






我先说一下正常的业务流程:需要查询店铺数据,我们会先从redis中查询,判断是否能命中,若命中说明redis中有需要的数据就直接返回;没有命中就需要去mysql数据库查询,在数据库中查到了就返回数据并把该数据存入redis中,若mysql数据库中也查不到就返回null,并返回错误信息:该信息不存在。
代码是用springboot+mybatis plus +redis+mysql实现的
下面这是实现业务的代码:
mapper层:
ublic interface ShopMapper extends BaseMapper<Shop> {
}service实现类
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryById(Long id) {
//1.从redis查询数据缓存 ,CACHE_SHOP_KEY为事先写的静态变量是存在redis中的key前缀用于区分不同业务的key, CACHE_SHOP_KEY值为 cahce:shop:
String key=CACHE_SHOP_KEY+id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) { //isNOtBlank方法只有有值字符串才会返回true,null和空值都会返回false
//3.存在,返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
//4.不存在,根据id查询数据库
Shop shop = getById(id);
//5.不存在,返回错误
if (shop==null){
//将空值缓存到redis
stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
return Result.fail("店铺不存在");
}
//6.存在,写入redis
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL,TimeUnit.MINUTES);
//7.返回\
return Result.ok(shop);
}
}controller层:
@RestController
@RequestMapping("/shop")
public class ShopController {
@Resource
public IShopService shopService;
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
return shopService.queryById(id);
}以上就是代码实现,下面在来了解一下什么是缓存穿透:
正常流程是我们先去redis中查找,redis中没有就会去数据库中找。但可能会有一些人故意或失误的频繁重复的查找一个根本不存在的数据。查找根本不存在数据,流程是先去redis中找,但redis中肯定没有,所以就去数据库中找,但数据库中肯定也没有,当这些人高并发的重复发送查找这个不存在数据的请求,这些请求就会全部发到数据库中,数据库的性能并不算很好,一下子接收这么多请求很容易垮掉,这就是缓存穿透。
解决办法: 有俩个方法,一个是在redis中存入空值,一个是用布隆过滤器。在这我用的是第一个方法,至于布隆过滤器我会简单说一下工作流程。
redis缓存空值:
流程:前面说了,原本是请求一个根本不存在的数据,会先去redis中找,redis没有再去数据库找,数据库没有,返回null。现在呢,数据库中找不到,不仅仅返回null,还会把请求的数据和null存入redis,这样下次在请求这个不存在的数据就能在redis中找到,不用请求数据库了。我们还要为存入的null设置过期时间,不然会一直占用大量内存。
这样做的优点是:逻辑简单,容易实现;缺点是:浪费内存,当某人请求多个不同的不存在数据时,redis中就会存储很多null的数据,占用内存。
布隆过滤器:
流程:原本是请求一个根本不存在的数据,会先去redis中找,在去数据库找。现在是在redis之前在加一个布隆过滤器,请求会先经过布隆过滤器,布隆过滤器会判断请求的数据在数据库中是否存在,存在才会继续往下走,查redis和数据库;判断不存在就直接返回null了。
布隆过滤器判断方法:计算出数据库中所有数据的hash值,将这些hash值转为二进制位保存到布隆过滤器中,判断过程就是判断布隆过滤器中对应位置的数字是0还是1 。 优点是:内存占用少,没有多余的key。缺点是:实现复杂,存在误判的可能。
下面是用redis缓存空值解决的
public Shop queryWithPassThrough(Long id) {
//1.从redis查询数据缓存
String key = CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) { //isNOtBlank方法只有有值字符串才会返回true,null和空值都会返回false
//3.存在,返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return shop;
}
//shopJson不存在
//判断查到的数据是否为空值(这个空值指的不是null,是空字符串)
if (shopJson != null) {
//返回错误信息
return null;
}
//4.不存在,根据id查询数据库
Shop shop = getById(id);
//5.不存在,返回错误
if (shop == null) {
//将空值缓存到redis。参数分别是: redis中存入key ,value,过期时间数字(这里是用的事先写的静态变量,2L),过期时间的单位
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
//6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
//7.返回
return shop;
}下面让我们启动该项目和postman,来测试一下。
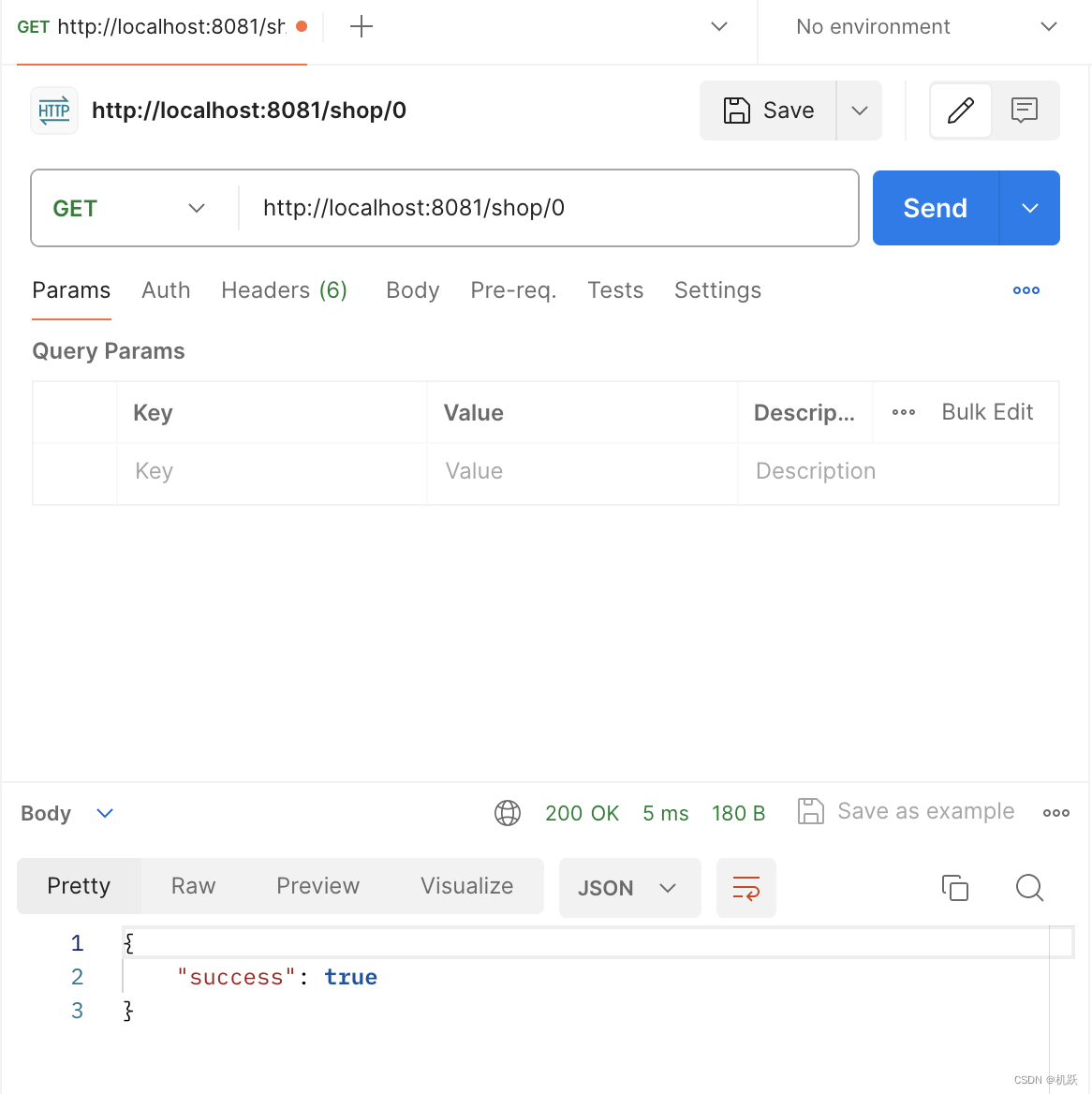
我们请求id为0的数据,数据库id都是从1开始的,所以不存在0号数据,用postman发送请求成功返回true,下面查看redis客户端看看有没有写入空值
图中我们可以看到成功写入并存入空值。
并且idea中返回信息表明查询了数据库一次
我们可以多发几次请求,看看会不会都去请求数据库,注意:前面代码中我们设置的该redis缓存的过期时间只有2分钟,要在2分钟内去发送请求才不会去请求数据库。2分钟后会重新查询一次数据库,然后后空值存入redis。
2分钟内发送多次请求,查看idea控制台
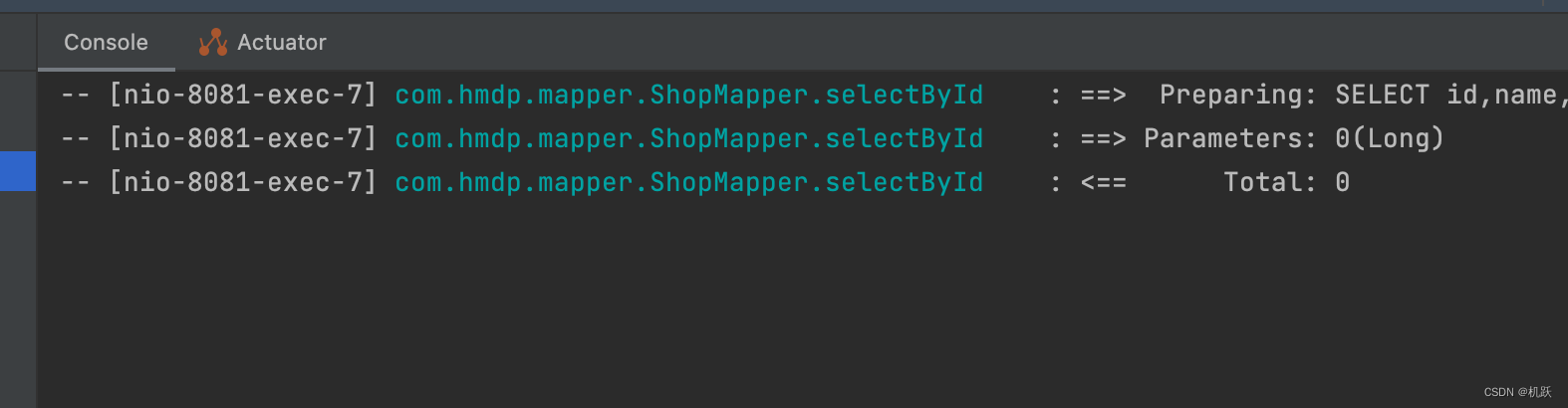
可以看到即使我们发送多次请求,也只返回了一次查询数据库的信息。
这样存储穿透就简单的解决了















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









