






1 Byte-Pair Encoding(BPE) 如何构建词典?
- 准备足够的训练语料;以及期望的词表大小;
- 将单词拆分为字符粒度(字粒度),并在末尾添加后缀“”,统计单词频率
- 合并方式:统计每一个连续/相邻字节对的出现频率,将最高频的连续字节对合并为新的子词;
- 重复第3步,直到词表达到设定的词表大小;或下一个最高频字节对出现频率为1。
注:GPT2、BART和LLaMA就采用了BPE。
WordPiece 篇
1 WordPiece 与 BPE 异同点是什么?
本质上还是BPE的思想。与BPE最大区别在于:如何选择两个子词进行合并
- BPE是选择频次最大的相邻子词合并;
- WordPiece算法选择 能够提升语言模型概率最大的相邻子词进行合并,来加入词表
注:BERT采用了WordPiece。
SentencePiece 篇
简单介绍一下 SentencePiece 思路?
把空格也当作一种特殊字符来处理,再用BPE或者来构造词汇表。
注:ChatGLM、BLOOM、PaLM采用了SentencePiece。
对比篇

举例 介绍一下 不同 大模型LLMs 的分词方式?
- 介绍一下 不同 大模型LLMs的分词方式 的区别?
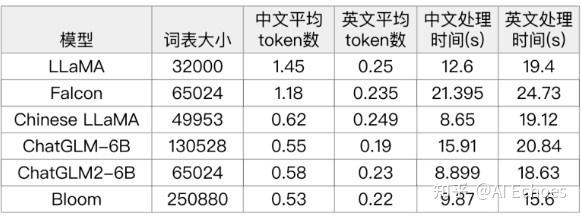
- LLaMA的词表是最小的,LLaMA在中英文上的平均token数都是最多的,这意味着LLaMA对中英文分词都会 比较碎,比较细粒度。尤其在中文上平均token数高达1.45,这意味着LLaMA大概率会将中文字符切分为2个 以上的token。
- Chinese LLaMA扩展词表后,中文平均token数显著降低,会将一个汉字或两个汉字切分为一个token,提高了中文编码效率。
- ChatGLM-6B是平衡中英文分词效果最好的tokenizer。由于词表比较大,中文处理时间也有增加
- BLOOM虽然是词表最大的,但由于是多语种的,在中英文上分词效率与ChatGLM-6B基本相当。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











