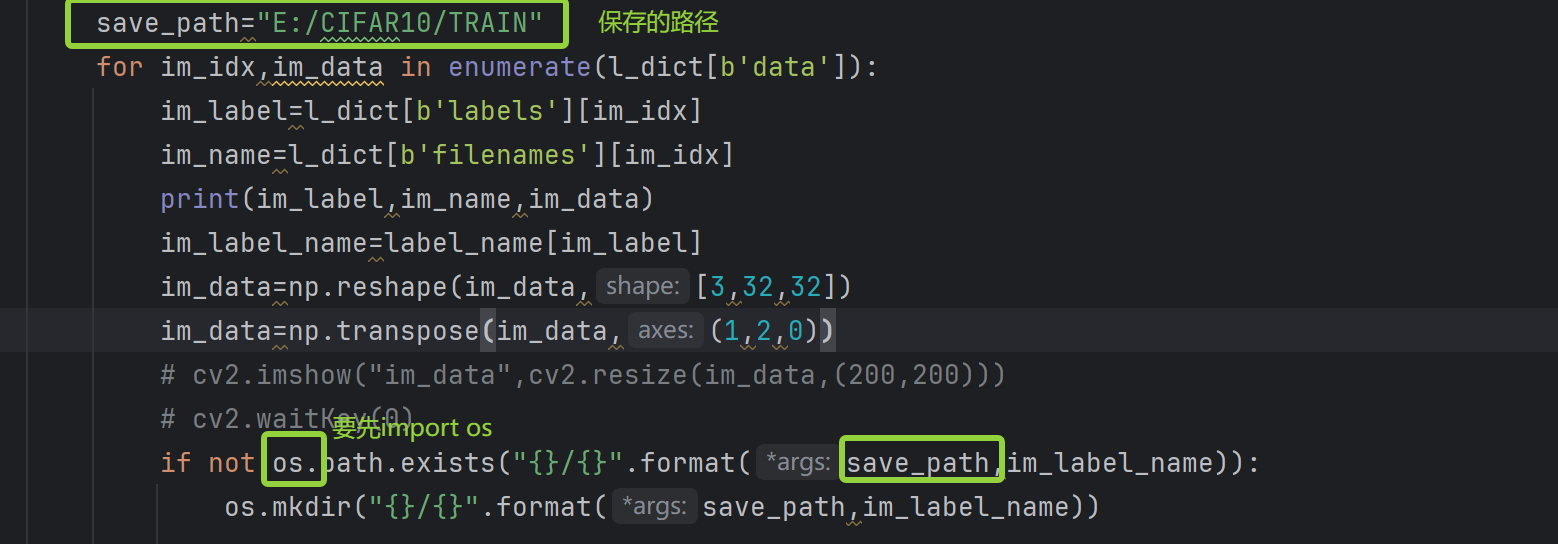
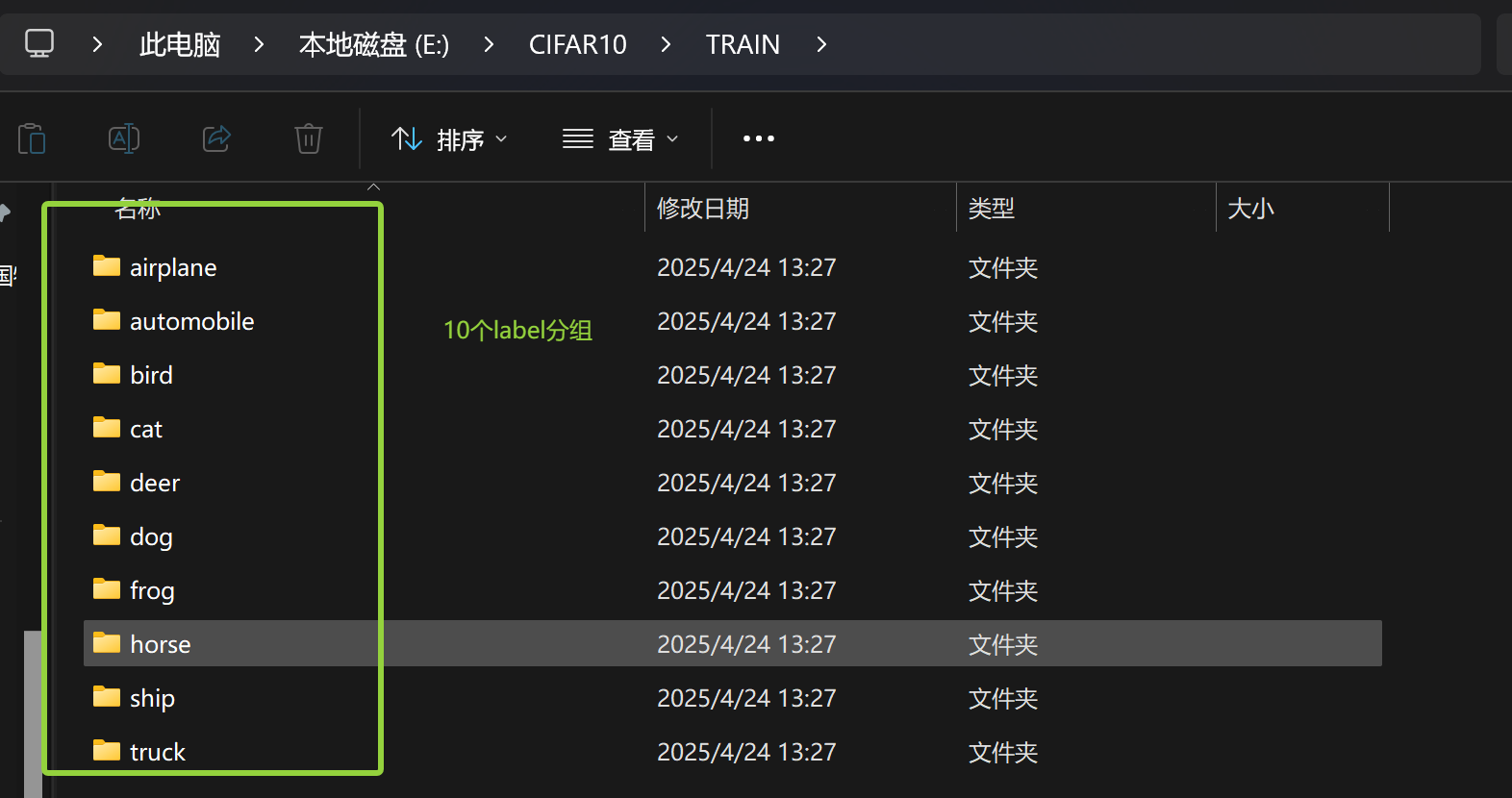
结果: TRAIN目录下出现了10个label分组
02写入数据
再在这些新创建出的空白文件夹内写入data数据集的数据,按分类写入不同的分类子文件夹中
代码:
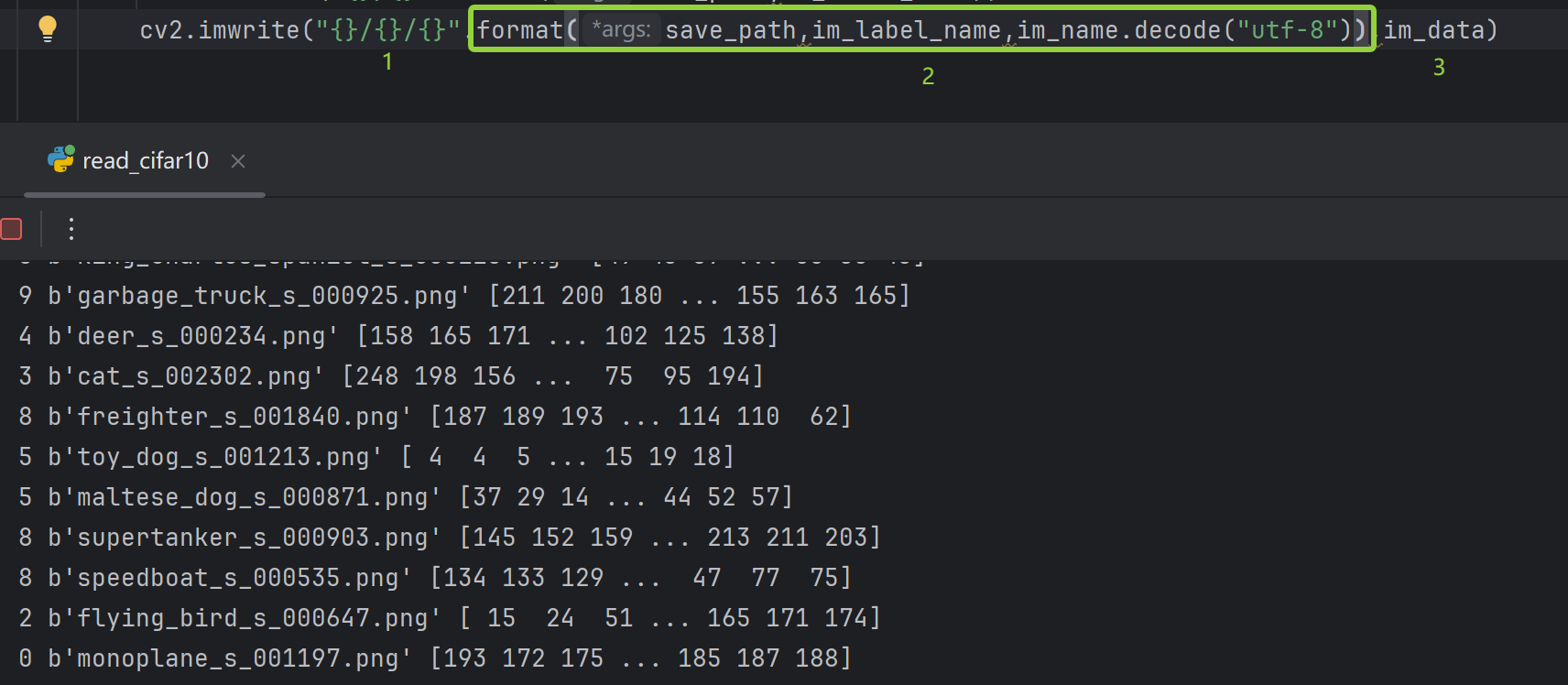
cv2.imwrite("{}/{}/{}".format(save_path,im_label_name,im_name.decode("utf-8")),im_data)
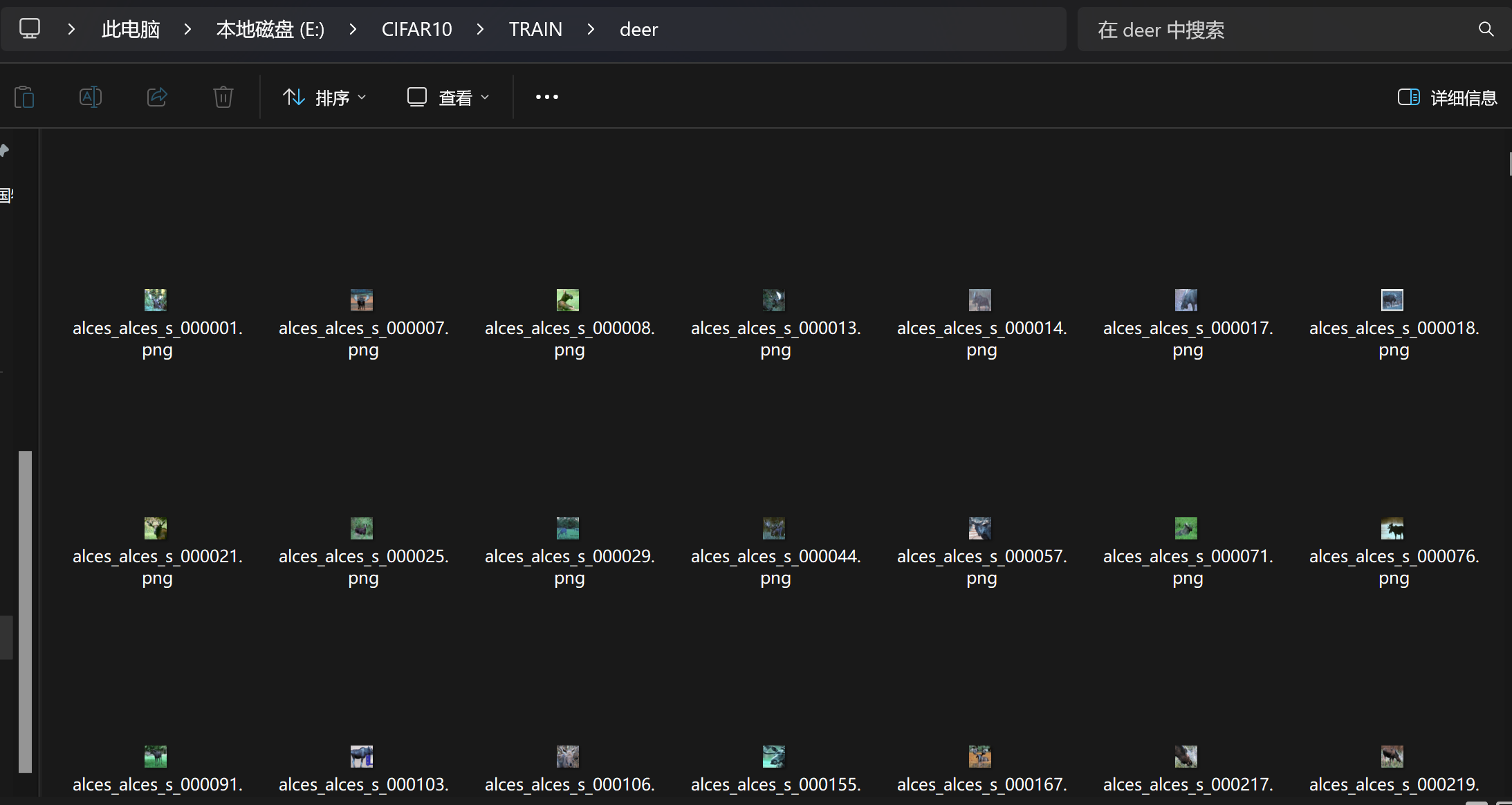
如下图所示,各个文件夹下已经分别存放了不同的数据集

测试集图片存储到TEST目录
上面的代码只需要改动两处 :
01将读取的路径从
train_list=glob.glob("E:/CIFAR10/train_batch_*")
改为
train_list=glob.glob("E:/CIFAR10/test_batch*")
因为数据集目录下,训练集的文件名统一为train_batch_*,测试集只有一个文件为test_batch,后面的*为模糊匹配,代表任意大小长度的字符串(可为空
)
02将保存路径从
save_path="E:/CIFAR10/TRAIN"
改为
save_path="E:/CIFAR10/TEST"
最后得到了TEST文件夹中的测试数据
同样是10个分类,一共10000张图片



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











