






 文章详细描述了北京航空航天大学计算机学院学生在面向对象设计课程中的三次作业,从代码UML类图、依赖图到代码结构分析,重点在于表达式展开、指数函数解析、自定义函数处理、求导计算以及代码优化,探讨了递归下降算法的应用和代码复杂度控制。
文章详细描述了北京航空航天大学计算机学院学生在面向对象设计课程中的三次作业,从代码UML类图、依赖图到代码结构分析,重点在于表达式展开、指数函数解析、自定义函数处理、求导计算以及代码优化,探讨了递归下降算法的应用和代码复杂度控制。
北京航空航天大学-计算机学院-面向对象设计与构造-第一单元
文章目录
前言
第一单元的主题是表达式展开。学习目标聚焦于模块化设计。
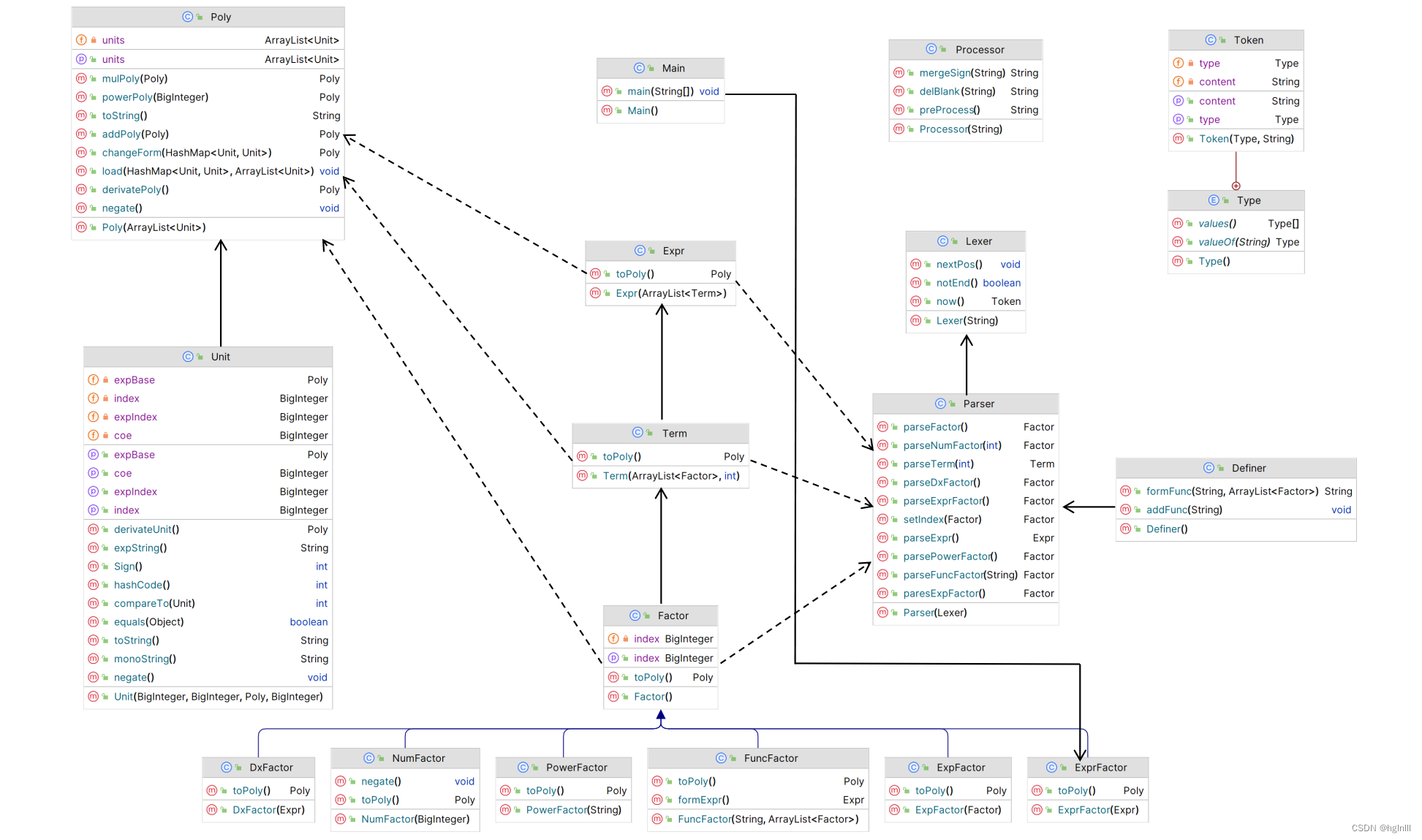
最终UML类图
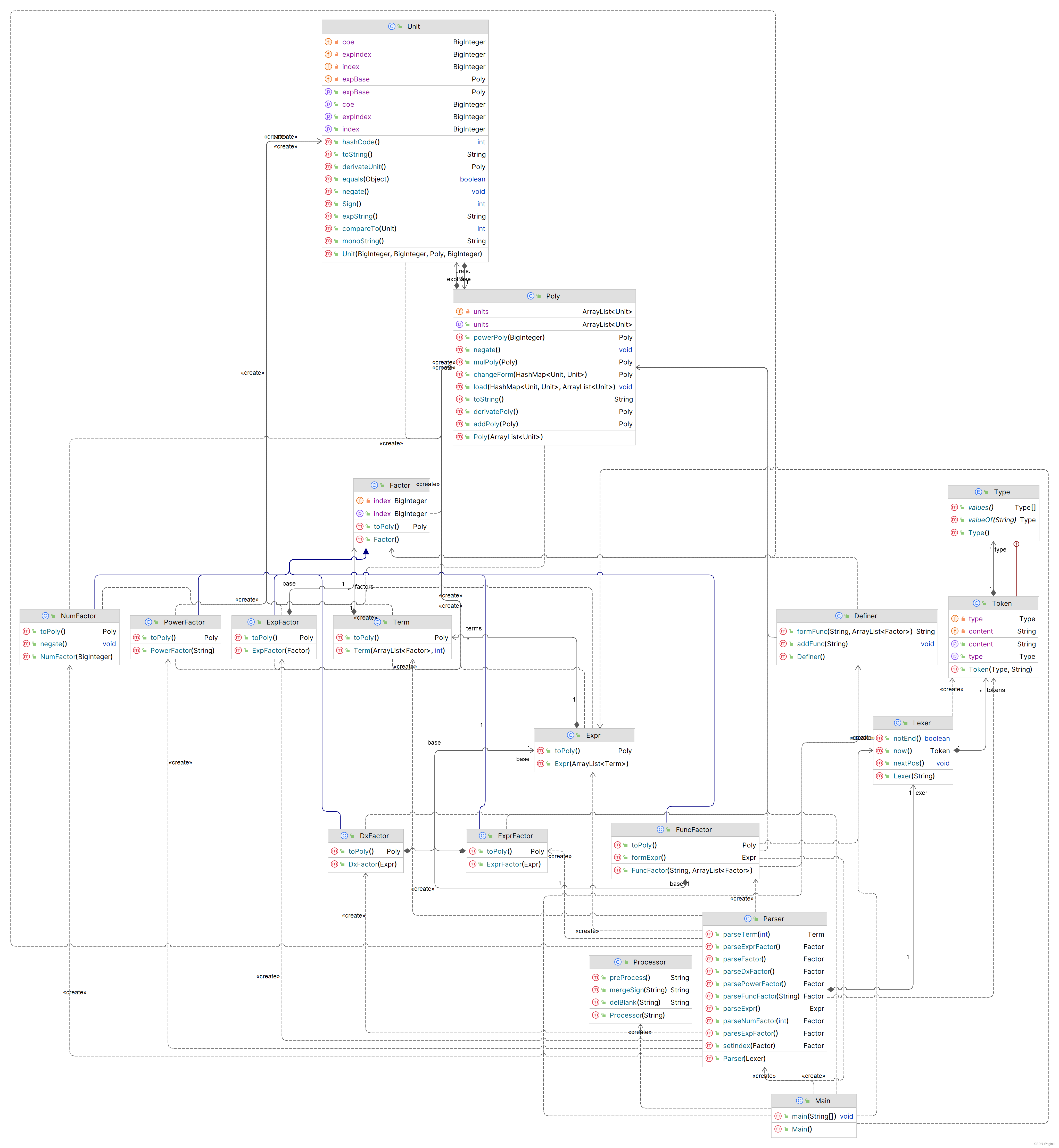
最终UML依赖图
最终代码规模图

如图,三次迭代后最终程序有
- 17 个
.java文件 - 代码总长 823 行
- 文件中的最小行数为12(表达式因子类)
- 文件中的最大行数为197(最小单元类,因为优化输出长度进行了大量
if-else判断 QAQ) - 文件的平均行数为48
下面分享一下每次作业的设计思路~
一、第一次作业分析
第一次作业主要是关于单变量多项式的括号展开
1.代码UML类图

2.代码架构分析
仔细阅读教程,经过一定的思考分析,我们将表达式解析为三层——表达式-Expr,项-Term,因子-Factor。其中根据需求,将Factor分为三种——变量因子(幂函数)-PowerFactor,常数因子-NumFactor,表达式因子-ExprFactor。这里考虑到各种因子可能拥有各自的幂指数index,运用了继承。其中Expr类中使用Arrylist来容纳表达式中含有的项,Term类中使用Arrylist来容纳项中含有的因子。
a、表达式预处理
我们设置了表达式处理类Processor,预处理包括
i)输入的表达式中空白字符删去
ii)将连续的+-号合并为一个+或-
b、表达式解析
对第一次作业的表达式解析至少有两种方案,一种是利用正则表达式,另一组是利用课程组传授的递归下降算法。我们采用了老师和助教推荐的后者。
递归下降算法的详细思想可见OO加油站。主要包含两个部分——词法分析器-Lexer和解析器-Paser。
Lexer
将表达式分解为一系列语法单元(Token类)
第一次作业的基本语法单元有:加ADD, SUB, MUL, 乘方-POWER, LPAREN, RPAREN, VAR,NUM。我们考虑用枚举类型来记录。
可以直接用循环对字符串进行遍历,将解析出的语法单元放入tokens中。
Paser
依靠Lexer分解的tokens递归生成表达式、项和因子
我们将表达式的解析分为三层——parseExpr,parseTerm,parseFactor,每一部分的解析都遵循形式化文法。
parseExpr:考虑到第一项可能带有符号,进行特殊处理。解析完第一项后直接用循环进行ADDorSUB 与 parseTerm的解析(这里解析项实际上就是调用一次parseTerm)。
parseTerm:同理。ADDorSUB 变为 MUL
parseFactor:对三种不同因子进行条件判断并解析。
c、表达式展开
单变量表达式的展开实际上是关于x的多项式。我们考虑引入多项式类-Poly和单项式类-Mono。
Mono:含有两个成员变量——系数-coe和指数-index。这里我们都采用了BigInteger(似乎index并不需要)。
Poly:有容纳一系列单项式的容器和各种多项式的运算方法(如多项式的加、乘、乘方),以及形成字符串的方法toString()。
自然地,我们对Expr,Term,Factor类中都引入转换为表达式-toPoly(...)方法,分别利用表达式的运算进行转换(这里要考虑因子或项的符号问题,可以把符号下发给因子或者集合到项中)。
3.优化
- 单项式的系数为
0,结果为0 - 单项式的系数为
1或-1,可以省略系数 - 单项式的指数为
0,只输出系数 - 单项式的指数为
1,可以省略指数 - 找到多项式为正的那一项并移到首位(否则多一个负号)
4.代码复杂度分析
Method Metrics
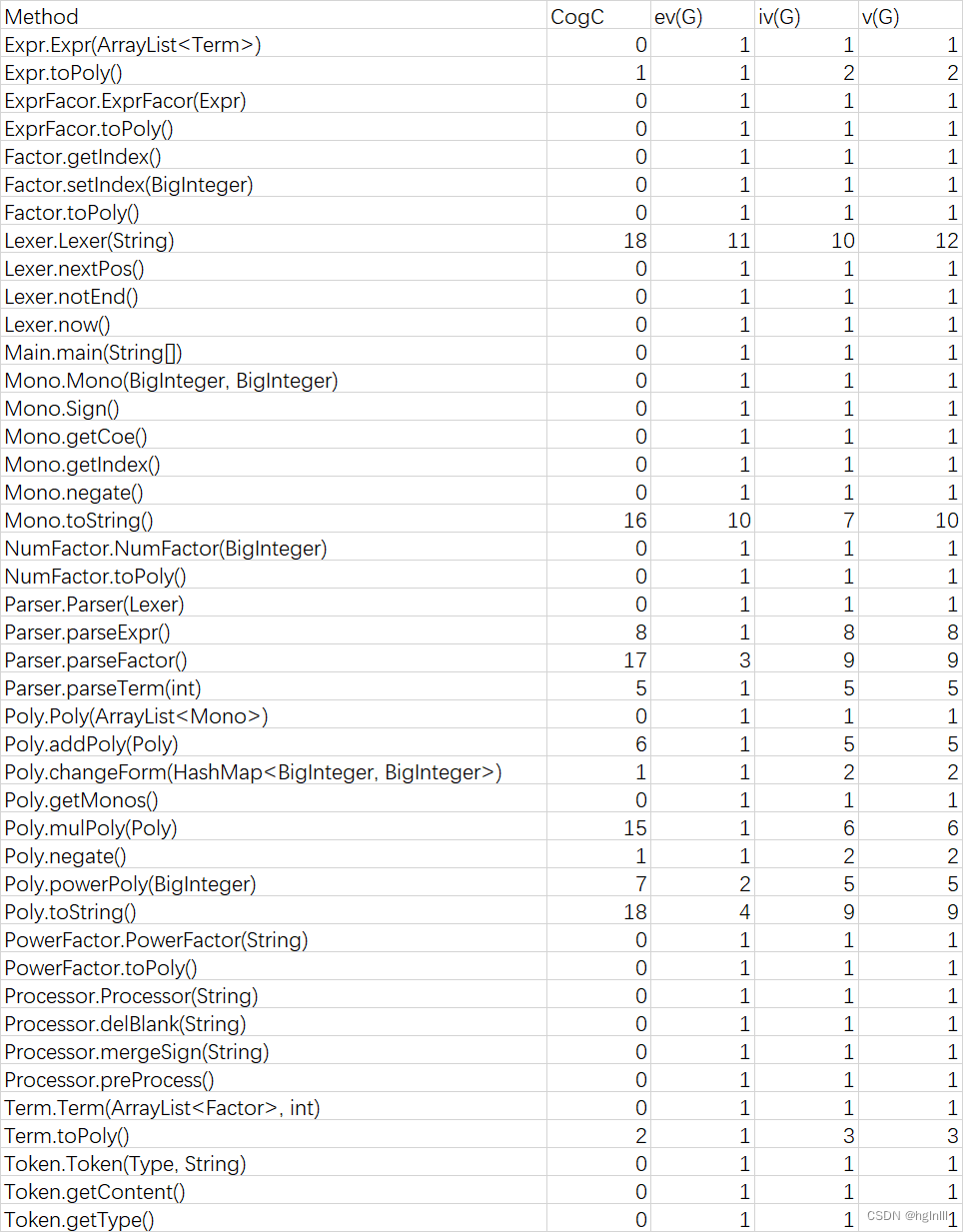
Lexer类中的构造方法使用了大量if-else语句对表达式语法单元进行解析Lexer类中的toString()方法使用了大量if-else语句特判进行优化Parser类中的parseFactor()方法先对因子进行了判断,再解析Poly类中的toString()方法进行了输出优化
二、第二次作业分析
第二次作业在第一次作业的基础上新增了指数函数因子和自定义函数因子,允许括号嵌套,且自定义函数调用时实参可以使用自己或其他的函数。
1.代码UML类图

2.代码架构分析
第二次作业我们延续递归下降算法,自然实现了括号嵌套。需要增加新的语法单元(如EXP,FUNC,COMMA(逗号))
a.指数函数解析
我们新建ExpFactor类,该类拥有两个属性——Factor base-表示指数函数括号内的因子,以及继承父类的index。
同时,我们在Parser类中新增paresExpFactor()方法。当parseFactor()中解析到当前因子为exp时,调用此方法解析指数函数。
//Paser.java
public Factor paresExpFactor() {
//向后解析
ExpFactor expFactor = new ExpFactor(parseFactor());
//向后解析
return setIndex(expFactor); //确定幂指数index
}
b.自定义函数的解析
我们新建FuncFactor类,该类拥有三个属性——String actualFunc-自定义函数实参替换形参后的结果,Expr base-解析成表达式后的结果,以及继承父类的index。
此外,我们可以新建一个工具类来实现自定义函数的定义和解析。
工具类
- 该类具有两个属性
//工具类
private static final HashMap<String, String> funcMap = new HashMap<>(); //函数名-函数定义式
private static final HashMap<String, ArrayList<String>> paraMap = new HashMap<>(); //函数名-函数形参表
- 具有两个方法
//工具类
public static void addFunc(String input) {...}; //将函数定义式和形参加入属性
public static String formFunc(String funcName, ArrayList<Factor> actualParas) {...}; //形参替换成实参
我们还是在Parser类处理自定义函数(也有的方法是在预处理时就将形参替换为实参)。Parser类中新增paresFuncFactor()方法。当parseFactor()中解析到当前因子为自定义函数时,调用此方法解析指数函数。
//Parser.java
public Factor parseFuncFactor(String funcName) {
//...
ArrayList<Factor> actualParas = new ArrayList<>();
while (lexer.now().getType() != Token.Type.RPAREN) {
//跳过左括号、逗号
actualParas.add(parseFactor());
}
//...
return new FuncFactor(funcName, actualParas);
}
我们先把函数名和参数解析出来,然后在FuncFactor类中调用Parser类的方法完成解析
//FuncFactor.java
public Expr formExpr() {
Lexer lexer = new Lexer(actualFunc);
Parser parser = new Parser(lexer);
return parser.parseExpr();
}
tips:
常数因子可能带有符号,解析时要注意~
c.表达式展开
第二次作业中多项式的最小单元不再是单项式,我们考虑将之前的Mono类重构为Unit类(IDEA重构功能十分好用)。形如:
a
x
n
(
e
<
e
x
p
r
>
)
b
ax^n(e^{<expr>})^b
axn(e<expr>)b
利用此,我们可以构造Unit类的属性。
合并同类项
我们需要重写之前多项式中的加、乘、乘方方法。其中我们需要实现合并同类项的功能。
对于Hashmap的value-Unit我们可以以Unit为key;也可以以x的幂指数为key,以另一个Hashmap为value,后者以指数函数括号内的表达式为key(这里可以是表达式的字符串形式(需要一定的次序)),最终value-Unit。
接着我们改写equals()和hashCode()方法(这两个方法一定要配套改写,保证相等时具有相同的hash值。hash也决定了hash表的查找性能)
3.代码复杂度分析
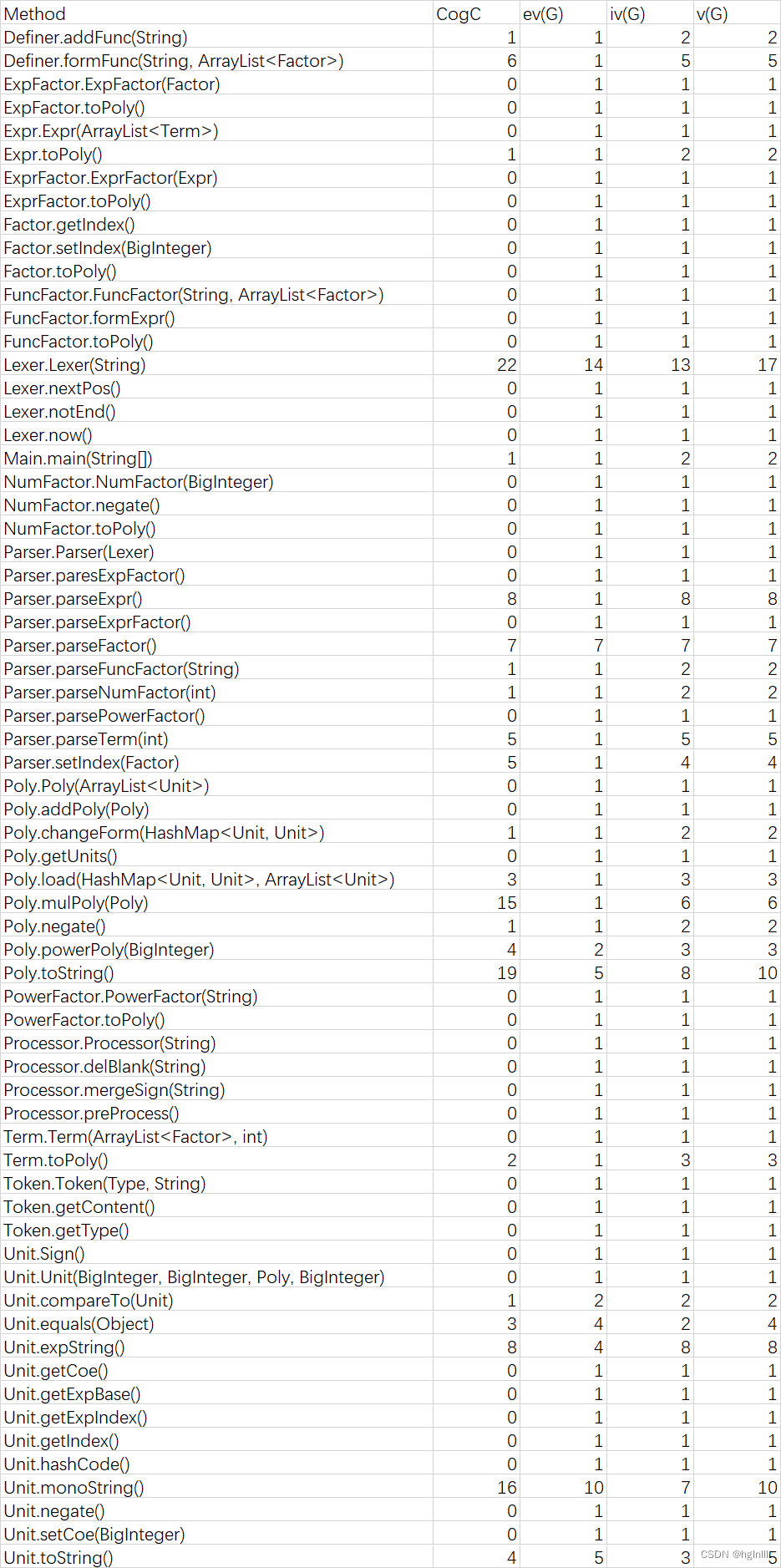
Lexer类中的构造方法使用了大量if-else语句对表达式语法单元进行解析Poly类中的toString()方法进行了输出优化
三、第三次作业分析
第三次作业在之前的基础上增加了求导因子,且函数表达式中支持调用其他已定义的函数。
1.代码UML类图

2.代码架构分析
第三次作业我们延续递归下降算法和第二次作业中对自定义函数的处理,自然实现了自定义函数表达式中调用其他函数的功能。需要增加新的因子-求导因子
a.求导因子解析
我们新建DxFactor类,该类拥有两个属性——Expr base-表示需要求导的表达式,以及继承父类的index。
同时,我们在Parser类中新增paresDxFactor()方法。当parseFactor()中解析到当前因子为dx时,调用此方法解析指数函数。
b.求导计算
这里对表达式的求导不限于两种方法
- 先化简,再求导,即对求导因子内表达式先调用
toPoly()方法化简为许多 c o e ⋅ x n ⋅ e e x p r coe·x^n·e^{expr} coe⋅xn⋅eexpr 和的形式,利用公式化的方法
( c o e ⋅ x n ⋅ e e x p r ) ′ = c o e ⋅ n ⋅ x n − 1 ⋅ e e x p r + c o e ⋅ x n ⋅ e e x p r ⋅ ( e x p r ) ′ (coe·x^n·e^{expr})'=coe·n·x^{n-1}·e^{expr}+coe·x^n·e^{expr}·(expr)' (coe⋅xn⋅eexpr)′=coe⋅n⋅xn−1⋅eexpr+coe⋅xn⋅eexpr⋅(expr)′
转化为每一个Unit的求导。当然可以分情况讨论(如coe,coe·x^n,coe·exp(expr)直接借助求导公式节约计算量) - 递归求导,即在
Expr,Term以及Factor的各个子类中都实现一个toDerivative()方法,且均返回Poly类型的对象。- 表达式求导是各个项求导的和
- 项求导是因子求导的乘积+求导的乘法法则
- 各个因子分别对应各种求导公式(如常数求导为
0)。表达式因子的求导再递归回去。需要注意,若因子为求导因子,即对表达式求二阶导,我们应当先求内层的导数,然后再求外层的导数。这可能涉及Poly类的转换为字符串再重走词法解析流程。
我们这里采取了第一种方案。
// Poly.java
public Poly derivatePoly() {
ArrayList<Unit> unitsDx = new ArrayList<>();
for (Unit unit : units) {
// ...
}
return new Poly(unitsDx);
}
// Unit.java
public Poly derivateUnit() {
ArrayList<Unit> units = new ArrayList<>();
if (coe.equals(BigInteger.ZERO)
|| (index.equals(BigInteger.ZERO) && expBase.getUnits().isEmpty())) {
// ...
}
if (expBase.getUnits().isEmpty()) {
// ...
}
if (index.equals(BigInteger.ZERO)) {
// ...
}
// ...
}
3.优化
这里主要讨论提取公因数以减小长度的问题
因为指数函数
e
x
e^x
ex 具有独特的数学性质:
(
e
x
)
a
=
e
a
x
(e^x)^a = e^{ax}
(ex)a=eax
而正确性判定中并没有对该处加以限制,所以我们在本次作业输出结果的有效长度中可能且不仅限于考虑:当指数函数exp(<因子>)中的因子是表达式因子时是否需要找到系数中合适的公因子并提出,转换为exp(<因子>)^a的形式。
稍微思考后我们发现,很难有一个统一的方案去处理这里的性能。这里我们采取提取最大公因数的方式。即借用BigInteger自带的gcd方法来寻找最大公因数并提取。(盲目提取最大公因数不是最佳的优化方式~)
4.代码复杂度分析
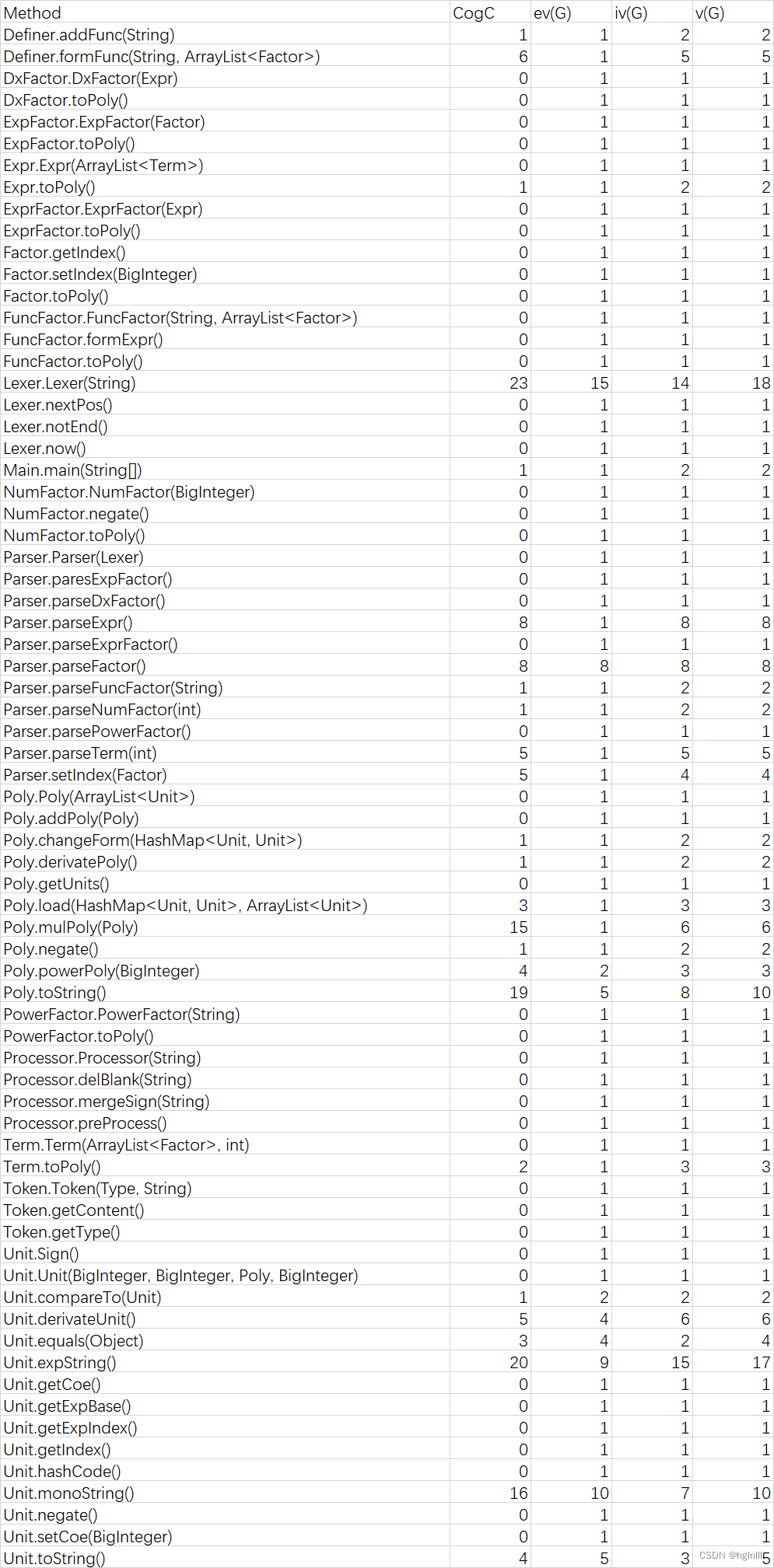
Lexer类中的构造方法使用了大量if-else语句对表达式语法单元进行解析Parser类中的parseFactor方法使用了大量if-else语句区分不同的表达式因子- 优化输出长度时需要大量判断
总结
新的迭代?
参考了外界学长学姐的博客,本届第一单元作业更加人性化些。如果在之前程序的基础上继续进行迭代,加入求和函数、三角函数等因子,可以延续之前的做法在Factor类后进行继承,Parser类加入解析方法,思想是一致的。难点可能聚焦于优化。而这里的优化目前思路就是不断的if-else判断,而这样会增加程序复杂度。希望能探索更好的方法~
BUG小结
三次作业很幸运通过都通过了强测、互测。这很大程度上归功于好的架构和评测机的检测。
- 第二次作业曾遇到解析常数因子未解析符号。第一次作业因为把符号提出去了,没有影响。第二次作业常数因子作为实参就不能避免这个问题了,加个符号判断就好
- 第三次作业在优化-提取公因数时因为深浅拷贝出了 bug
浅谈HACK
互测给予我们搭建评测机的动力,让我们有机会读取别人代码参考他们的架构,同时让别人帮我们找 bug(虽然会失分)。希望能在互测中成长~
和别人交流能收获许多好的测试点,这里浅浅列举几个~
(((((((((((x^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8 // 一个来自强测的程序性能测试
dx(exp(exp(exp(exp(exp(exp(exp(exp(x^2))))))))) // 程序性能测试
exp((-x)) // 正确性测试——不能去括号~
3
g(z)=exp(exp(exp(exp(z))))
f(y)=exp(exp(exp(exp(g(y)))))
h(x)=exp(exp(exp(exp(f(x)))))
h(f(g(exp(exp(exp(exp(x^8)))))))
// emm~
心得体会
第一单元作业将递归这一思想的魅力体现得淋漓尽致,掌握好的设计能力,体会java编程的原理,看着如此复杂的表达式被一点点拆分处理,最终合并化简,觉得蛮奇妙呢~
未来方向
可以引入程序性能的指导,很多 hack 都去针对程序性能过低而超时,这样的 bug 又很难修复(室友 hw2 因为这个而气得熬了好久~)















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









