






本文不会讲解Redis的用途,关于用途会发另一片文章讲解,本文主要讲的是高可用的原理。
Redis高可用主要有以下三个原因:主从模式(上一篇讲Kafka的文章里有涉及到),哨兵模式,Redis-Cluster(Redis集群)。
什么是主从模式?
主从模式中,数据库分为两类,一类主数据库,一类从数据库,主数据库可以进行读写操作,从数据库只能进行读操作,当主数据库发生变化时会自动同步到从数据库上。这样可以实现读写分离和容灾恢复。
全量复制和增量复制
全量复制就是主从数据库第一次链接的时候进行数据同步,从库要复制主库的全部数据,所以叫全量复制,后面只需要同步新的数据,就是增量复制。
如果从库的实例过多,主库复制同步到子库就会有压力怎么办?
可以采用如下图所示的“主-从-从”模式来处理
当一个从库已经完成和主库的同步后,主库可以选择它来进行其他从库的同步。
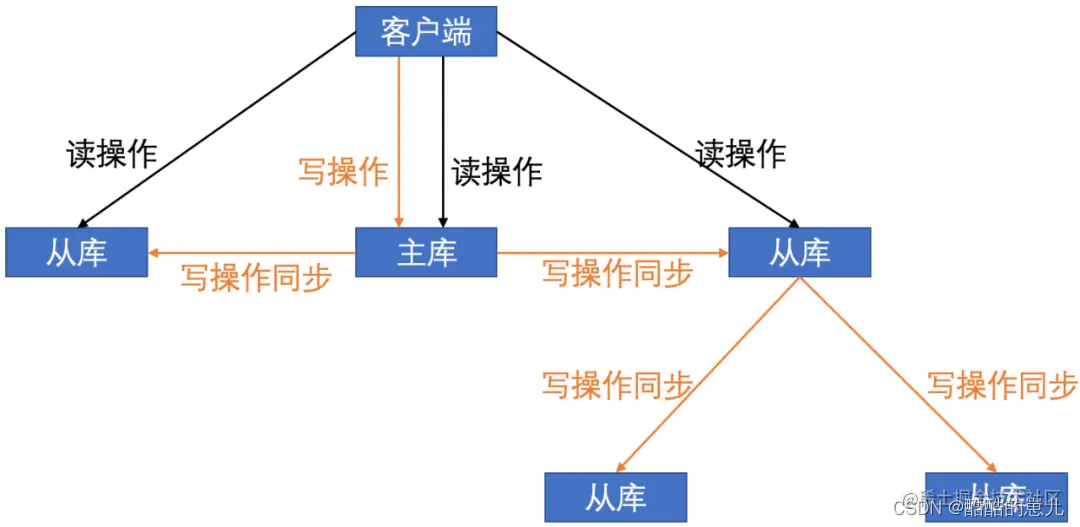
这样副本的一致性就得到了保障了。
那主库万一挂了怎么办呢?
这时候就要依靠哨兵模式,什么是哨兵模式?
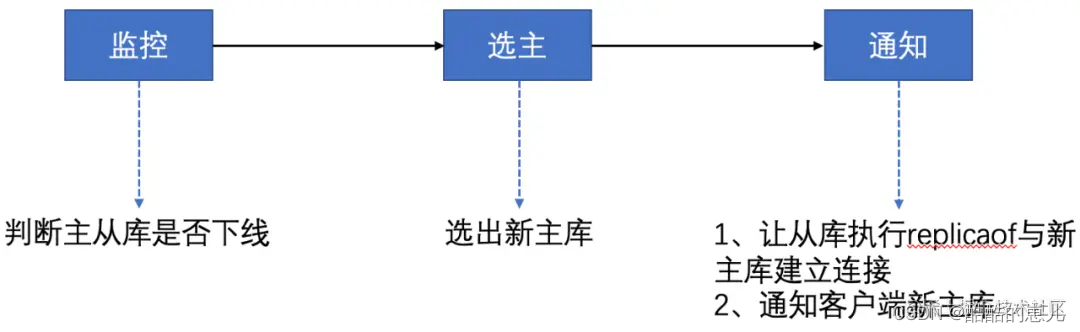
哨兵模式是实现主从库自动切换的关键机制,它主要负责三个任务:监控、选择主库、通知和完成主从切换操作。
-
监控。哨兵在运行时,周期性地给所有的主从库发送PING命令,检测是否仍在运行。如果从库没有响应哨兵的PING命令,哨兵就会将它标记为下线状态;如果主库没有在规定时间内响应哨兵的PING命令,哨兵也会判断主库下限,然后开始自动切换主库的流程。
-
选主。主库挂了之后,哨兵需要按照一定的规则选择一个从库,并将他作为新的主库。
-
通知和完成主从切换。选取了新的主库后,哨兵会把新主库的连接信息发给其他从库,让它们执行replicaof命令和新主库建立连接,并进行数据复制;同时哨兵也会将新主库的消息发给客户端。
不过这样也会有一个问题,哨兵判断主从库下限失误怎么办呢?
对于从库来说,影响不大,但是对主库来说就麻烦多了,这时候就要用到去中心化的思想,一个哨兵不行,那就多几个哨兵不就行了,做一个哨兵集群,当一个哨兵判断出主库下线,就引入多个哨兵实例进行判断,如果大多数都认为主库下线,主库就会标记为“客观下线”。(比如10个人,有过半数,也就是6个人同意就OK)。
那么主库下线后怎么选取新的主库?
这就要通过哨兵机制进行筛选和打分了。
-
筛选的要求。首先从库一定是正在运行的,还要判断从库之前的网络连接状态,如果总是断连并且超过了一定的阈值,哨兵会认为该从库的网络不好,也会将其筛掉。
-
打分的要求。哨兵机制根据三个规则依次进行打分:从库优先级、从库复制进度以及从库ID号;在某一轮有从库得分最高,那么它就是新的主库了,选主过程结束。如果该轮没有出现最高的,继续下一轮。
这样就可以选出新的主库了,那哪个哨兵来执行主从库切换呢?
这个流程和判断“客观下线类似”,也是一个投票的过程。
如果某个哨兵判断了主库为下线状态,就会给其他的哨兵实例发送is-master-down-by-addr的命令,其他实例会根据自己和主库的连接状态作出Y或N的响应,Y相当于赞成票,N为反对票。一个哨兵获得一定的票数后,就可以标记主库为“客观下线”,这个票数是由参数quorum设置的。如下图:
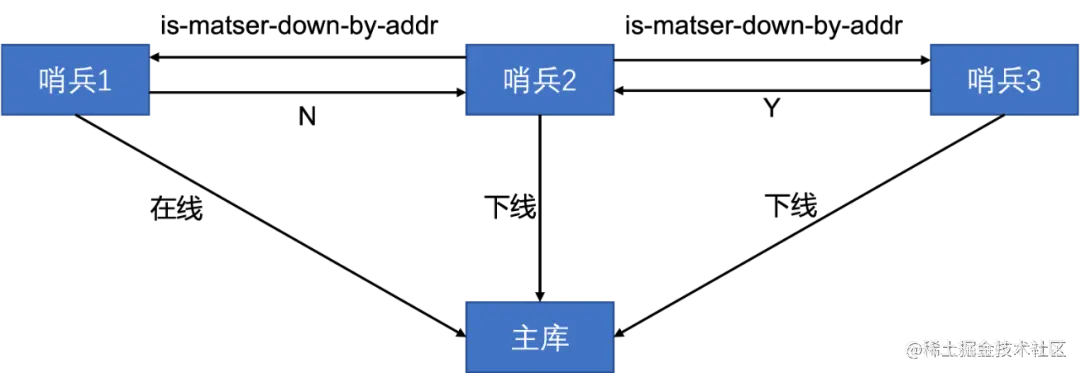
这个时候哨兵就可以给其他哨兵发送消息,表示希望自己来执行主从切换,并让所有的哨兵进行投票,这个过程称为“Leader选举”,进行主从切换的哨兵称为Leader。任何一个想成为Leader的哨兵都需要满足两个条件:
-
拿到半数以上的哨兵赞成票。
-
拿到的票数需要大于等于quorum的值。
然后就可以进行主从库切换啦。
那么当数据量过多的时候怎么处理呢,如果每个数据库都存着所有数据,每个副本都要存一份完整的数据,内存的开销就会很大,又该怎么处理呢?
Redis的切片集群可以解决这个问题,也就是启动多个Redis实例来组成一个集群,再按照一定的规则把数据划分为多份,每一份用一个实例来保存,这样客户端只需要访问对应的实例就可以获取数据。也就是Redis—Cluster架构了。
要实现这个架构面临两个主要问题:
-
数据切片后,在多个实例之间怎么分布?
-
客户端怎么确定想要访问的实例是哪一个?
Redis采用了Redis Cluster的方案来实现切片集群,具体的Redis Cluster采用了哈希槽(Hash Slot)来处理数据和实例之间的映射关系。在Redis Cluster中,一个切片集群共有16384个哈希槽(为什么Hash Slot的个数是16384),这些哈希槽类似于数据的分区,每个键值对都会根据自己的key被影射到一个哈希槽中,映射步骤如下:
-
根据键值对key,按照CRC16算法计算一个16bit的值。
-
用计算的值对16384取模,得到0~16383范围内的模数,每个模数对应一个哈希槽。
这时候可以得到一个key对应的哈希槽了,哈希槽又是如何找到对应的实例的呢?
在最开始客户端和集群实例建立连接后,实例就会把哈希槽的分配信息发给客户端,实例之间会把自己的哈希槽信息发给和它相连的实例,完成哈希槽的扩散。这样客户端访问任何一个实例的时候,都能获取所有的哈希槽信息。当客户端收到哈希槽的信息后会把哈希槽对应的信息缓存在本地,当客户端发送请求的时候,会先找到key对应的哈希槽,然后就可以给对应的实例发送请求了。
但是,哈希槽和实例的对应关系不是一成不变的,可能会存在新增或者删除的情况,这时候就需要重新分配哈希槽;也可能为了负载均衡,Redis需要把所有的实例重新分布。
虽然实例之间可以互相传递消息以获取最新的哈希槽分配信息,但是客户端无法感知这个变化,就会导致客户端访问的实例可能不是自己所需要的了。
Redis Cluster提供了重定向的机制,当客户端给实例发送数据读写操作的时候,如果这个实例上没有找到对应的数据,此时这个实例就会给客户端返回MOVED命令的相应结果,这个结果中包含了新实例的访问地址,此时客户端需要再给新实例发送操作命令以进行读写操作。(个人感觉这些Redis实例有点计算机网络中路由器的味道了,私底下通信,互相了解,客户端毫不知情,当去查询的时候找不到了,就类似DNS查询的味道了,开始迭代查询了,只能说计算机思想贯穿始终好吧,要多去理解和运用这些思想)
参考文章:
https://juejin.cn/post/7146465356482084878
https://juejin.cn/post/6963941240496717854?searchId=20240512211534A79024C96A5A6767CD62
https://juejin.cn/post/6936534060604850207?searchId=20240512211534A79024C96A5A6767CD62
本篇文章就到这里啦,非常感谢各位的阅读,喜欢的点个关注吧,下期更新锁的相关知识!















 1811
1811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









