







CNKI例子后续
首先我们先来看看CNKI的主页,常用的就是往搜索框中数据所要查找的数据,根据所需语言选择对应的文献。
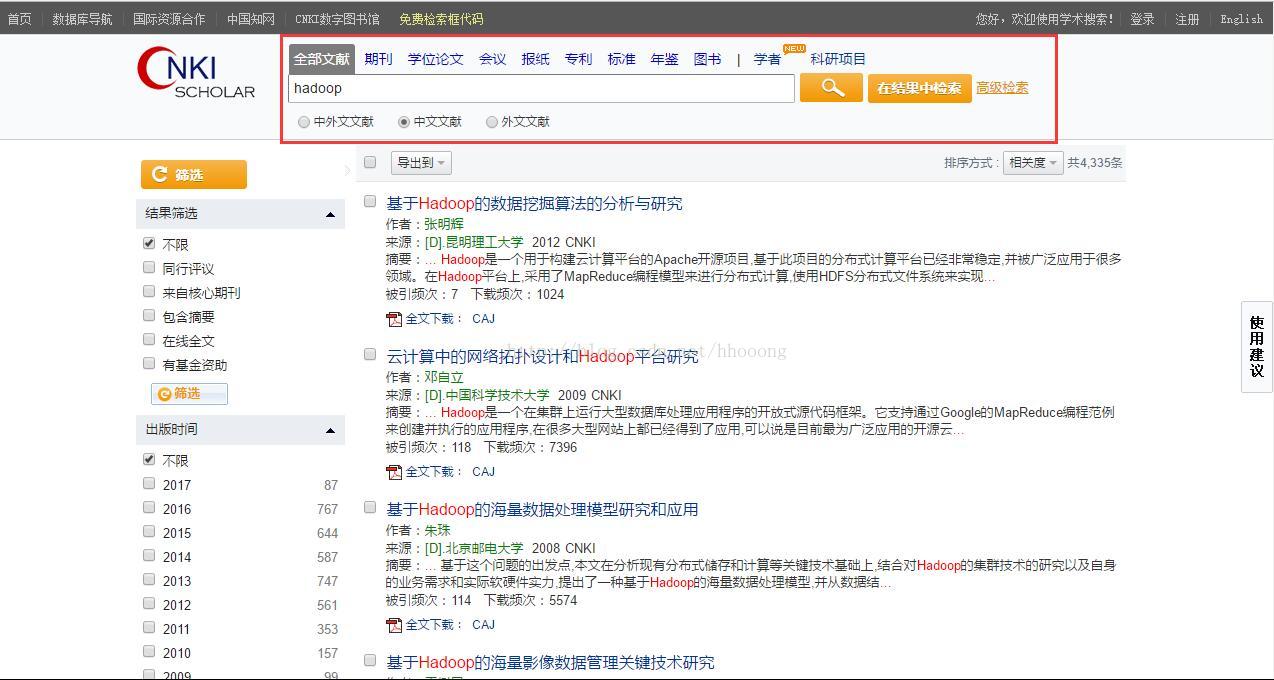
在爬虫第一课,我们介绍了fiddler、chrome开发者工具、firebug等工具。
爬虫关键的一部就是要了解到你的电脑和互联网之间的http通讯,然后了解到请求方式,请求地址,所需参数等信息后,再通过代码发送请求。
我个人常用的是chrome的开发者工具(按F12)与fiddler。
打开谷歌浏览器,按下F12,选择network,然后刷新CNKI的页面。
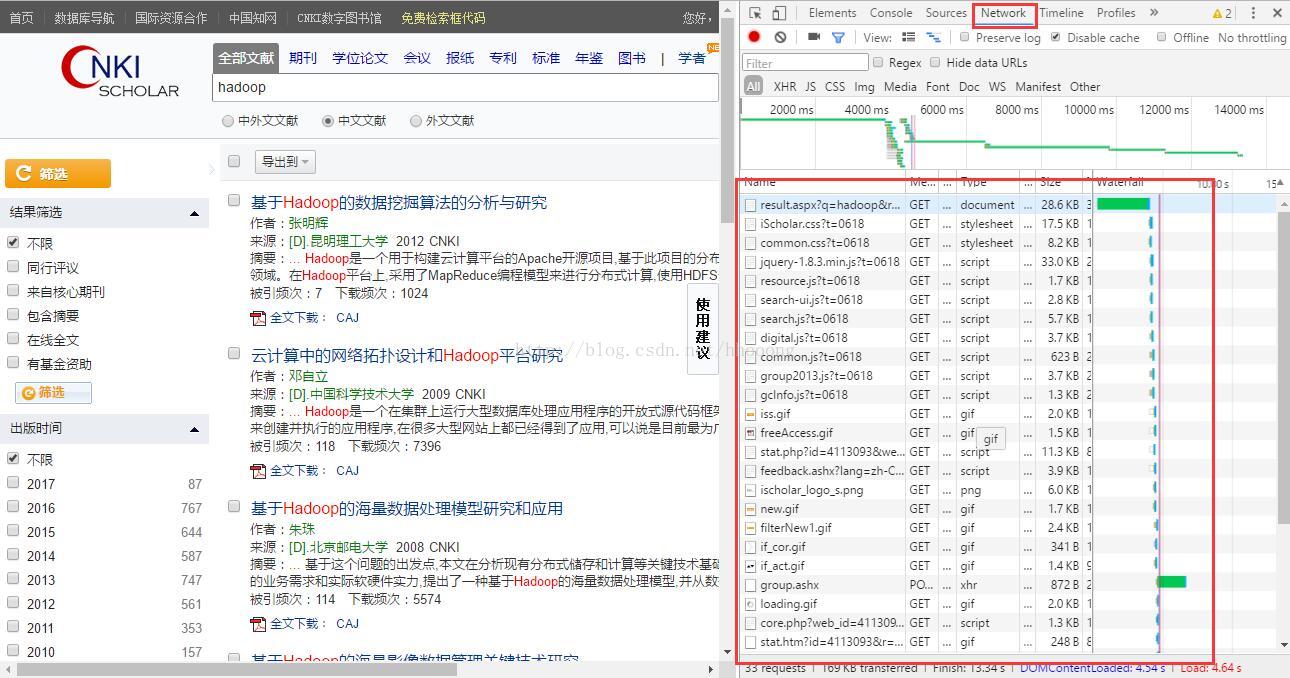
用大红框标注起来的,就是本地与CNKI服务器通讯的内容了。(chrome开发者工具是比较强大的,网上有不少相关教程,这边不做 详细介绍)
我们能看到,发送的请求的Name,有.gif、.png、.js等,对应着gif动图、png图片、JavaScript等请求,我们需要在这些请求中,找到我们所需要知道的,比如在这个例子中,我们需要知道的是,我们在搜索框中输入了"hadoop",点击了搜索,他是如何加载出下面的论文的。
清掉现有数据,然后点击搜索按钮,观察network,
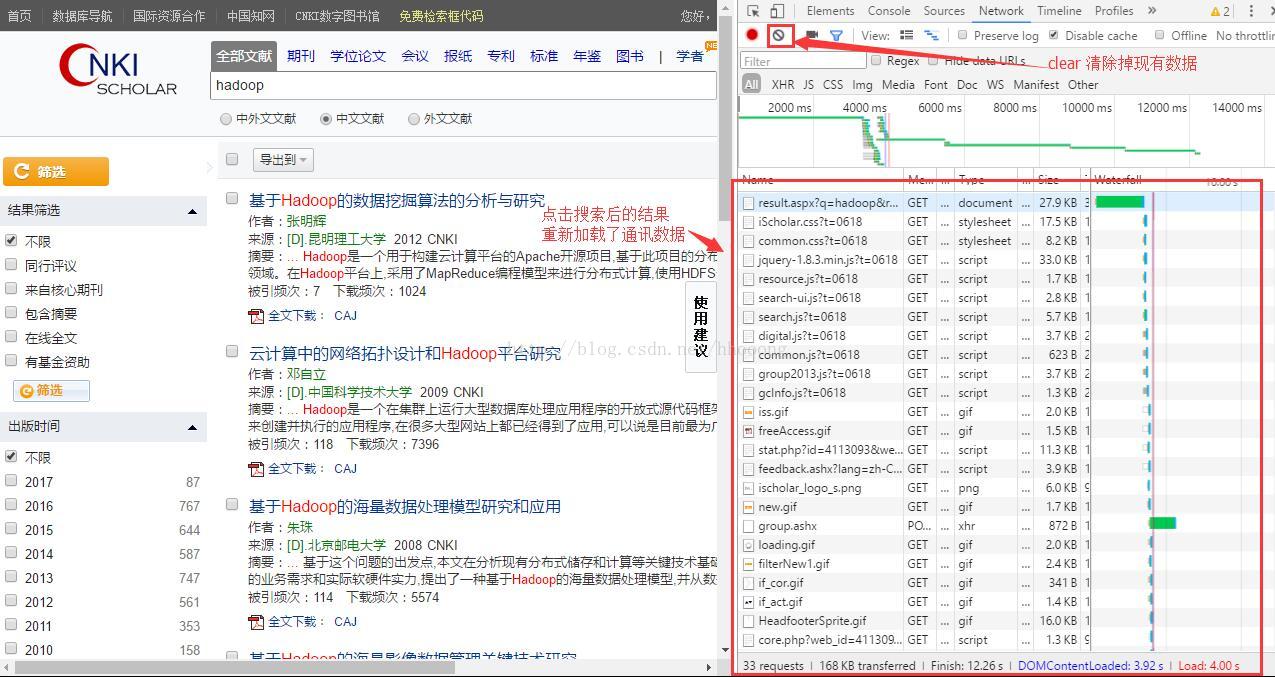
然后就是去查找我们所要的请求了,gif、png这些请求肯定不是我们用的,选择跳过。
然后我们找到了这样的一个请求:
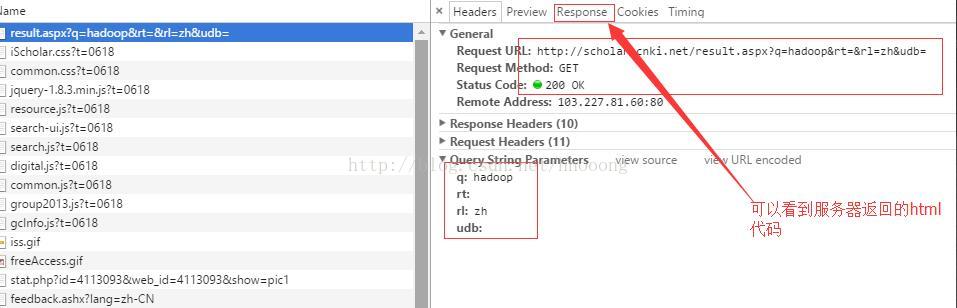
我们点击Response,复制出html代码,放在文本中,修改后缀为html,打开会发现显示出了论文的数据,恩,这就是我们要的第一个请求。
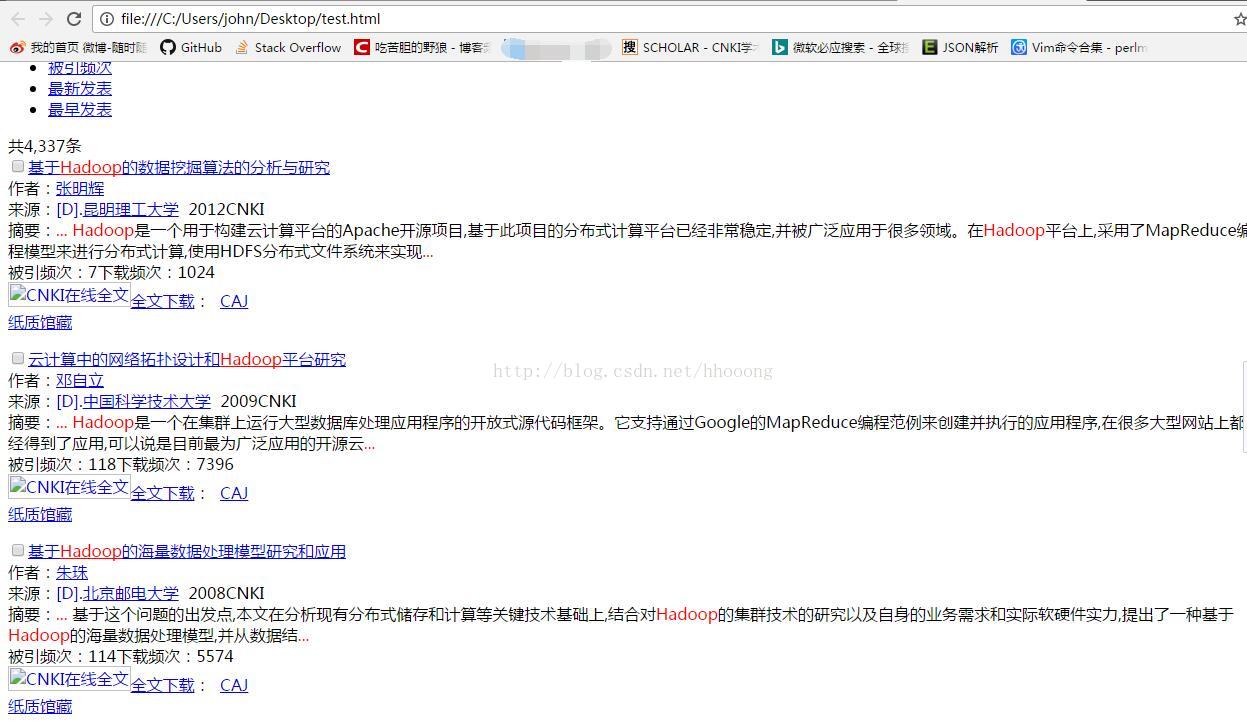
这就是第一个请求了,我们在上张截图中看到了Query String Parammeters,数据是
q: hadoop
q: hadoop
rt:
rl:zh
udb:
尝试在浏览框中输入不同数据,选择不同文献后,会发现q对应着查询内容,rl对应着选择的文献。
当然,做爬虫肯定不可能之抓取一页数据的,我们用上面的代码,只能抓到一页数据,为了抓到下一页,我们再重复上述的步骤,清掉通讯数据后打开F12
点击下一页,我们会看到这样子的请求
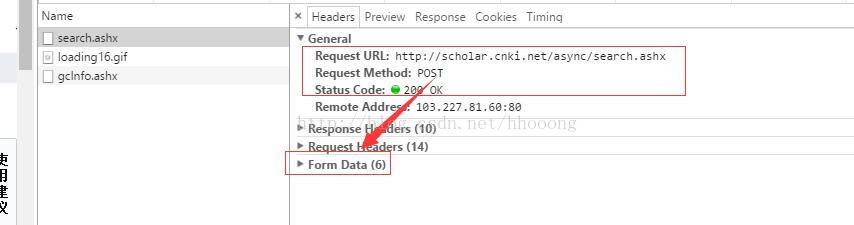
变成了post请求了(爬虫第二课有提及GET与POST请求),提交的参数也变成了Form Data,这说明是提交了一个表单数据(POST所提交的参数类型基本都是Form Data)
点开Form Data,我们看到了6个参数(截图无法截全,就只截取了一半),

rt值是空,t是13位数字(时间戳),上面还有一个page属性,代表第几页,那么wheretoken和sqltoken
上面这一大串类似加密的数字是怎么来的呢?
一边情况下,可以从源页面解析出这两个属性,如果源页面找不到,就去找js代码(存在被js加密的情况,这类情况处理比较复杂)
点开源网页(也就是点击第二页跳转之前的页面,在这个例子中,是第一页),我们查看第一页的源码
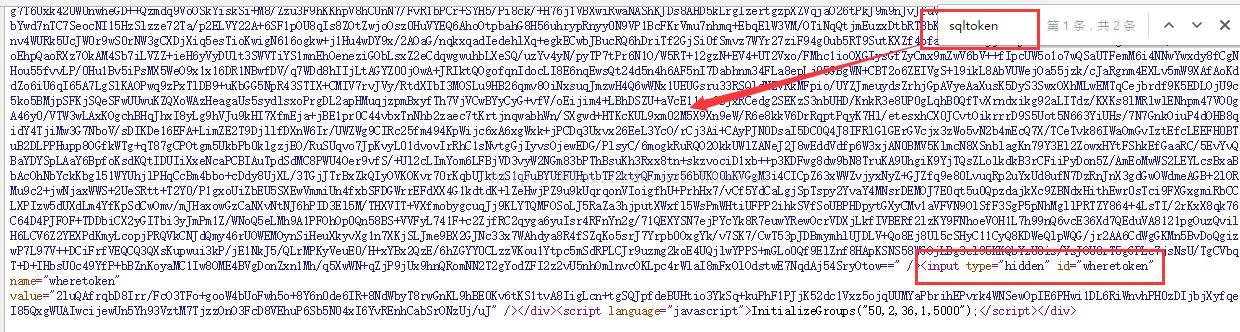
可以看到放在隐藏域中发送了,至此POST请求的参数我们都有了。
贴出代码:
创建POST请求,将表单参数通过简单名称值对节点类型(NameValuePair)放入POST实体中
import org.apache.http.HttpResponse;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.protocol.HTTP;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
String keyWord = "hadoop";//关键字查询
String language = "zh"; //空表示中英文,zh表示中文,fn表示外文
// int crawlerPageCount = 4;//爬虫抓取页
CloseableHttpClient client = HttpClients.createDefault(); //创建HttpClient对象
HttpGet request = new HttpGet("http://scholar.cnki.net/result.aspx?q=" + keyWord + "&rt=&rl=" + language + "&udb=");
HttpResponse response = client.execute(request);
String result = EntityUtils.toString(response.getEntity());
Document doc = Jsoup.parse(result);
Elements eles = doc.select("span.title");
for (Element ele : eles) {
System.out.println(ele.text() + " " + ele.select("a").attr("href"));
}
//休息一会儿
Thread.sleep(3000);
for (int i = 2; i <= 5; i++) {
HttpPost post = new HttpPost("http://scholar.cnki.net/async/search.ashx");
List<NameValuePair> nvps = new ArrayList<NameValuePair>();
nvps.add(new BasicNameValuePair("type", "pagination search"));
nvps.add(new BasicNameValuePair("page", String.valueOf(i)));
nvps.add(new BasicNameValuePair("sqltoken", doc.getElementById("sqltoken").val()));
nvps.add(new BasicNameValuePair("wheretoken", doc.getElementById("wheretoken").val()));
nvps.add(new BasicNameValuePair("rt", ""));
nvps.add(new BasicNameValuePair("t", String.valueOf(System.currentTimeMillis())));
post.setEntity(new UrlEncodedFormEntity(nvps, HTTP.UTF_8));
//http的post请求开始发起
response = client.execute(post);
//将请求返回的内容进行转换
String entity = EntityUtils.toString(response.getEntity());
Elements elements = Jsoup.parse(entity).select("span.title");
for (Element ele : elements) {
System.out.println(ele.text() + " " + ele.select("a").attr("href"));
}
Thread.sleep(2000);
}














 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









