







一、docker cpu和内存限制
1、docker限制容器CPU
docker 是通过 CPU cgroups 来限制容器使用的cpu上限,而和CPU groups有关的三个比较重要的参数是: cpu.cfs_quota_us、cpu.cfs_period_us、cpu.shares.
Cgroup 子系统是通过一个虚拟文件挂载点进行管理的,通常是在 /sys/fs/cgroup/cpu 这个目录下。
Linux 通过 CFS(完全公平调度器) 来对调度进程对cpu的使用,默认调度周期是 100ms。影响CFS的有三个参数:
-
cpu.cfs_period_us ,是CFS 调度的周期,默认是 100000,单位是 microseconds 也就是 100ms
-
cpu.cfs_quota_us 在一个调度周期里,这个控制组被允许的运行时间,比如 30000 ,就是 30ms 这两个参数进行除法 cpu.cfs_quota_us/cpu.cfs_period_us ,比如 30ms /100ms = 0.3 ,表示这个控制组被允许使用的CPU最大配额是 0.3个cpu
--cpus=
Specify how much of the available CPU resources a container can use. For instance, if the host machine has two CPUs and you set --cpus="1.5", the container is guaranteed at most one and a half of the CPUs. This is the equivalent of setting --cpu-period="100000" and --cpu-quota="150000". Available in Docker 1.13 and higher.
--cpu-period=
Specify the CPU CFS scheduler period, which is used alongside--cpu-quota. Defaults to 100 micro-seconds. Most users do not change this from the default. If you use Docker 1.13 or higher, use --cpusinstead.
--cpu-quota=
Impose a CPU CFS quota on the container. The number of microseconds per --cpu-period that the container is limited to before throttled. As such acting as the effective ceiling. If you use Docker 1.13 or higher, use --cpus instead.
--cpuset-cpus
Limit the specific CPUs or cores a container can use. A comma-separated list or hyphen-separated range of CPUs a container can use, if you have more than one CPU. The first CPU is numbered 0. A valid value might be 0-3 (to use the first, second, third, and fourth CPU) or 1,3 (to use the second and fourth CPU).
--cpu-shares
Set this flag to a value greater or less than the default of 1024 to increase or reduce the container’s weight, and give it access to a greater or lesser proportion of the host machine’s CPU cycles. This is only enforced when CPU cycles are constrained. When plenty of CPU cycles are available, all containers use as much CPU as they need. In that way, this is a soft limit. --cpu-shares does not prevent containers from being scheduled in swarm mode. It prioritizes container CPU resources for the available CPU cycles. It does not guarantee or reserve any specific CPU access.
① --cpus指示容器可以使用的CPU数量。改参数指定的是百分比,并不是具体的个数。比如:主机有4个逻辑CPU,限制容器—cpus=2,那么该容器最多可以使用的CPU时间是200%,但是4个CPU分配的时间可能是每个CPU各50%,而不一定是有其中2个CPU使用100%,而另2个CPU使用0%。
--cpus是docker 1.13之后才出来的参数,目的是替代--cpu-period和--cpu-quota两个参数,从而使配置更简单。
如果多个容器都设置了 --cpus ,并且它们之和超过主机的 CPU 核数,并不会导致容器失败或者退出,这些容器之间会竞争使用 CPU,具体分配的 CPU 数量取决于主机运行情况和容器的 CPU share 值。也就是说 --cpus 只能保证在 CPU 资源充足的情况下容器最多能使用的 CPU 数,docker 并不能保证在任何情况下容器都能使用这么多的 CPU(因为这根本是不可能的)
--cpu-count :CPU数量(仅Windows)
一、CPU使用绝对限制:
不同与CPU的份额相对限制,Docker还支持一种“硬性”的对CPU资源的限制。我们都知道,现代操作系统为了保证多程序多任务的运行,对CPU的使用采取了分片的策略,CPU在使用时会不断的从一个任务切换到另一个任务,每次获得CPU资源的进程实际上就是获得了CPU的使用权,或者说获得了CPU分片。
在Docker容器运行时,我们可以通过–cpu-period和–cpu-quota参数来指定Docker容器对CPU的占用情况。
② --cpu-period表示的是设置CPU时间周期,默认值是100000,单位是us,即0.1s。
③ --cpu-quota指示容器可以使用的最大的CPU时间,配合--cpu-period值使用。如果—cpu-quota=200000,即0.2s。那就是说在0.1s周期内改容器可以使用0.2s的CPU时间,显然1个CPU是无法满足要求的,需要至少2个CPU才能满足。
二、CPU核心控制
我们有时还希望一个Docker容器能够固定在一个CPU上运行。这对于NUMA(即非一致存储访问结构)的服务器尤为有用,而对于简单的单核服务器则没有任何作用。
④ --cpuset-cpus设置容器具体可以使用哪些个CPU。如--cpuset-cpus=”0,1,2”或者--cpuset-cpus=”0-2”,则容器会使用第0-2个CPU。如果--cpuset-cpus=”0,2”只会使用第0和2核。
三、CPU相对份额限制:
指的是给Docker的镜像分配一个“份额”,使得当CPU资源紧张时,不同的Docker镜像之间对CPU资源的竞争大致上是按照这个份额的比例来进行使用的。
⑤ --cpu-shares,容器使用CPU的权重,默认值是1024,数值越大权重越大。该参数仅当有多个容器竞争同一个CPU时生效。对于单核CPU,如果容器A设置为--cpu-shares=2048,容器B设置为--cpus-shres=1024,仅当两个容器需要使用的CPU时间超过整个CPU周期的时候,容器A会被分配66%的CPU时间,容器B被分配33%的CPU时间,大约是2:1;对于多核CPU,仅当多个容器竞争同一个CPU的时候该值生效。
Docker容器在运行后,我们可以在/sys/fs/cgrou[/cpu/cpu.shares文件中查看我们配置的CPU份额。
好处:能保证 CPU 尽可能处于运行状态,充分利用 CPU 资源,而且保证所有容器的相对公平;
缺点:无法指定容器使用 CPU 的确定值。
容器的CPU配额是通过period和quota之间的大小比重来确定内核的数量,而且是以时间为单位。
例如:1秒内可以使用0.5秒的CPU,等同于可以使用一个内核的50%;1秒内可以使用2秒的CPU,则是两个内核。
限制内核数为quota/period=n。
--cpus指示容器可以使用的CPU数量。

在容器压测:docker exec -it d6a6846f45ae bash
stress-ng --cpu 20 --cpu-method all
然后docker stats d6a6846f45ae 查看:

宿主机的top:

--cpu-shares设置容器按比例弹性共享CPU资源
查看--cpu-shares的指令信息
[root@k8s1-zb ~]# docker run --help | grep cpu-shares
-c, --cpu-shares int CPU shares (relative weight)
--cpu-shares并不能保证容器在运行的时候可以获取多少个CPU资源,只是一个弹性权值。
默认情况下每个容器CPU弹性权值都是1024,只有在同一个CPU核心上面,同时运行多个容器才能看出CPU权值效果。
举例说明:
容器C和D的CPU权值分别为1024和2048,会怎么分配CPU资源?
- 情景1:C和D容器都正常运行,如果占用同一个CPU,那么在CPU时间片分配时,容器D会比容器C多一倍的机会获取CPU时间片。
- 情景2:容器CPU资源分配结果和其他容器 运行状态有关。如果容器D一直空闲,那么容器C也可以获取比容器D更多的CPU时间片。
- cgroups只有在多个容器争夺同一个CPU资源的时候,CUP配额才会生效,不能只根据CPU的权值配额类确定CPU的资源占有情况,容器CPU的资源分配情况,取决于同时运行的其他容器CPU的分配和容器中进行运行情况。
举例1
- 创建容器mycentos1,分配1024的cpu权值,并进入容器
docker run --name mycentos1 --cpu-shares 1024 -it centos /bin/bash
- 查看容器分配的CPU权值
[root@87476ea8bd94 /]# cat /sys/fs/cgroup/cpu/cpu.shares
1024
注:--cpu-shares设置的并不是CPU绝对资源,只是一个相对权重,容器最终能够分配到多少CPU资源,和其他所有容器运行情况以及cpu shares 总和比例有关系。cpu share只是设置了CPU使用的优先级。
--cpuset容器绑定CPU
查看--cpuset的指令信息
[root@k8s1-zb ~]# docker run --help | grep cpuset
--cpuset-cpus string CPUs in which to allow execution (0-3, 0,1)
--cpuset-mems string MEMs in which to allow execution (0-3, 0,1)
--cpuset可以在容器运行时将容器和宿主机的CPU进行对应绑定,从而控制容器运行CPU个数和Z在那个CPU上运行。主要对多CPU、多内存节点服务器有用
举例1
- 创建mycentos1容器,cpu权值1024,只允许在宿主机的cpu1和cpu0上运行
docker run -it --name mycentos1
--cpu-shares 1024
-v /etc/yum.repos.d:/etc/yum.repos.d
--cpuset-cpus 0,1
centos /bin/bash
- 重新打开一个终端创建容器mycentos2,cpu权值2048,只允许在宿主机的cpu1和cpu0上运行
docker run -it --name mycentos1
--cpu-shares 2048
-v /etc/yum.repos.d:/etc/yum.repos.d
--cpuset-cpus 0,1
centos /bin/bash
- 分别在两个容器mycentos1和mycentos2上安装stress压力测试
yum install -y epel-release # 安装epel扩展源
yum -y install stress #安装stress命令
- 分别在两个容器中使用stress命令,将CPU占满
stress -c 2 -v -t 10m #表示在容器中运行2个进程
- 再打开一个终端,输入top指令,然后按1快捷键

发现CPU0和CPU1已经占满,mycentos2容器使用CPU是mycentos1容器使用CPU的2倍。说明资源限制成功。
2、docker限制容器内存
-m限制容器内存
docker提供-m,--memory限制容器内存使用量, 查看--memory的指令信息
docker run --help | grep memory
-m, --memory bytes Memory limit
--memory-reservation bytes Memory soft limit
--memory-swap bytes Swap limit equal to memory plus swap: '-1' to enable unlimited swap
--memory-swappiness int Tune container memory swappiness (0 to 100) (default -1)
举例1
- 创建一个只允许容器内存最多使用128M
docker run --name mycentos3 -it -m 128M centos /bin/bash
- 查看容器的内存限制
cat /sys/fs/cgroup/memory/memory.limit_in_bytes
举例2
创建一个容器mycentos4,只是用1个CPU核心,只是要256M内存
docker run --name mycentos4 --cpuset-cpus 0 -it -m 128M centos /bin/bash3、压测工具
yum install -y stress-ng
stress-ng的参数有几百项,可以模拟复杂的压力测试,但是兼容stress的参数。 主要使用参数:
-c N :运行N worker CPU压力测试进程
--cpu-method all :worker从迭代使用30多种不同的压力算法,包括pi, crc16, fft等等
-tastset N:将压力加到指定核心上
-d N:运行N worker HDD write/unlink测试
-i N:运行N worker IO测试
示例:运行8 cpu, 4 fork, 5 hdd, 4 io, 50 vm, 10小时
stress-ng --cpu 8 --cpu-method all --io 4 --vm 50 -d 5 --fork 4 --timeout 36000s
1、压测cpu,把6个cpu压满
stress-ng --cpu 6 --timeout 180
开启6个CPU进程执行sqrt计算,180秒后结束
2、压测内存,压20G内存
stress-ng --vm 4 --vm-bytes 20G --vm-hang 180 --timeout 180s
开启4个进程分配内存,每次分配20GB内存,保持180秒后释放,180秒后退出。
3、压测磁盘io,开启5个磁盘IO进程,每次写20GB数据到磁盘,180秒后退出
stress-ng --hdd 5 --hdd-bytes 20G --timeout 180s
4、在所有的 CPU 上执行各种 stressors:-cpu-method all
stress-ng --cpu 60 --cpu-method all
4、kubernetes对CPU限制
第一种:资源对象LimitRange限制POD和Container的资源
apiVersion: v1
kind: LimitRange
metadata:
name: mylimits
spec:
limits:
- max:
cpu: "2"
memory: 1Gi
min:
cpu: 200m
memory: 6Mi
type: Pod
- default:
cpu: 300m
memory: 200Mi
defaultRequest:
cpu: 200m
memory: 100Mi
max:
cpu: "2"
memory: 1Gi
min:
cpu: 100m
memory: 3Mi
type: Container
第二种:定义pod时候限制资源
spec:
containers:
- image: gcr.io/google_containers/serve_hostname
imagePullPolicy: Always
name: kubernetes-serve-hostname
resources:
limits:
cpu: "1"
memory: 512Mi
requests:
cpu: "1"
memory: 512Mi
如果两者都配置?
先匹配pod里的,再匹配namespace里。
有些时候, 我们大部分容器遵循一个规则就好, 但有一小部分有特殊需求, 这个时候, 小部分的就需要单独在容器的配置文件中指定. 这里有一点要注意的是, 单独在容器中配置的参数是不能大于指定的k8s资源限制, 否则会报错, 容器无法启动
PS: 对于一些java项目, 必须设置java虚拟机的参数, 而且这个参数不能大于容器设置的限定值, 否则容器会因为内存过大不停的重启
其中:
limits.cpu <==> --cpu-quota # docker inspect中的CpuQuota值
requests.cpu <==> --cpu-shares # docker inspect中的CpuShares值
实验对比
测试工具stress介绍
root@ustress-77b658748b-7856l:/# stress --help
Example: stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10s
Note: Numbers may be suffixed with s,m,h,d,y (time) or B,K,M,G (size).
创建一个测试镜像
ROM ubuntu:latest
RUN apt-get update && \
apt-get install stress
docker build -t reg.99bill.com/99bill/ustress .
创建一个kubernetes中deployment对象
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
appname: ustress
version: 0.0.6
name: ustress
namespace: default
spec:
replicas: 1
selector:
matchLabels:
appname: ustress
template:
metadata:
labels:
appname: ustress
version: 0.0.6
spec:
containers:
- image: reg.99bill.com/99bill/u-stress:latest
name: ustress
command: ['sh', '-c', 'stress -c 4']
resources:
limits:
cpu: 2 #实验修改值
memory: 1G
requests:
cpu: 1 #实验修改值
memory: 500M
terminationGracePeriodSeconds: 0
nodeName: 192.168.112.10
nodeSelector:
注:
① command: ['sh', '-c', 'stress -c 4'] 表示开启4个占用CPU的stress进程
② limits.cpu: 2 对应docker中"CpuQuota": 200000, "CpuPeriod": 100000默认值
③ requests.cpu:1对应docker中"CpuShares": 1024,
实验一:
limits.cpu: 4
requests.cpu: 0.5
结果验证:
1. 查看docker容器参数值:docker inspect e22896246184
512 = 0.5 * 1024
400000 = 4 * 100000

2. docker stats查看容器CPU使用率
由于设置了CPUQuota是CpuPeriod的4倍,所以容器可以使用400% CPU

3. 使用top查看进程与CPU
使用top命令查看4个stress进程,每个占用100% CPU,总400%,可以看到有4个CPU被跑满。


实验二:
limits.cpu: 6
requests.cpu: 0.5
1. 查看docker容器参数值:
512 = 0.5 * 1024
600000 = 6 * 100000

2. docker stats查看容器CPU使用率
容器可以使用600%的CPU,现在只用400%

3. 使用top查看进程与CPU


实验三:
limits.cpu: 1
requests.cpu: 0.5
1. 查看docker容器参数值:
docker inspect e22896246184
512 = 0.5 * 1024
100000 = 1 * 100000
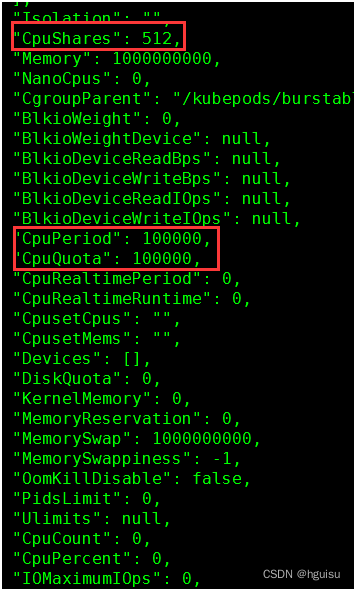
2. docker stats查看容器CPU使用率
使用时间等于CpuPeriod,占用100%

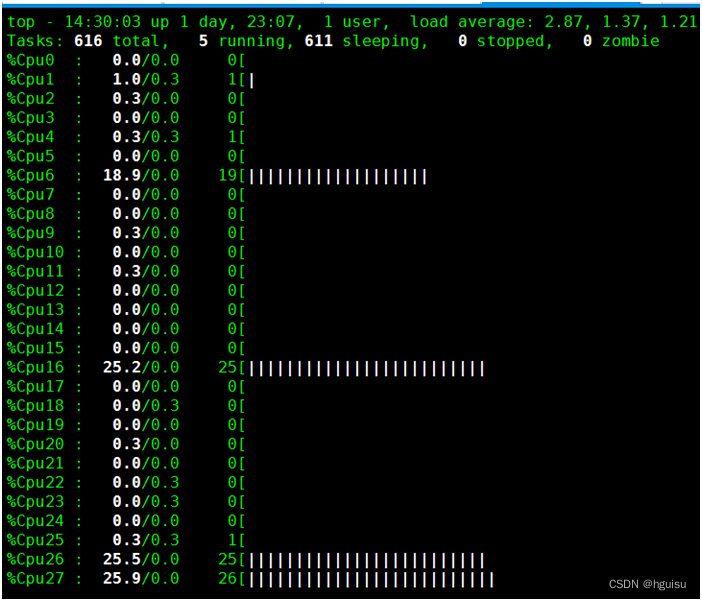
3. 使用top查看进程与CPU

从下图可以看到,有4个CPU分别使用25%,加起来是100%。所以limits.cpu:1并不一定表示容器只会占用1个CPU,而表示的是容器最多可以使用的CPU时间的比例。
实验四:
limits.cpu: 0.5
requests.cpu: 0.5
1. 查看docker容器参数值

2. docker stats查看容器CPU使用率

3. 使用top查看进程与CPU


二、资源视图
1、问题背景
你明明启动的是一个4核8G的容器或Pod,但是进入容器使用free或top看到的却不是4核8G。比如,云君随手使用docker run命令甩出一个只有256mb的容器,待容器启动之后发现free和top显示的都是宿主机的CPU和内存等信息:
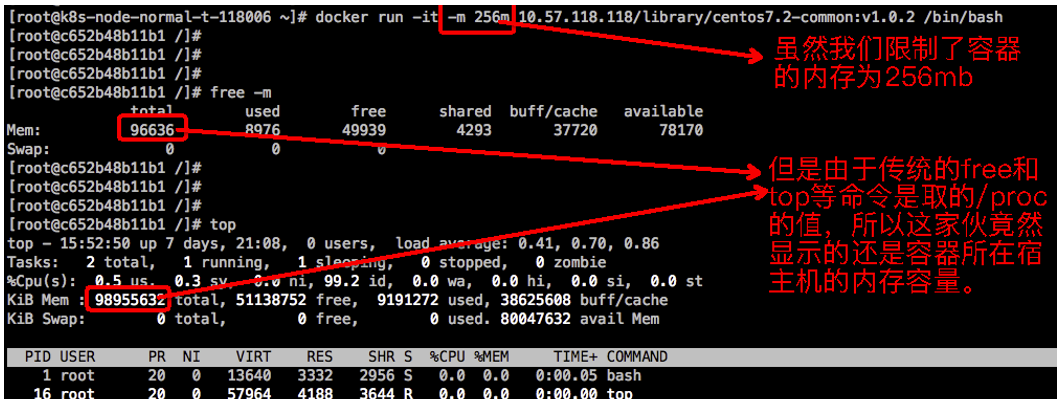
这会导致啥后果呢?默认情况下,这会让容器中的应用程序误以为自己可以使用更多的资源(宿主机资源)。
出现上面这个问题,究其原因是容器创建的时候将宿主机上的/proc/cpuinfo、/proc/meminfo等信息自动加载进来,使得容器从中读取了宿主机的相关信息。解决方案无非是让容器读取到正确的资源信息,方案一般有以下几种:
-
将容器的配置信息写入到容器内的一个标准文件container_info中,然后应用根据container_info中的资源信息,调整应用的配置来解决。比如修改jvm的一些参数,nginx的修改绑定的cpu编号等。
-
在新版本的docker中,容器自己的cgroup会被挂载到容器内部,也就是说容器内部可以直接通过访问/sys/fs/cgroup中对应的文件获取容器的配置信息,就不必再用写入标准文件的方式了。
-
使用LXCFS向容器提供正确的/proc/cpuinfo、/proc/meminfo信息。
如果你的应用愿意改造为读取 container_info或/sys/fs/cgroup信息,可以使用前两种方案。如果你的应用默认从/proc读取信息,但又难以进行改造(比如Linux自带的top和free等工具应用),可以考虑后面这种LXCFS方案。
2、资源视图隔离和LXCFS是什么
LXCFS is a small FUSE filesystem written with the intention of making Linux containers feel more like a virtual machine. It started as a side-project of LXC but is useable by any runtime.
lxcfs 是一个开源的 FUSE(用户态文件系统)实现来支持 LXC 容器,它也可以支持 Docker 容器。让容器内的应用在读取内存和 CPU 信息的时候通过 lxcfs 的映射,转到自己的通过对 cgroup 中容器相关定义信息读取的虚拟数据上。
3、什么是资源视图隔离?
容器技术提供了不同于传统虚拟机技术的环境隔离方式。通常的 Linux 容器对容器打包和启动进行了加速,但也降低了容器的隔离强度。其中 Linux 容器最为知名的问题就是资源视图隔离问题。
容器可以通过 cgroup 的方式对资源的使用情况进行限制,包括: 内存,CPU 等。但是需要注意的是,如果容器内的一个进程使用一些常用的监控命令,如: free, top 等命令其实看到还是物理机的数据,而非容器的数据。这是由于容器并没有做到对/proc,/sys等文件系统的资源视图隔离。
4、为什么要做容器的资源视图隔离?
-
从容器的视角来看,通常有一些业务开发者已经习惯了在传统的物理机,虚拟机上使用
top,free等命令来查看系统的资源使用情况,但是容器没有做到资源视图隔离,那么在容器里面看到的数据还是物理机的数据。 -
从应用程序的视角来看,在容器里面运行进程和在物理机虚拟机上运行进程的运行环境是不同的。并且有些应用在容器里面运行进程会存在一些安全隐患:
对于很多基于 JVM 的 java 程序,应用启动时会根据系统的资源上限来分配 JVM 的堆和栈的大小。而在容器里面运行运行 JAVA 应用由于 JVM 获取的内存数据还是物理机的数据,而容器分配的资源配额又小于 JVM 启动时需要的资源大小,就会导致程序启动不成功。
对于需要获取 host cpu info 的程序,比如在开发 golang 服务端需要获取 golang中
runtime.GOMAXPROCS(runtime.NumCPU())或者运维在设置服务启动进程数量的时候( 比如 nginx 配置中的 worker_processes auto ),都喜欢通过程序自动判断所在运行环境CPU的数量。但是在容器内的进程总会从/proc/cpuinfo中获取到 CPU 的核数,而容器里面的/proc文件系统还是物理机的,从而会影响到运行在容器里面服务的运行状态。
5、如何做容器的资源视图隔离?
lxcfs 横空出世就是为了解决这个问题。
lxcfs 是通过文件挂载的方式,把 cgroup 中关于系统的相关信息读取出来,通过 docker 的 volume 挂载给容器内部的 proc 系统。 然后让 docker 内的应用读取 proc 中信息的时候以为就是读取的宿主机的真实的 proc。
下面是 lxcfs 的工作原理架构图:
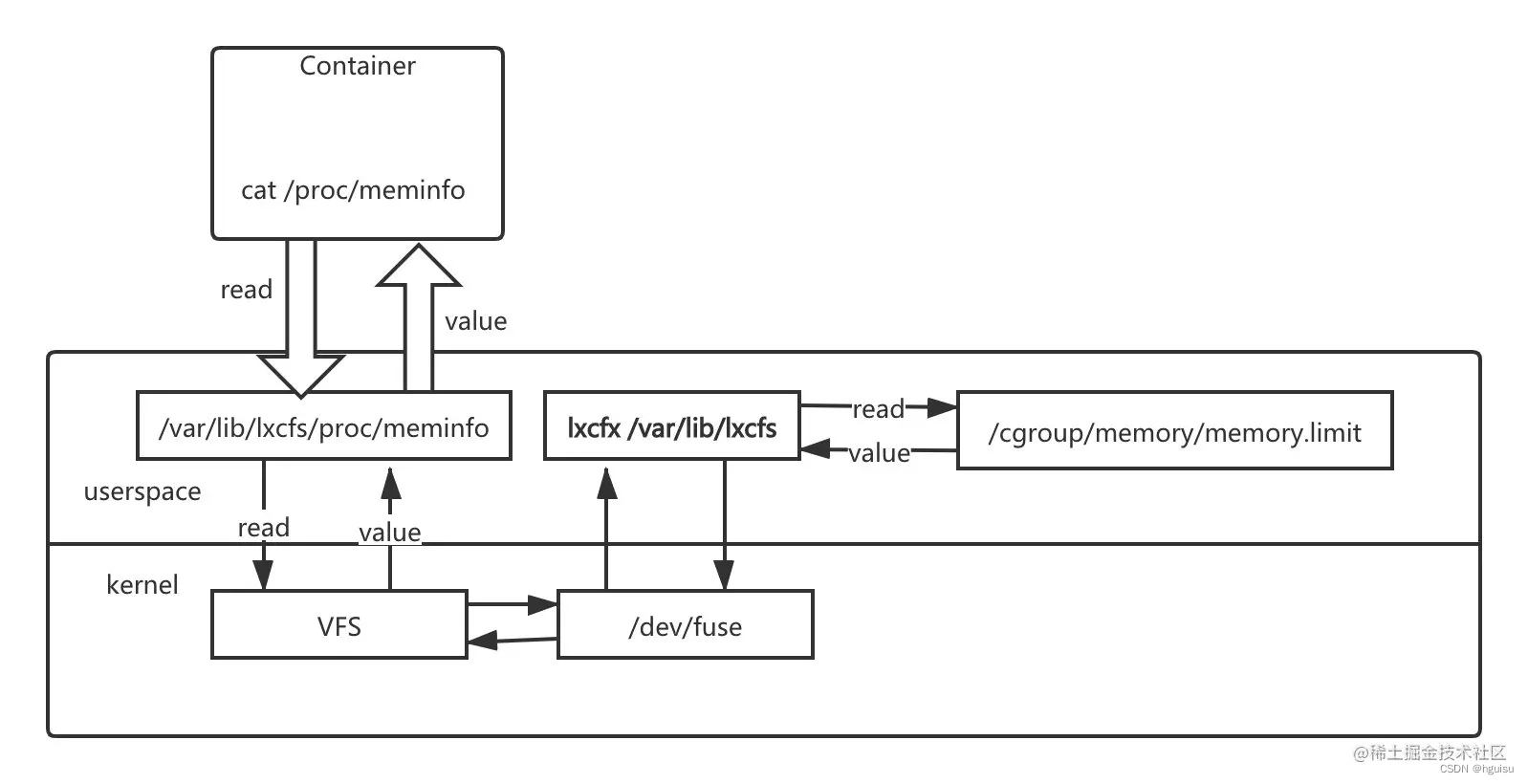
解释一下这张图:
当我们把宿主机的 /var/lib/lxcfs/proc/memoinfo 文件挂载到 Docker 容器的 /proc/meminfo 位置后,容器中进程读取相应文件内容时,lxcfs 的 /dev/fuse 实现会从容器对应的 Cgroup 中读取正确的内存限制。从而使得应用获得正确的资源约束。 cpu 的限制原理也是一样的。
三、Docker环境下LXCFS使用
安装 lxcfs:
wget https://copr-be.cloud.fedoraproject.org/results/ganto/lxc3/epel-7-x86_64/01041891-lxcfs/lxcfs-3.1.2-0.2.el7.x86_64.rpm; rpm -ivh lxcfs-3.1.2-0.2.el7.x86_64.rpm --force --nodeps
检查一下安装是否成功:lxcfs -h
启动 lxcfs
直接后台启动:lxcfs /var/lib/lxcfs &
通过 systemd 启动(推荐)
touch /usr/lib/systemd/system/lxcfs.service
cat > /usr/lib/systemd/system/lxcfs.service <<EOF
[Unit]
Description=lxcfs
[Service]
ExecStart=/usr/bin/lxcfs -f /var/lib/lxcfs
Restart=on-failure
#ExecReload=/bin/kill -s SIGHUP $MAINPID
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start lxcfs.service检查启动是否成功

验证开启 lxcfs
systemctl start lxcfs
# 启动一个容器,用 lxcfs 的 /proc 文件映射到容器中的 /proc 文件,容器内存设置为 256M:
docker run -it -m 256m \\
-v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo:rw \\
-v /var/lib/lxcfs/proc/diskstats:/proc/diskstats:rw \\
-v /var/lib/lxcfs/proc/meminfo:/proc/meminfo:rw \\
-v /var/lib/lxcfs/proc/stat:/proc/stat:rw \\
-v /var/lib/lxcfs/proc/swaps:/proc/swaps:rw \\
-v /var/lib/lxcfs/proc/uptime:/proc/uptime:rw \\
ubuntu:latest /bin/bash
free -h

可以看到容器本身的内存被正确获取到了,对于内存的资源视图隔离是成功的。
# --cpus 2,限定容器最多只能使用两个逻辑CPU
docker run -it --rm -m 256m --cpus 2 \\
-v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo:rw \\
-v /var/lib/lxcfs/proc/diskstats:/proc/diskstats:rw \\
-v /var/lib/lxcfs/proc/meminfo:/proc/meminfo:rw \\
-v /var/lib/lxcfs/proc/stat:/proc/stat:rw \\
-v /var/lib/lxcfs/proc/swaps:/proc/swaps:rw \\
-v /var/lib/lxcfs/proc/uptime:/proc/uptime:rw \\
ubuntu:latest /bin/sh

cpuinfo 也是我们所限制容器所能使用的逻辑 cpu 的数量了。指定容器只能在指定的 CPU 数量上运行应当是利大于弊的,就是在创建容器的时候需要额外做点工作,合理分配 cpuset。
四、lxcfs 的 Kubernetes 实践
在kubernetes中使用lxcfs需要解决两个问题:
第一个问题是每个node上都要启动 lxcfs;
第二个问题是将 lxcfs 维护的 /proc 文件挂载到每个容器中;
我们可以在Pod的定义中添加对 /proc 下面文件的 volume(文件卷)和对 volumeMounts(文件卷挂载)定义。
DaemonSet方式来运行 lxcfs FUSE 文件系统
针对第一个问题,我们使用 daemonset 在每个 k8s node 上都安装 lxcfs。
直接使用下面的 yaml 文件:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: lxcfs
labels:
app: lxcfs
spec:
selector:
matchLabels:
app: lxcfs
template:
metadata:
labels:
app: lxcfs
spec:
hostPID: true
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: lxcfs
image: registry.cn-hangzhou.aliyuncs.com/denverdino/lxcfs:3.0.4
imagePullPolicy: Always
securityContext:
privileged: true
volumeMounts:
- name: cgroup
mountPath: /sys/fs/cgroup
- name: lxcfs
mountPath: /var/lib/lxcfs
mountPropagation: Bidirectional
- name: usr-local
mountPath: /usr/local
volumes:
- name: cgroup
hostPath:
path: /sys/fs/cgroup
- name: usr-local
hostPath:
path: /usr/local
- name: lxcfs
hostPath:
path: /var/lib/lxcfs
type: DirectoryOrCreate
kubectl apply -f lxcfs-daemonset.yaml

可以看到 lxcfs 的 daemonset 已经部署到每个 node 上。
映射 lxcfs 的 proc 文件到容器
针对第二个问题,我们两种方法来解决。
第一种就是简单地在 k8s deployment 的 yaml 文件中声明对宿主机 /var/lib/lxcfs/proc 一系列文件的挂载。
第二种方式利用Kubernetes的扩展机制 Initializer,实现对 lxcfs 文件的自动化挂载。但是 InitializerConfiguration 的功能在 k8s 1.14 之后就不再支持了,这里不再赘述。但是我们可以实现 admission-webhook (准入控制(Admission Control)在授权后对请求做进一步的验证或添加默认参数, https://kubernetes.feisky.xyz/extension/auth/admission)来达到同样的目的。
# 验证你的 k8s 集群是否支持 admission $ kubectl api-versions | grep admissionregistration.k8s.io/v1beta1 admissionregistration.k8s.io/v1beta1
这种方式就让K8S的应用部署文件变得比较复杂,有没有办法让系统自动完成相应文件的挂载呢?
Kubernetes提供了 Initializer 扩展机制,可以用于对资源创建进行拦截和注入处理,我们可以借助它优雅地完成对lxcfs文件的自动化挂载。
其 manifest 文件如下:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: lxcfs-initializer-default namespace: default rules: - apiGroups: ["*"] resources: ["pods"] verbs: ["initialize", "update", "patch", "watch", "list"] --- apiVersion: v1 kind: ServiceAccount metadata: name: lxcfs-initializer-service-account namespace: default --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: lxcfs-initializer-role-binding subjects: - kind: ServiceAccount name: lxcfs-initializer-service-account namespace: default roleRef: kind: ClusterRole name: lxcfs-initializer-default apiGroup: rbac.authorization.k8s.io --- apiVersion: apps/v1 kind: Deployment metadata: initializers: pending: [] labels: app: lxcfs-initializer name: lxcfs-initializer spec: replicas: 1 selector: matchLabels: app: lxcfs-initializer template: metadata: labels: app: lxcfs-initializer spec: serviceAccountName: lxcfs-initializer-service-account containers: - name: lxcfs-initializer image: registry.cn-hangzhou.aliyuncs.com/denverdino/lxcfs-initializer:0.0.4 imagePullPolicy: Always args: - "-annotation=initializer.kubernetes.io/lxcfs" - "-require-annotation=true" --- apiVersion: admissionregistration.k8s.io/v1alpha1 kind: InitializerConfiguration metadata: name: lxcfs.initializer initializers: - name: lxcfs.initializer.kubernetes.io rules: - apiGroups: - "*" apiVersions: - "*" resources: - pods
注: 这是一个典型的 Initializer 部署描述,首先我们创建了service account lxcfs-initializer-service-account,并对其授权了 "pod" 资源的查找、更改等权限。然后我们部署了一个名为 "lxcfs-initializer" 的Initializer,利用上述SA启动一个容器来处理对 "pod" 资源的创建,如果deployment中包含 initializer.kubernetes.io/lxcfs为true的注释,就会对该应用中容器进行文件挂载
我们可以执行如下命令,部署完成之后就可以愉快地玩耍了
kubectl apply -f lxcfs-initializer.yaml下面我们部署一个简单的Apache应用,为其分配256MB内存,并且声明了如下注释 "initializer.kubernetes.io/lxcfs": "true"
其manifest文件如下:
apiVersion: apps/v1 kind: Deployment metadata: labels: app: web name: web spec: replicas: 1 selector: matchLabels: app: web template: metadata: annotations: "initializer.kubernetes.io/lxcfs": "true" labels: app: web spec: containers: - name: web image: httpd:2.4.32 imagePullPolicy: Always resources: requests: memory: "256Mi" cpu: "500m" limits: memory: "256Mi" cpu: "500m"
我们可以用如下方式进行部署和测试
$ kubectl apply -f web.yaml
deployment "web" created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
web-7f6bc6797c-rb9sk 1/1 Running 0 32s
$ kubectl exec web-7f6bc6797c-rb9sk free
total used free shared buffers cached
Mem: 262144 2876 259268 2292 0 304
-/+ buffers/cache: 2572 259572
Swap: 0 0 0我们可以看到 free 命令返回的 total memory 就是我们设置的容器资源容量。
我们可以检查上述Pod的配置,果然相关的 procfs 文件都已经挂载正确
$ kubectl describe pod web-7f6bc6797c-rb9sk
...
Mounts:
/proc/cpuinfo from lxcfs-proc-cpuinfo (rw)
/proc/diskstats from lxcfs-proc-diskstats (rw)
/proc/meminfo from lxcfs-proc-meminfo (rw)
/proc/stat from lxcfs-proc-stat (rw)
...在Kubernetes中,还可以通过 Preset 实现类似的功能,篇幅有限。本文不再赘述了。















 9393
9393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











