






前言
本文是Web数据可视化案例系列文章的第二篇。文章中介绍的项目是一个完整可运行的可视化项目。前台使用json对象展示数据表的数据,并且使用javascript绘制svg图像将数据可视化。后台使用python的pandas库进行数据处理,先将数据从数据库中多个历史表中查询出来,再把数据组织成前台需要的json结构,然后通过Bottle这个极其轻便、能够快速上手的Web框架将json数据传递给前台。
目标读者
如果你想学习数据处理和分析,那么本文是为你准备的。本文将使用既容易理解,数据处理又相对简单的案例,带领你了解使用pandas进行数据处理的过程,以及如何选择数据展现模型进行数据可视化。
如果你想了解和学习Web前台开发的相关技能,并且想熟练使用复杂的数据可视化方法,那么本文不要错过。
如果你想学习python,想掌握Web后台技能,并搭建一个Web开发框架。那么本文也非常适合你。本文将搭建一个轻便极易上手的,以python为开发语言的Bottle框架,该框架非常适合快速验证原型设计效果。
简而言之,本文适合想入门大数据处理和数据可视化,想使用python快速开发Web应用的读者。
正文
本项目主要目标是展示工厂制造成本的环比数据趋势。主要使用使用svg绘制图表来显示这个数据趋势。
我们在上一篇文章介绍了使用Echarts进行数据可视化的方法。Echarts是非常强大的可视化工具,并且具有丰富多样的展示模板。条条大路通罗马。我们这次使用svg图表来展示数据,就是为了给大家更多的选择。Echarts和svg是两种不同的可视化方案,我们通过下面的表格来比较他们的异同,迅速了解一下他们之间的区别。因为Echarts实际上就是使用Canvas画布实现的,下表中的Canvas你可以把他看作Echarts。
| 可扩展性 |
|
|
| 渲染能力 |
|
|
| 灵活度 | SVG 可以通过JavaScript和CSS 进行修改,用SVG来创建动画和制作特效非常方便。 | Canvas只能通过JavaScript进行修改,创建动画得一帧帧重绘。 |
| 使用场景 | SVG 非常适合显示矢量徽标(Logo)、图标(ICON)和其他几何设计。 | Canvas 主要用于游戏开发、绘制图形、复杂照片的合成,以及对图片进行像素级别的操作,如:取色器、复古照片。[1] |
当前有一组历史数据表。数据表的内容是某城市下辖的每个工厂的成本和产值,每个数据表是某一年中的某一季度的数据。下图是2018年第一季度的数据截图,数据表在数据库中名称为“pv2018q1”。
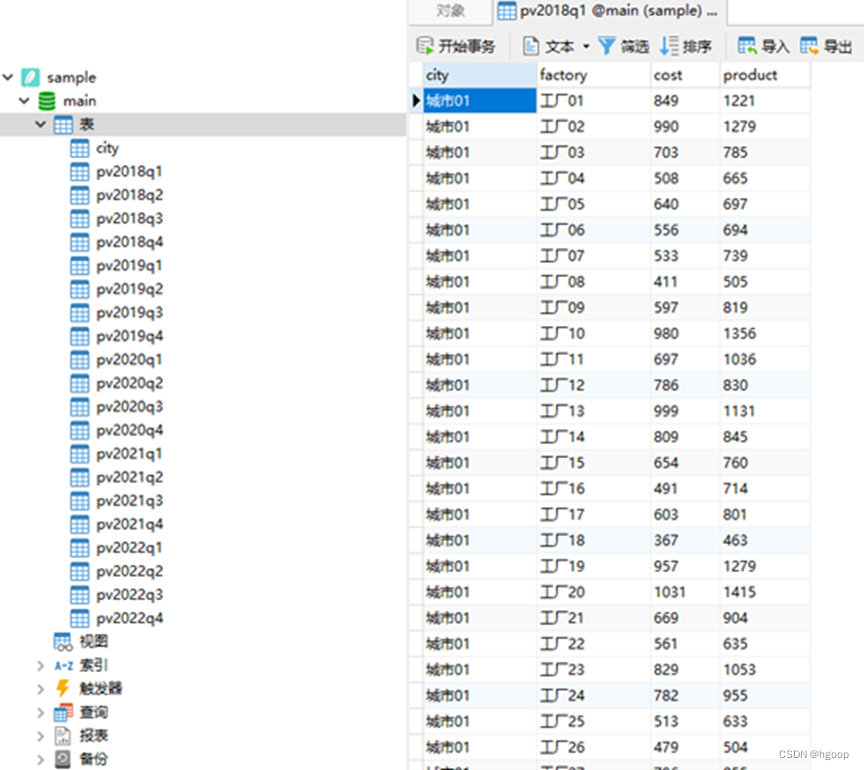
从上图可以看出,这组历史表一共有20个,共5年的数据。
现在我们需要把这些历史数据表的所有数据,按照城市和工厂名称整理出来,并且对应到某一季度的成本和产值数据。这些数据最终通过前台展示出来并且使用svg图表将数据可视化。
我们为了快速应用和方便上手,简化了数据构造过程(每个季度的数据表内的城市和工厂类目都是相同的,所有成本和产值数据没有空值、异常值),所以后续代码省略了数据清洗的过程。而实际应用场景中,可能会有工厂关闭,新建工厂,或者工厂停工等情况导致数据表中数据缺失或者增加的情况,从而必须对数据进行清洗操作。
回到这个项目,我们实现这一需求的思路是:先将所有数据都归集起来,使用城市和工厂名称作为主键,然后将每个季度的成本和产值数据作为列数据将他们联系起来。我们将生成一个一共有41列数据的数据表。第一列是城市工厂名称,后面40列是20个季度的成本和产值数据。
你会如何组织这个大数据表呢?
常见的方法是这样的:首先将一个数据表的数据查询出来存入Dataframe,然后将第二个数据表的数据按照城市和工厂的名称合并到第一个表,接下来依次类推,将所有表的数据都查询出来合并到保存结果的Dataframe中。
这种方式有一个问题就是需要通过数据库中的表名来访问每个季度数据。我们为了提升数据的批量处理效率,使用一个相对巧妙的方式直接使用pandas提供的合并功能来组织数据。
下面我们将直接进入项目后台代码的编写工作,如果你不清楚如何从零开始搭建项目,请参考本系列文章的第一篇相关内容。
我们实现上面讨论的功能只使用了二十行代码,下面分别解释重点代码的功能。
def getCqData():
engine = create_engine(dbfile)
sql_cmd = '''select 'select "'||name||'" as id, city||factory as name,cost,product from '||name||' ' FROM sqlite_master where name like 'pv%' order by name'''
conn = engine.connect()
res = conn.execute(text(sql_cmd))
sql_alldata = ' union '.join([str(row[0]) for row in res.fetchall()])
res.close()
df_a = pd.read_sql(sql_alldata,conn)
unique_ids = sorted(df_a['id'].unique())
df_res = pd.DataFrame(columns=['name','cost','product'])
first = True
for id_val in unique_ids:
group = df_a[df_a['id'] == id_val]
group.rename(columns={'cost':id_val+'_cost','product':id_val+'_product'},inplace=True)
group.drop('id',axis=1,inplace=True)
if first:
first=False
df_res = group.copy()
else:
df_res = pd.merge(df_res,group,on='name', how='left')
这段代码中第一个重要的部分是拼装数据查询语句。
sql_cmd = '''select 'select "'||name||'" as id, city||factory as name,cost,product from '||name||' ' FROM sqlite_master where name like 'pv%' order by name'''这个语句的作用是在sqlite数据库中查询出所有的季度数据表名称,这里使用的条件是name like 'pv%',然后将查询出来的季度数据表名拼装成一条sql语句,该sql语句将城市名称和工厂名称合并,然后查询出成本和产值数据。根据我们前面介绍的数据表的情况,这条语句查询结果一共是20条sql语句,这一条条的sql语句将为后面生成一张大数据表做准备。
sql_alldata = ' union '.join([str(row[0]) for row in res.fetchall()])这条语句将上面查询出来的20条sql语句拼装成了一条sql语句,使用union将所有季度的数据合并成一张竖表,这个sql语句的查询结果保存在类型为DataFrame的df_a中。
因为我们需要的是一张横着的大表,即工厂名称为索引,每个季度的成本和产值为列的数据表。下面就使用pandas提供Dataframe merge操作实现这个功能。
unique_ids = sorted(df_a['id'].unique()) 这条语句,将所有作为id的表名整理出来为下面循环提取数据做好准备。
df_res = pd.DataFrame(columns=['name','cost','product'])
first = True
for id_val in unique_ids:
group = df_a[df_a['id'] == id_val]
group.rename(columns={'cost':id_val+'_cost','product':id_val+'_product'},inplace=True)
group.drop('id',axis=1,inplace=True)
if first:
first=False
df_res = group.copy()
else:
df_res = pd.merge(df_res,group,on='name', how='left')
这是第二个重要的部分。这段代码按照id将不同季度数据表的数据从df_a中提取出来,然后使用merge方法合并到结果df_res中去,随着循环的执行,结果表的列数由3列,变成5列,7列,最后变成41列数据。
现在已经将结果数据整理好了,但是前台使用的数据是json,我们还需要将DataFrame类型的df_res变成json对象。增加这些处理代码。
js = {}
column_list = df_res.columns.tolist()
col = []
for i,j in enumerate(column_list):
col.append({"title":j})
js['columns']=col
list_of_rows = df_res.to_dict('records')
list_of_rows = [row.values.tolist() for _, row in df_res.iterrows()]
js['rows']=list_of_rows
这段代码将df_res的列名称加到json对象的'columns'属性,数据行加到json对象的'rows'属性中。
现在工作转到前台。第一步,我们先把数据展示出来,后面再实现svg图表的显示。前台代码的实现没有什么难度,下面是html页面的实现。因为我们使用的是bottle Web框架,需要将这个页面命名成.tpl结尾的模板。
<!doctype html>
<html style="height: 100%">
<head>
<meta charset="utf-8" />
<title>ECharts</title>
<link rel="stylesheet" href="pure-min.css">
<script src="echarts.js"></script>
<script src="jquery.min.js"></script>
</head>
<body style="height: 100%; margin: 0">
<div id="main" style="height: 100%"></div>
<script type="text/javascript">
var js = {{!jsondata}};
let text = "<table class='pure-table'>";
text += "<thead><tr>";
for (let x in js.columns) {
text += "<th>" + js.columns[x].title + "</th>";
}
text += "</tr></thead><tbody>";
for (let i in js.rows) {
text += "<tr>";
for (let j in js.rows[i]) {
text += "<td>" + js.rows[i][j] + "</td>";
}
text += "</tr>";
}
text += "</tbody></table>";
document.getElementById("main").innerHTML = text;
</script>
</body>
</html>
在bottle的控制模块增加路由配置就可以测试显示页面了。我们把这个模板命名为json2html.tpl,控制模块增加下面的配置:
@route('/json2html')
def json2html():
jsondata=getCqData()
return template('./view/json2html',jsondata=jsondata)
好了,浏览器打开http://127.0.0.1:8099/json2html,显示效果如下,截图只截取了前面几列的数据。
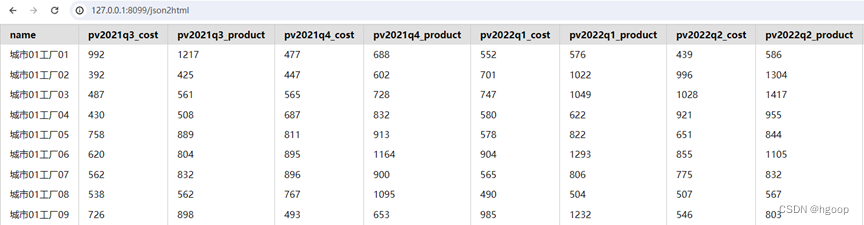
第一步的目标实现了。下面我们着手使用svg可视化成本和产值数据,并将生成的图片显示在每一行的最后一个单元格。
为了展示数据可视化效果,我们只显示前2个历史表的4列数据,修改如下语句实现这个目的。
sql_cmd = '''select 'select "'||name||'" as id, city||factory as name,cost,product from '||name||' ' FROM sqlite_master where name like 'pv%' order by name limit 0, 2'''
刷新页面后可以看到下面的效果。

现在只显示了2个季度的数据,所有看着清爽了很多。我们现在在这个数据表的基础上实现svg数据可视化的功能。
我们在表格的最后一列显示每个季度的成本和产值的趋势。图表使用柱状图展示数据,绿色表示每个季度的成本数据,蓝色表示每个季度的产值数据。
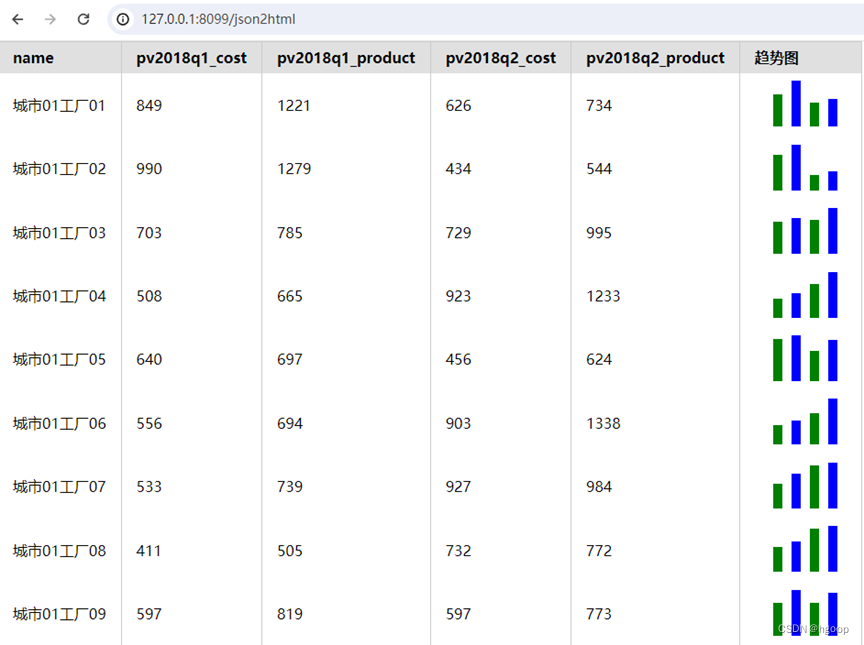
画出柱状图的代码实现如下。
// 添加表格行和SVG柱状图的函数
function addRowWithData(dataItem) {
const tbody = document.querySelector('#data-table tbody');
const row = document.createElement('tr');
dataItem.forEach((value, index) => {
const valueCell = document.createElement('td');
valueCell.textContent = value;
row.appendChild(valueCell);
});
// 添加SVG柱状图单元格
const chartCell = document.createElement('td');
chartCell.classList.add('chart-cell'); // 添加样式类以控制布局和大小
// 创建SVG元素和柱状图
const svg = document.createElementNS('http://www.w3.org/2000/svg', 'svg');
svg.classList.add('bar-chart');
svg.setAttribute('width', '100'); // SVG宽度
svg.setAttribute('height', '50'); // SVG高度(包括条形和间距)
// 假设最大值是10,根据这个值来缩放条形高度
const maxValue = Math.max(...dataItem.slice(1));
// 为每个值添加条形
dataItem .slice(1).forEach((value, index) => {
const bar = document.createElementNS('http://www.w3.org/2000/svg', 'rect');
bar.setAttribute('x', index * 15); // 假设每个条形宽10,间隔5
bar.setAttribute('y', 50 - (value / maxValue) * 50); // 计算y坐标以绘制条形
bar.setAttribute('width', '10'); // 条形宽度
bar.setAttribute('height', (value / maxValue) * 50); // 根据值计算条形高度
bar.setAttribute('fill', index % 2 === 0 ? 'blue' : 'green'); // 示例颜色
svg.appendChild(bar);
});
chartCell.appendChild(svg);
row.appendChild(chartCell);
tbody.appendChild(row);
}
js.rows.forEach(addRowWithData);
创建svg图像的过程就是创建html的元素的过程。简单说,首先创建svg元素这个容器,设置svg图像的长宽。接下来根据数据的个数,向svg容器中排列一个个长方形。长方形的高度与数据的值等比例调整成svg图像上的高度,再按照固定的间隔依次排列,并且为这些长方形填充不同颜色,这样就得到了如图显示效果。
因为svg图像是我们自己一笔一笔画出来的,所以相对于Echarts来说,svg图像用于数据可视化具有更强的可操作性。然而,使用svg图像实现较复杂的效果就有可能导致页面结构复杂,渲染变慢,影响用户使用效果。如何权衡数据可视化以及用户使用感受,需要根据具体项目要求考虑。
作为一个案例,本文的主要内容已经介绍完了,但是本项目其实还有很多可以改进的地方,比如:如何处理异常数据,把成本数据图像和产值数据图像分开显示,把图像改成折线图。我们就把这些提升和改进留给读者自己研究了。
参考
[1] 【数据可视化】SVG(一)https://blog.csdn.net/weixin_43094619/article/details/131564575
系列文章
使用Echarts展示多层级数据案例 下![]() https://blog.csdn.net/hgoop/article/details/137033006
https://blog.csdn.net/hgoop/article/details/137033006
使用Echarts展示多层级数据案例![]() https://blog.csdn.net/hgoop/article/details/135878552
https://blog.csdn.net/hgoop/article/details/135878552















 1695
1695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









