






 本文介绍了Hadoop系统中数据压缩的重要性和不同压缩算法的特点。包括Gzip、Bzip2、LZO等算法的压缩率、压缩速度及是否支持文件分割等特性。探讨了这些因素如何影响Hadoop的性能,并提供了选择合适压缩格式的建议。
本文介绍了Hadoop系统中数据压缩的重要性和不同压缩算法的特点。包括Gzip、Bzip2、LZO等算法的压缩率、压缩速度及是否支持文件分割等特性。探讨了这些因素如何影响Hadoop的性能,并提供了选择合适压缩格式的建议。
数据压缩
Hadoop 作为一个较通用的海量数据处理平台,每次运算都会需要处理大量数据,我们会在 hadoop 系统中对数据进行压缩处理来优化磁盘使用率,提高数据在磁盘和网络中的传输速度,从而提高系统处理数据的效率。在使用压缩方式方面,主要考虑压缩速度和压缩文件的可分割性。综合所述,使用压缩的优点如下:
1. 节省数据占用的磁盘空间;
2. 加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度。
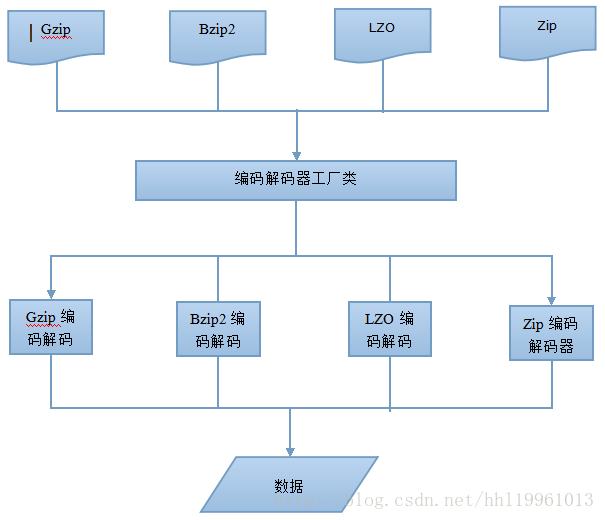
Hadoop 对于压缩格式的是自动识别。如果我们压缩的文件有相应压缩格式的扩展名(比如 lzo,gz,bzip2 等)。Hadoop 会根据压缩格式的扩展名自动选择相对应的解码器来解压数据,此过程完全是 Hadoop 自动处理,我们只需要确保输入的压缩文件有扩展名。
Hadoop 对每个压缩格式的支持, 详细见下表:
算法 原始文件大小 压缩后文件大小 压缩速度 解压缩速度
Gzip 8.3G 1.8G 17.5MB/s 58MB/s
Bzip2 1.1 2.4MB/s 9.5MB/s
LZO-bset 2 4MB/s 60.6MB/s
LZO 2.9 49.3MB/s 74.6MB/s
因此我们可以得出:
1) Bzip2 压缩效果明显是最好的,但是 bzip2 压缩速度慢,可分割。
2) Gzip 压缩效果不如 Bzip2,但是压缩解压速度快,不支持分割。
3) LZO 压缩效果不如 Bzip2 和 Gzip,但是压缩解压速度最快!并且支持分割!
这里提一下,文件的可分割性在 Hadoop 中是很非常重要的,它会影响到在执行作业时 Map 启动的个数,从而会影响到作业的执行效率!
所有的压缩算法都显示出一种时间空间的权衡,更快的压缩和解压速度通常会耗费更多的空间。在选择使用哪种压缩格式时,我们应该根据自身的业务需求来选择。
减少储存文件所需空间,还可以降低其在网络上传输的时间。
压缩算法对比
算法 原始文件大小 压缩后文件大小 压缩速度 解压缩速度
Gzip 8.3G 1.8G 17.5MB/s 58MB/s
Bzip2 1.1 2.4MB/s 9.5MB/s
LZO-bset 2 4MB/s 60.6MB/s
LZO 2.9 49.3MB/s 74.6MB/s
Bzip2支持切分 splitting.hdfs上文件1GB,如按照默认块64MB,那么这个文件被分为16个块。如果把这个块放入MR任务 ,将有16个map任务输入。如果算法不支持切分,后果是MR把这个文件作为一个Map输入。这样任务减少了,降低了数据的本地性。
1.CodeC
实现了一种压缩解压算法。Hadoop中压缩解压类实现CompressionCodec接口
createOutputStream来创建一个CompressionOutputStream,将其压缩格式写入底层的流
演示HDFS上一个1.bzip2算法压缩的文件解压,然后把解压的文件压缩成2.gz
2.本地库
Hadoop使用java开发,但是有些需求和操作并不适合java,所以引入了本地库 native。可以高效执行某些操作。如使用gzip压缩解压时,使用本地库比使用java时间要缩短大约10%,解压达到50%。在hadoop_home/lib/native下
在hadoop配置文件core-site.xml可以设置是否使用native
<property>
<name>Hadoop.native.lib
<value>true
</property>默认是启用本地库,如果频繁使用原生库做压解压任务,可以使用codecpool,通过CodecPool的getCompressor方法获得Compressor对象,需要传入Codec 。这样可以节省创建Codec对象开销 ,允许反复使用。
3.如何选择压缩格式
(1)Gzip 优点是压缩率高,速度快。Hadoop支持与直接处理文本一样。缺点不支持split,当文件压缩在128m内,都可以用gzip
(2)Izo 优点压缩速度快 合理的压缩率;支持split,是最流行的压缩格式。支持native库;缺点 比gzip压缩率低,hadoop本身不支持,需要安装;在应用中对lzo格式文件需要处理如 指定inputformat为lzo格式
(3)Snappy压缩 高速压缩率合理支持本地库。不支持split,hadoop不支持 要安装linux没有对应命令;当MR输出数据较大,作为到reduce数据压缩格式
(4)Bzip2 支持split,很高的压缩率,比gzip高,hadoop支持但不支持native,linux自带命令使用方便。缺点压缩解压速度慢
使用哪种压缩和具体应用有关,对于巨大,没有储存边界的文件如日志 可以考虑
1.储存不压缩的文件
2.使用支持切分的储存格式 bzip2
3.在应用中切分,然后压缩,需要选择合理数据块的大小,以确定压缩后的块大小
4.使用顺序文件SF,支持压缩和切分
5.使用Avro数据文件,支持压缩切分并增加了编程语言可读写的优势对于大文件,不应该使用不支持切分的压缩格式,否则失去本地性,造成MR应用效率低下。















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









