






接上一篇博客:课设复习之信息论自适应算术编码与译码https://blog.csdn.net/hfuter2016212862/article/details/90522250
在随机理论中,把在某时刻的事件受在这之前事件的影响,其影响范围有限的随机过程,称为马尔可夫过程。一个事件受在它之前的事件的影响的深远程度,通常用在它之前的事件作为条件的概率来表达。受前一个事件的影响,简称为马尔可夫过程;受前两个事件的影响,称为二阶马尔可夫过程;受前三个事件的影响,称为三阶马尔可夫过程。
题目3:
设信源可能输出的符号是a, b, c 三个字母,构成一个二阶Markov信源,且各阶条件概率如下,试编写程序可以对任意字母序列(如abbcabcb)进行基于上下文的自适应算术编码,并进行相应的译码。
零阶条件概率:
p(a)=1/3; p(b)=1/3; p(c)=1/3;
一阶条件概率:
p(a/a)=1/2; p(b/a )=1/4; p(c/a)=1/4;
p(a/b)=1/4; p(b/b)=1/2; p(c/b)=1/4;
p(a/c)=1/4; p(b/c)=1/4; p(c/c)=1/2;
二阶条件概率:
p(a/aa)=3/5; p(b/aa)=1/5; p(c/aa)=1/5;
p(a/ab)=1/4; p(b/ab)=1/4; p(c/ab)=1/2;
p(a/ac)=1/4; p(b/ac)=1/4; p(c/a2)=1/2;
p(a/ba)=1/2; p(b/ba)=1/4; p(c/ba)=1/4;
p(a/bb)=1/5; p(b/bb)=3/5; p(c/bb)=1/5;
p(a/bc)=1/4; p(b/bc)=1/4; p(c/bc)=1/2;
p(a/ca)=1/2; p(b/ca)=1/4; p(c/ca)=1/4;
p(a/cb)=1/2; p(b/cb)=1/4; p(c/cb)=1/4;
p(a/cc)=1/5; p(b/cc)=1/5; p(c/cc)=3/5;
理论上仍应该采用分组方法解决,精度问题仍存在,课设时未要求此题目分组,有兴趣的读者可以参考上篇博客试试。
自适应算术编码与译码:
全局变量如下:
#include<iostream.h>
#include<iomanip.h>
#include<math.h>
#include<string.h>
double proc1[3]={1.0/3,1.0/3,1.0/3};
double proc2[3][3]={1.0/2,1.0/4,1.0/4,
1.0/4,1.0/2,1.0/4,
1.0/4,1.0/4,1.0/2};
double proc3[3][3][3]={3.0/5,1.0/5,1.0/5,
1.0/4,1.0/4,1.0/2,
1.0/4,1.0/4,1.0/2,
1.0/2,1.0/4,1.0/4,
1.0/5,3.0/5,1.0/5,
1.0/4,1.0/4,1.0/2,
1.0/2,1.0/4,1.0/4,
1.0/2,1.0/4,1.0/4,
1.0/5,1.0/5,3.0/5};//概率
double result,length=1,interval_begin=0,interval_end=1;//译码所选取的数
int cord[1000],dcord[1000],cordlength;//编码、译码及长度
char str[1000];//输入符号字符串
int strlength=0;读取数据代码如下:
bool readdata(){
cout<<"***********基于上下文自适应算术编码***********"<<endl;
cout<<"请输入字符串(a-c):"<<endl;
cin>>str;
strlength=strlen(str);
for(int i=0;i<strlength;i++)
if(str[i]>'c'||str[i]<'a')
return 1;
return 0;
}自适应算术编码:
void encode(){
cout<<"编码:"<<endl;
int i,j,n1,n2,n3;
for(i=0;i<strlength;i++){
if(i==0){
n1=str[0]-'a';
for(j=0;j<n1;j++)
interval_begin+=proc1[j]*length;
interval_end=interval_begin+proc1[n1]*length;
}
if(i==1){
n2=str[1]-'a';
for(j=0;j<n2;j++)
interval_begin+=proc2[n1][j]*length;
interval_end=interval_begin+proc2[n1][n2]*length;
}
if(i>=2){
n1=str[i-2]-'a';
n2=str[i-1]-'a';
n3=str[i]-'a';
for(j=0;j<n3;j++)
interval_begin+=proc3[n1][n2][j]*length;
interval_end=interval_begin+proc3[n1][n2][n3]*length;
}
length=interval_end-interval_begin;
}
result=interval_begin*0.01+interval_end*0.99;
cordlength=int(log(1.0/length)/log(2))+1;
cout<<"编码选取的数为:"<<setprecision(16)<<result<<endl;
cout<<"编码位数为:"<<cordlength<<endl;
double temp;
for(i=0;i<cordlength;i++){
temp=result*2;
cord[i]=(int)temp;
result=temp-cord[i];
}
cout<<"输出符号编码为:";
for(i=0;i<cordlength;i++)
cout<<cord[i];
cout<<endl;
}自适应算术译码:
void decode(){
cout<<"译码:"<<endl;
result=0;
double a=1;
int i,j,k=0,l=0;
for(i=0;i<cordlength;i++){
for(j=0;j<=i;j++)
a=a*2;
result=result+cord[i]/a;
a=1;
}
cout<<"译码选取的数为:"<<setprecision(16)<<result<<endl;
length=1;
interval_begin=0;
for(i=0;i<strlength;i++){
if(i==0){
a=proc1[0]*length;
while((result-interval_begin)>a){
k++;
a=a+proc1[k]*length;
}
dcord[i]=k;
str[i]=k+'a';
interval_begin+=a-proc1[k]*length;
length=length*proc1[k];
}
if(i==1){
a=proc2[dcord[0]][0]*length;
while((result-interval_begin)>a){
k++;
a=a+proc2[dcord[0]][k]*length;
}
dcord[i]=k;
str[i]=k+'a';
interval_begin+=a-proc2[dcord[0]][k]*length;
length=length*proc2[dcord[0]][k];
}
if(i>=2){
a=proc3[dcord[i-2]][dcord[i-1]][0]*length;
while((result-interval_begin)>a){
k++;
a=a+proc3[dcord[i-2]][dcord[i-1]][k]*length;
}
dcord[i]=k;
str[i]=k+'a';
interval_begin+=a-proc3[dcord[i-2]][dcord[i-1]][k]*length;
length=length*proc3[dcord[i-2]][dcord[i-1]][k];
}
k=0;
}
cout<<"译码结果为:";
for(i=0;i<strlength;i++)
cout<<char(dcord[i]+97);
cout<<endl;
}调用主函数如下:
void main() {
if(readdata())
cout<<"字符输入错误!"<<endl;
else{
encode();
decode();
}
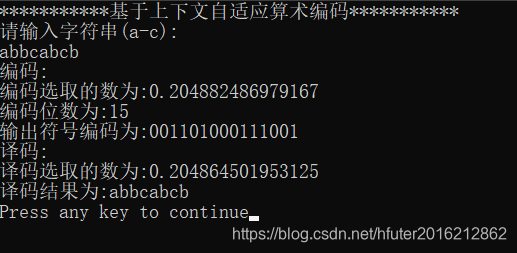
} 结果如下:

















 1717
1717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









