






目录
1.决策树简介
决策树是一种用于分类和回归任务的机器学习模型。它通过从数据特征中学习简单的决策规则来进行预测。从根节点开始,根据不同的特征属性进行分支,直到叶节点,叶节点表示最终的预测结果。决策树的构建过程基于训练数据集。常见的构建算法有ID3、C4.5和CART等。算法通过选择最佳的特征属性来分裂节点,并根据特征属性的取值创建子节点。通过递归的方式,持续地将数据集划分为更小的子集,直到满足停止条件。在分类问题中,决策树的叶节点表示不同的类别,对于新的输入数据,通过遵循决策树的路径,可以确定其所属的类别。在回归问题中,叶节点表示一个数值,通过对应的路径可以得到预测的数值。
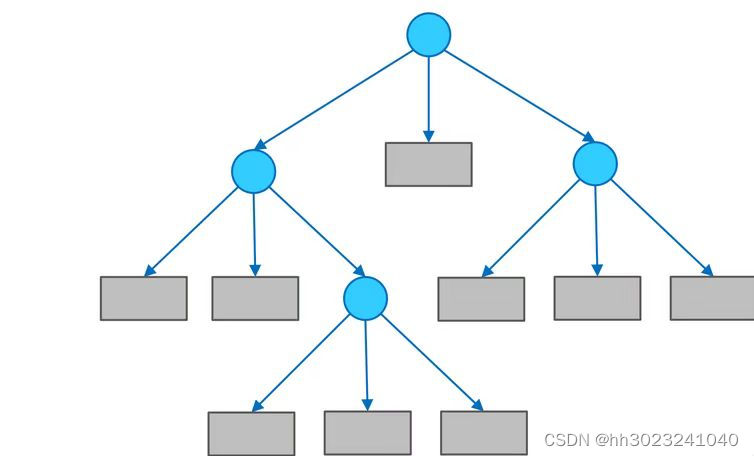
决策树的组成:决策树由结点和有向边组成。结点有两种类型:内部结点(圆)和叶结点(矩形)。其中,内部结点表示一个特征(属性);叶结点表示一个类别。而有向边则对应其所属内部结点的可选项(属性的取值范围)。
如下图所示:
2.构建决策树
2.1决策树停止划分的条件
(1)当前结点包含的样本属于同一类别,无需划分;
(2)当前属性集为空,或是所有样本在所有属性上取值相同无法划分,简单理解就是当分到这一节点时,所有的属性特征都用完了,没有特征可用了,就根据label数量多的给这一节点打标签使其变成叶节点(其实是在用样本出现的后验概率做先验概率);
(3)当前结点包含的样本集合为空,不能划分。这种情况出现是因为该样本数据缺少这个属性取值,根据父结点的label情况为该结点打标记(其实是在用父结点出现的后验概率做该结点的先验概率)。
2.2构建方法
2.2.1 ID3
ID3该方法基于信息论中的熵概念,通过计算划分前后的信息熵差值,选择信息增益最大的属性作为划分依据。
信息熵(information entropy)用来衡量数据集的混乱程度(纯度),信息熵越大,则表明数据集的混乱程度越大。
信息熵用如下公式:
其中,Ck表示属于第k类的个数,所有类别数量的总和为D的数量。
条件信息熵的公式如下:
信息增益的公式如下:
由公式可以看出:信息增益越大,则意味着采用该属性A划分节点获得的纯度提升更大。在每次划分中采用信息增益最大的划分。
2.2.2 C4.5
C4.5算法与ID3相似,在ID3的基础上进行了改进,采用信息增益比来选择属性。ID3选择属性用的是子树的信息增益,ID3使用的是熵(entropy, 熵是一种不纯度度量准则),也就是熵的变化值,而C4.5用的是信息增益率
信息增益率:增益率是用前面的信息增益Gain(D, a)和属性a对应的"固有值"的比值来共同定义的。属性 a 的可能取值数目越多(即 V 越大),则 IV(a) 的值通常会越大.
公式如下:
V表示属性a有V个可能取值 ,若使用a来对样本集合D进行划分,则会产生V个分支结点,其中第v个分支结点包含了D中所有在样本属性a上取值为
的样本,记为
2.2.3 CART
CART是基于基尼(Gini)系数最小化准则来进行特征选择,生成二叉树。
基尼系数代表了模型得不纯度,基尼系数越小,则不纯度越低,特征越好。这点和信息增益是相反的。
在分类问题中,假设有K各类别,第k个类别概率为,则基尼系数的表达式为:
若给定样本D,如果根据特征A的某个值a,把D分为D1和D2两个部分,则在特征条件A下,D的基尼系数表达式为:
2.3剪枝
2.3.1预剪枝
决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点记为叶结点,其类别标记为该结点对应训练样例数最多的类别。
(1)策略:
- 限制深度
- 叶子结点个数
- 叶子结点样本数
- 信息增益
(2)预剪枝优缺点:
优点:降低过拟合风险,显著减少训练时间和测试时间开销。
缺点:欠拟合风险:有些分支的当前划分虽然不能提神泛化性能,但在其基础上进行的后续划分却有可能显著提高性能。预剪枝基于“贪心”本质禁止这些分支展开,带来了欠拟合分险。
2.3.2后剪枝
后减枝先从训练集生成一棵完整的决策树,然后自底向上地对非叶子结点进行分析计算,若将该结点对应的子树替换为叶结点,能带来决策树泛化性能提升,则将该子树替换为叶结点。
后剪枝优缺点
优点:后剪枝比预剪枝保留了更多的分支,欠拟合分险小,泛化性能往往优于预剪枝决策树。
缺点:训练时间开销大。
3.实现
3.1ID3
3.1.1创建数据
该数据集选自适不适合打羽毛球
from math import log
def creatDataSet():
data = [['室内', '晴天', '炎热', '大风', '适合'],
['室内', '阴天', '炎热', '大风', '适合'],
['室外', '阴天', '凉爽', '小风', '适合'],
['室外', '阴天', '凉爽', '小风', '适合'],
['室外', '阴天', '凉爽', '大风', '适合'],
['室内', '下雨', '凉爽', '小风', '适合'],
['室外', '晴天', '炎热', '小风', '不适合'],
['室外', '晴天', '炎热', '小风', '不适合'],
['室外', '晴天', '炎热', '大风', '不适合']
]
labels = ['场地', '天气', '温度', '风力']
return data, labels
3.1.2计算香农熵
def Ent(dataSet):
# 获取数据集中的样本数量
numEntries = len(dataSet)
# 用于存储每个类别的样本数量的字典
Counts = {}
# 统计每个类别的样本数量
for feat in dataSet:
# 获取样本的类别标签
Label = feat[-1]
# 如果类别标签不在 Counts 字典中,则添加并初始化为0
if Label not in Counts.keys():
Counts[Label] = 0
# 类别计数加1
Counts[Label] += 1
# 初始化信息熵值
e = 0.0
# 计算信息熵
for k in Counts:
# 计算每个类别的概率,并累加到信息熵中
e -= (float(Counts[k]) / numEntries) * log((float(Counts[k]) / numEntries), 2)
return e3.1.3划分最优的特征
这段代码是决策树算法中的一部分,用于选择最佳的数据集划分方式。其中,`splitDataSet`函数用于根据特征值将数据集划分为子集,`BestToSplit`函数用于计算每个特征的信息增益,并选择信息增益最大的特征进行划分。
def splitDataSet(dataSet, i, value):
ret = []
for feat in dataSet:
if feat[i] == value:
reduced = feat[:i] # 去掉第i个特征值
reduced.extend(feat[i + 1:]) # 将剩余特征值添加到reduced列表中
ret.append(reduced) # 将处理后的特征值添加到返回列表中
return ret
def BestToSplit(data, i):
print("第%d次划分" % i)
numF = len(data[0]) - 1
E = Ent(data) # 计算数据集的熵
bestGain = 0.0 # 初始化最佳信息增益为0
bestF = -1 # 初始化最佳特征索引为-1
for i in range(numF):
List = [e[i] for e in data] # 获取第i个特征的所有取值
n = set(List) # 去重
newE = 0.0 # 初始化新熵为0
for value in n:
sub = splitDataSet(data, i, value) # 根据特征值划分数据集
prob = len(sub) / float(len(data)) # 计算子集占原数据集的比例
newE += prob * Ent(sub) # 计算新熵
Gain = E - newE # 计算信息增益
print("\"%s\"特征的信息增益为%.3f" % (labels[i], Gain))
if (Gain > bestGain): # 如果当前信息增益大于最佳信息增益
bestGain = Gain # 更新最佳信息增益
bestF = i # 更新最佳特征索引
print("最佳信息增益: %.3f" % bestGain)
print("本次划分的最优属性是:%s" % labels[bestF])
return bestF
3.1.4构建决策树
创建决策树,首先检查数据集中所有样本是否属于同一类别,如果是,则返回该类别;如果数据集的特征数量为1,则返回出现次数最多的类别。接下来,函数找到最佳的特征进行划分,然后递归地创建子树。
#寻找出现次数最多的标签
def mLabel(List):
Counts = {}
for label in List:
if label not in Counts.keys():
Counts[label] = 0
Counts[label] += 1
sorted = sorted(Counts.items(), key=operator.itemgetter(1), reverse=True)
return sorted[0][0]
#构建决策树
def createTree(data, labels, labels2, i):
i += 1 # 递增划分次数
List = [s[-1] for s in data] # 获取数据集中所有样本的类别标签
# 如果所有样本属于同一类别,则返回该类别标签
if List.count(List[0]) == len(List):
return List[0]
# 如果数据集中只剩下一个特征,即所有特征都已经用于划分,则返回样本中出现次数最多的类别标签作为叶子节点
if len(data[0]) == 1:
return mLabel(List) # 返回出现次数最多的类别标签
print(i) # 打印当前划分次数
bestI = BestToSplit(data, i) # 获取最佳划分特征的索引
bestF = labels[bestI] # 获取最佳划分特征的名称
labels2.append(bestF) # 将最佳划分特征的名称添加到labels2列表中
decisionTree = {bestF: {}} # 构建决策树的节点,以最佳划分特征名称为键,值为字典
del (labels[bestI]) # 删除已经用于划分的特征名称
f = [s[bestI] for s in data] # 获取最佳划分特征的所有取值
n = set(f) # 获取最佳划分特征的所有唯一取值
# 遍历最佳划分特征的所有取值
for v in n:
print(v) # 打印当前取值
subLabels = labels[:] # 复制特征标签列表
# 递归构建决策树,对数据集进行划分,直到所有特征都用完或者数据集中的样本属于同一类别
decisionTree[bestF][v] = createTree(splitDataSet(data, bestI, v), subLabels, labels2, i)
return decisionTree # 返回构建好的决策树
3.1.5 分类
对测试样本进行分类预测
def classify1(decisionTree, features, test):
rFeature = list(decisionTree.keys())[0] # 获取决策树的第一个特征
rDict = decisionTree[rFeature] # 获取该特征对应的子树
i = features.index(rFeature) # 获取特征在特征列表中的索引
for v in rDict.keys(): # 遍历子树的键
if test[i] == v: # 如果测试数据的特征值与子树的键匹配
if type(rDict[v]) == dict: # 如果子树的值是字典类型,说明还有下一层子树
Label = classify1(rDict[v], features, test) # 递归调用classify1函数继续分类
else:
Label = rDict[v] # 如果子树的值不是字典类型,说明已经到达叶子节点,返回该节点的标签
return Label # 返回最终的分类结果
3.1.6测试
(1)单个测试
dataSet, labels = creatDataSet()
i = 0
labels2 = []
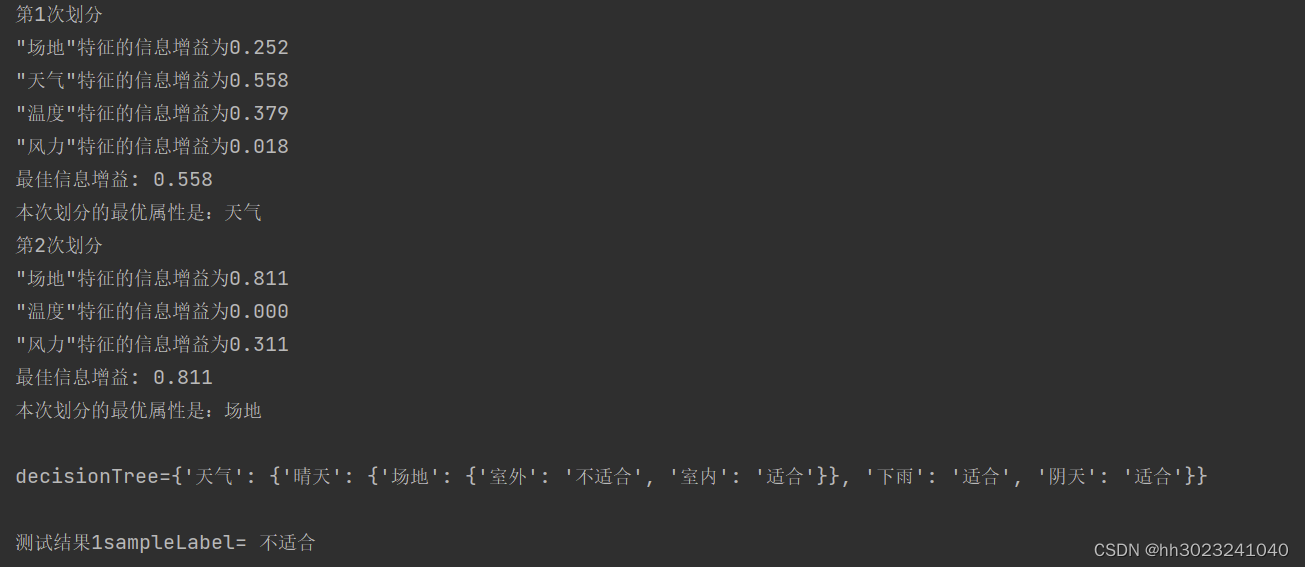
decisionTree = createTree(dataSet, labels, labels2, i)
print(f"\ndecisionTree={decisionTree}\n") # 输出决策树模型结果
features = ['场地', '天气', '温度', '风力'] # 特征列表
test = ['室外', '晴天', '炎热', '小风']
print(f"测试结果1sampleLabel= {classify1(decisionTree, features, test)}\n") # 输出测试结果(2)对多个样本进行预测
y_t=[['室内', '下雨', '凉爽', '小风' ],
['室外', '晴天', '炎热', '小风' ],
['室外', '阴天', '凉爽', '大风'],
['室外', '阴天', '凉爽', '大风']]
predicted_label=precitid3(decisionTree, features, y_t)
print(f"测试结果1sampleLabel= {predicted_label}\n")结果显示
根据数据集来给出决策树,通过决策树、特征值、对测试样本进行预测
(1)单个:
(2)多个:

3.2CART
数据集用的是id3的数据集
3.2.1计算gini
计算给定数据集的基尼系数,并统计每个类别的数量。
import operator
from math import log
import numpy as np
def calcGini(data):
total_sample = len(data) # 获取数据集样本总数
if total_sample == 0:
return 0 # 如果样本数为0,则返回0作为基尼系数
label_counts = label_unique_cnt(data) # 调用label_unique_cnt函数获取每个类别的数量
gini = 0 # 初始化基尼系数为0
for label in label_counts:
gini = gini + pow(label_counts[label], 2) # 计算每个类别数量的平方和
gini = 1 - float(gini) / pow(total_sample, 2) # 根据公式计算基尼系数
return gini
def label_unique_cnt(data):
label_unique_cnt = {} # 初始化一个空字典用于存储每个类别的数量
for x in data:
label = x[len(x) - 1] # 获取当前样本的类别标签
if label not in label_unique_cnt:
label_unique_cnt[label] = 0 # 如果该类别在字典中不存在,则将其数量初始化为0
label_unique_cnt[label] += 1 # 将该类别的数量加1
return label_unique_cnt
3.2.2划分最优特征
选择最佳的特征来划分数据集,并使用基尼系数作为划分的评价指标。
def splitDataSet(dataSet, i, value):
ret = []
for feat in dataSet:
if feat[i] == value:
reduced = feat[:i] # 去掉第i个特征值
reduced.extend(feat[i + 1:]) # 将剩余特征值添加到reduced列表中
ret.append(reduced) # 将处理后的特征值添加到返回列表中
return ret
def BestToSplit3(data,i): # 使用基尼系数进行划分数据集
print(i)
numF= len(data[0]) - 1 # 最后一个位置的特征不算
bestGain = np.Inf
bestF = 0.0
for i in range(numF):
featList = [example[i] for example in data]
uniqueVals = set(featList)
new = 0.0
for value in uniqueVals:
# 通过不同的特征值划分数据子集
sub = splitDataSet(data, i, value)
prob = len(sub) / float(len(data))
new += prob * calcGini(sub)
Gain = new
print("\"%s\"特征的信息增益为%.3f" % (labels[i], Gain))
if (Gain < bestGain): # 选择最小的基尼系数作为划分依据
bestGain = Gain
bestF = i
print("最优: %.3f" % bestGain)
print("本次划分的最优属性是:%s" % labels[bestF])
return bestF3.2.3构建决策树
这一部分与ID3是相似的
def mLabel(List):
Counts = {}
for label in List:
if label not in Counts.keys():
Counts[label] = 0
Counts[label] += 1
sorted = sorted(Counts.items(), key=operator.itemgetter(1), reverse=True)
return sorted[0][0]
def createTree2(data, labels,labels2,i):
i += 1
List = [s[-1] for s in data]
if List.count(List[0]) == len(List):
return List[0]
if len(data[0]) == 1:
return mLabel(List)
#print(i)
bestI = BestToSplit3(data,i)
bestF = labels[bestI]
labels2.append(bestF)
decisionTree = {bestF: {}}
del (labels[bestI])
f = [s[bestI] for s in data]
n= set(f)
for v in n:
#print(v)
subLabels = labels[:]
decisionTree[bestF][v] = createTree(splitDataSet(data, bestI, v),subLabels,labels2,i)
return decisionTree
3.2.4 分类
使用gini指数构建的决策树进行分类
def classify2(decisionTree, features, test):
rFeature = list(decisionTree.keys())[0]
rDict = decisionTree[rFeature]
i = features.index(rFeature)
for v in rDict.keys():
if test[i] == v:
if type(rDict[v]) == dict:
Label = classify2(rDict[v], features, test)
else:
Label = rDict[v]
return Label3.2.5测试
(1)单个预测
dataSet, labels = creatDataSet()
j=0
labels3=[]
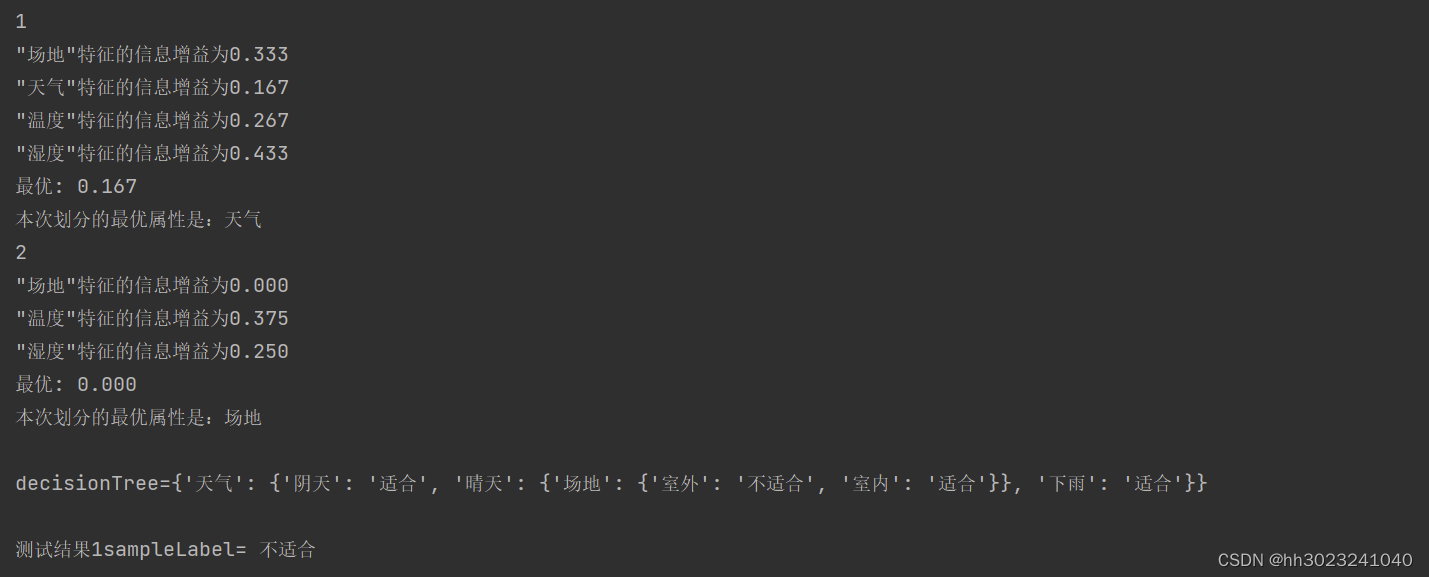
decisionTree2 = createTree2(dataSet, labels,labels3,j)
print(f"\ndecisionTree={decisionTree2}\n") # 输出决策树模型结果
features = ['场地','天气','温度','湿度'] # 特征列表
test =['室外', '晴天', '炎热', '小风']
print(f"测试结果1sampleLabel= {classify2(decisionTree2, features, test)}\n")
createPlot(decisionTree2)(2)多个预测
y_t=[['室内', '下雨', '凉爽', '小风' ],
['室外', '晴天', '炎热', '小风' ],
['室外', '阴天', '凉爽', '大风'],
['室外', '阴天', '凉爽', '大风']]
def precitgini(decisionTree, features, testData):
predicted_label=[]
for testSample in testData:
predicted_label.append(classify2(decisionTree, features, testSample))
return predicted_label
predicted_label=precitgini(decisionTree2, features, y_t)
print(predicted_label)结果:
(1)单个
(2)多个预测

3.3 画图
通过计算决策树的深度,叶子节点数目, 绘制节点,并添加文本标签,在父子节点间添加文本信息。根据节点类型绘制不同样式的节点,根据决策树绘制出图像。
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
# 定义文本框和箭头格式
decisionNode = dict(boxstyle='sawtooth', fc='0.8')
leafNode = dict(boxstyle='round4', fc='0.8')
arrow_args = dict(arrowstyle='<-')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
def getTreeDepth(myTree):
# 用来保存最大层数
maxDepth = 0
# 得到根节点
firstStr = list(myTree.keys())[0]
# 得到key对应的内容
secondDic = myTree[firstStr]
# 遍历所有子节点
for key in secondDic.keys():
# 如果该节点是字典,就递归调用
if type(secondDic[key]).__name__ == 'dict':
# 子节点的深度加1
thisDepth = 1 + getTreeDepth(secondDic[key])
# 说明此时是叶子节点
else:
thisDepth = 1
# 替换最大层数
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
def getNumLeafs(myTree):
numLeafs = 0 # 初始化叶子
firstStr = next(iter(myTree))
secondDict = myTree[firstStr] # 获取下一组字典
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict': # 测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
arrow_args = dict(arrowstyle="<-") # 定义箭头格式
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14) # 设置中文字体
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', # 绘制结点
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args, fontproperties=font)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0] # 计算标注位置
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
cntrPt = (plotTree.xOff + (1 + numLeafs) / 2 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
firstStr = list(myTree.keys())[0]
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]) is dict:
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1 / plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white') # 创建fig
fig.clf() # 清空fig
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) # 去掉x、y轴
plotTree.totalW = float(getNumLeafs(inTree)) # 获取决策树叶结点数目
plotTree.totalD = float(getTreeDepth(inTree)) # 获取决策树层数
plotTree.xOff = -0.5 / plotTree.totalW;
plotTree.yOff = 1.0; # x偏移
plotTree(inTree, (0.5, 1.0), '') # 绘制决策树
plt.show()测试:
(1)ID3
createPlot(decisionTree)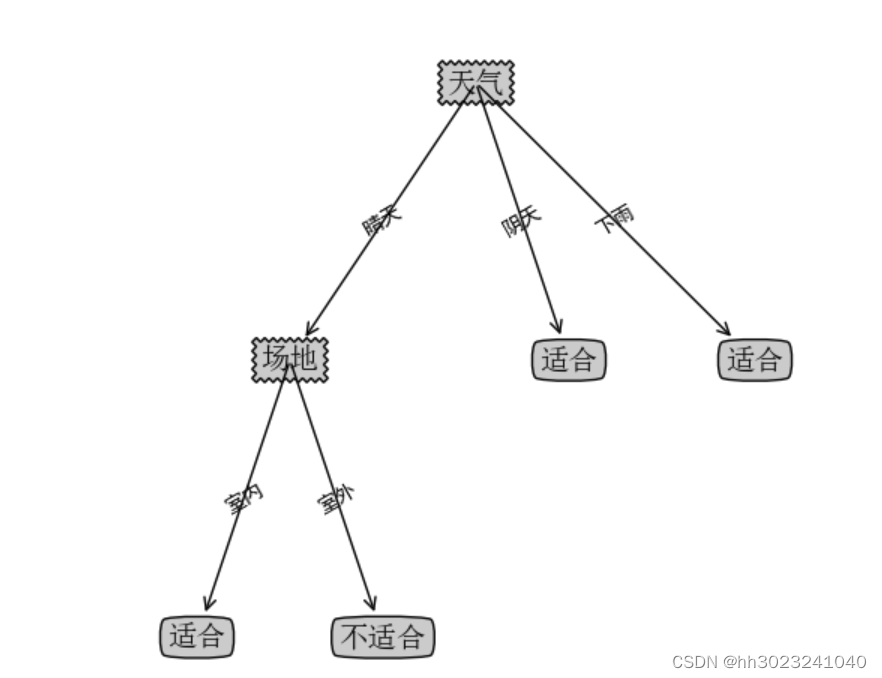
(2)gini
createPlot(decisionTree2)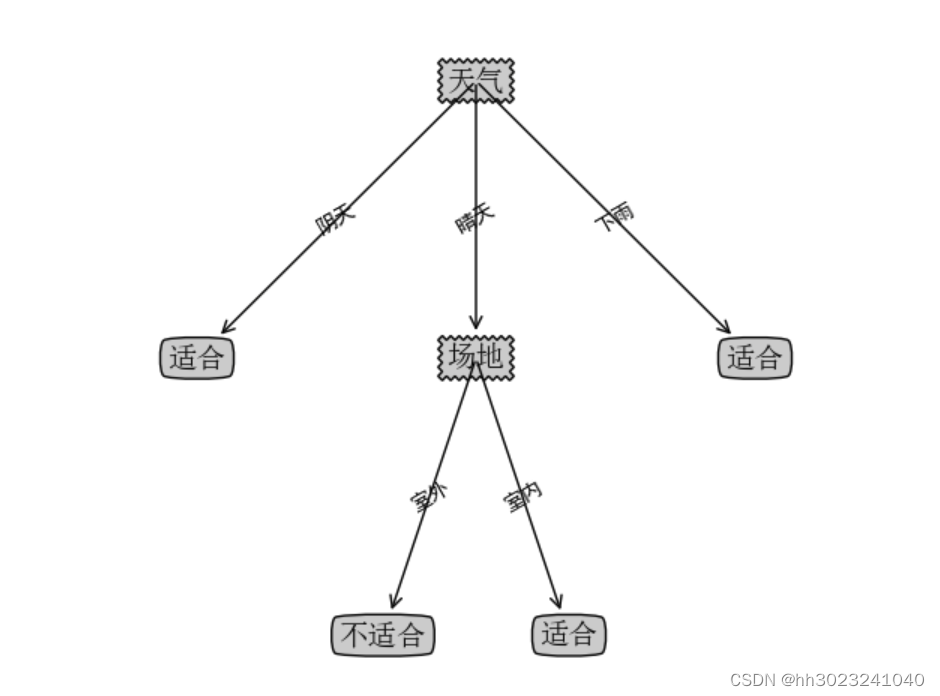
3.4模型评估
3.4.1计算pr和ROC曲线的相关值
这是来自上次实验的代码。
from matplotlib import pyplot as plt
import numpy as np
def CaculatePR(y_test, y_prep):
precision = [] # 存储的Precision值
recall = [] # 存储Recall值
y_score = np.array(y_prep) # 转换为NumPy数组
y_test2 = np.array(y_test) # 转换为NumPy数组
sorted_train_data = y_score.argsort()[::-1] # 将预测从高到低排序,返回索引
num_positives = np.sum(y_test2 == 1) # 统计样本中实际正例的数量
# 遍历每个样本
for i in range(len(y_test2)):
num_real = 0 # 用于计算当前的真实正例数量
num_guess = i + 1 # 当前的预测正例数量
# 在前i个样本中计算真实正例的数量
for j in range(0, i + 1):
index = sorted_train_data[j]
if y_test2[index] == 1: # 如果该样本为真实正例
num_real += 1 # 增加真实正例的数量
precision_value = float(num_real / num_guess) # 计算Precision
recall_value = float(num_real / num_positives) # 计算Recall
precision.append(precision_value) # 将Precision加入列表
recall.append(recall_value) # 将Recall加入列表
return precision, recall
def CaculateROC(y_test, y_preps):
fpr = [] # 存储的假正率
tpr = [] # 存储的真正率
y_prep = np.array(y_preps) # 转换为NumPy数组
y_test2 = np.array(y_test) # 转换为NumPy数组
sortedTraindata = y_prep.argsort()[::-1] # 将预测按照得分从高到低排序,返回索引
num_positives = np.sum(y_test2 == 1) # 统计样本中实际正例的数量
num_negatives = len(y_test2) - num_positives # 统计样本中实际负例的数量
# 遍历每个样本
for i in range(len(y_test2)):
tp = 0 # 用于统计真正例的数量
num_guess = i + 1 # 假设为真的数量
# 在前i个样本中计算真正例的数量
for j in range(0, i + 1):
a = sortedTraindata[j]
if y_test2[a] == 1:
tp += 1 # 如果预测为真实正例,则增加真正例的数量
fp = num_guess - tp # 计算假正例的数量
fpr_value = float(fp / num_negatives) # 计算假正率(FPR)
tpr_value = float(tp / num_positives) # 计算真正率(TPR)
fpr.append(fpr_value)
tpr.append(tpr_value)
return fpr, tpr3.4.2绘制ROC和PR曲线
transform函数就是将标签转化成0或1,其他的和上次模型评估实验相似
def transfrom(label):
list = [1 if value == '合适' else 0 for value in label]
return list
features = ['场地','天气','温度','风力']
y_test=['合适','不合适','合适','不合适']
y_prectid3=['适合', '不适合', '适合', '不适合']
y_pgini=['适合', '不适合', '适合', '不适合']
y_test2= transfrom(y_test)
y_prectid= transfrom(y_prectid3)
y_pgini2= transfrom(y_pgini)
#id3的pr
precision, recall=CaculatePR(y_test2, y_prectid)
pr_auc=np.trapz(precision, recall)
#CART的pr
precision, recall=CaculatePR(y_test2,y_pgini2)
pr_auc2=np.trapz(precision, recall)
#绘制PR
plt.subplot(2,2,1)
plt.plot(precision, recall, lw=2, color='darkorange', label='PR id3curve (AUC = %0.2f)' % pr_auc)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('ID3Precision-Recall curve')
plt.legend(loc="lower right")
plt.subplot(2,2,2)
plt.plot(precision, recall, lw=2, color='darkorange', label='PR ginicurve (AUC = %0.2f)' % pr_auc2)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('CARTPrecision-Recall curve')
plt.legend(loc="lower right")
#plt.show()
#id3的ROC
fpr, tpr = CaculateROC(y_test2, y_prectid)
roc_auc = np.trapz(fpr, tpr)
#CART的ROC
fpr2, tpr2 = CaculateROC(y_test2, y_pgini2)
roc_auc2 = np.trapz(fpr2, tpr2)
#绘制ROC
#plt.figure(figsize=(8, 6))
plt.subplot(2,2,3)
plt.plot(fpr, tpr, color='red', lw=2, label='ROC id2 (AUC = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ID3ROC Curve')
plt.legend(loc='lower right')
plt.subplot(2,2,4)
plt.plot(fpr2, tpr2, color='blue', lw=2, label='ROC jini (AUC = %0.2f)' % roc_auc2)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('CARTROC Curve')
plt.legend(loc='lower right')
plt.show()3.4.3结果显示
CART和ID3的PR、ROC曲线,AUC面积相似
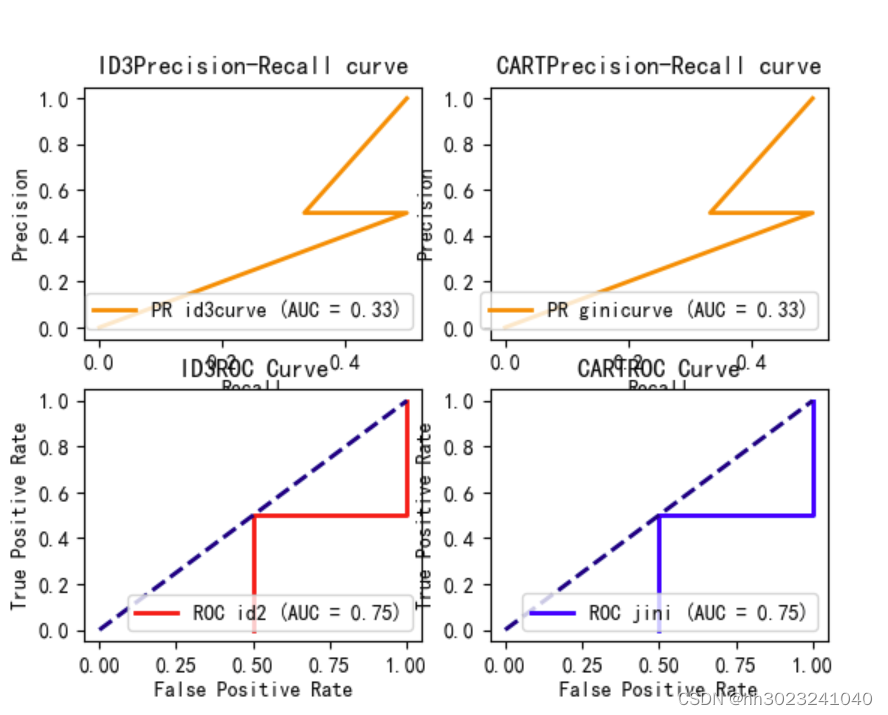
3.5总结
CART和ID3的PR、ROC曲线,AUC面积过于相似,是因为训练集太少,决策树的构建不是很准确,在训练集太少的情况下,预测的精度也不高。在做实验中,也回顾了很多决策树的知识,对决策树有了更深入的了解,回顾了决策树的结束条件,每个划分最优特征的方法和公式,公式的流程更加熟悉,熟悉了决策树预测的流程和构建过程,包括选择特征、划分数据、递归构建子树和定义停止条件等,从中也体会到决策树各个方法的优缺点,让我对决策树有更深入的理解。
ID3 模型:
优点:简单易懂,易于实现和解释。能够处理分类问题,并且能够处理多类别的分类。
缺点:对于缺失值敏感,不能直接处理缺失值。倾向于选择具有更多取值的特征,可能导致过拟合。无法处理连续特征,需要进行离散化处理。
C4.5 模型:
优点:在ID3的基础上改进,能够处理缺失值,并且不需要事先进行数据离散化处理。能够处理分类和回归问题。使用信息增益比来选择最优特征,更加健壮。
缺点:对于大型数据集和高维数据集计算开销较大。
CART 模型:
优点:能够处理分类和回归问题。对于混合类型的特征(包括连续型和离散型)有很好的适应性。生成的树具有较好的泛化能力。
缺点:生成的是二叉树,可能会导致模型过于复杂,容易过拟合。















 6378
6378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









