







目录
一、背景
想知道每月最火的小说是哪些?想知道每本小说月票榜数,周票榜数和打赏人数是多少,下面是向目标网站的网址发送请求,我们想要的字段都在页面源代码里
二、实现过程
1、导包
# coding=utf-8
import requests
import re
import random
from time import sleep
import csv
from fake_useragent import UserAgent2、创建对象
创建Book类,写入初始化方法来实现全局变量,并构建随机请求头来解决反爬
class Book(object):
def __init__(self):
self.url = 'https://www.qdmm.com//rank/yuepiao/year2022-month0{0}-page{1}/'
self.headers = {
'User-Agent': UserAgent().random, # 构造随机请求头
}
self.herf_list = []
self.content_list = []3、发送请求
def get_content(self, url): # 获取列表页内容
res = requests.get(url=url, headers=self.headers)
content = res.text
return content4、解析详情页网址
def parse_herf(self, content): # 解析详情页的链接
result = re.compile(r'<h2><a href="(?P<href>.*?)" target="_blank"')
find_result = result.finditer(content)
for it in find_result:
herf = it.group('href').replace('//', 'https://') # 由于链接不全,我们用replace来实现替换
self.herf_list.append(herf) # 将获取的链接添加在herf_list列表中
return self.herf_list
5、向详情页发送请求
def get_child_content(self, herf_list): # 请求列表页链接
# print(herf_list.pop(0))
sleep_time = random.randint(1, 5) # 设置1到5的随机时间来随机等待向详情页发送的请求
sleep(sleep_time)
res = requests.get(url=herf_list.pop(-1), headers=self.headers) # 向详情页发送请求
child_content = res.text
return child_content6、解析详情页
def parse_child_content(self,child_content): # 解析详情页名字,作者,类型,月票榜,周票榜,打赏人数等字段
result2 = re.compile(
r'<div class="book-info ">.*?<em>(?P<title>.*?)</em> <span><a class="writer".*?data-eid="qd_G08">'
r'(?P<auther>.*?)</a> 著</span>.*?data-eid="qd_G10" title="(?P<type>.*?)">.*?</a>'
r'.*?<i id="monthCount">'
r'(?P<month>.*?)</i></p>.*?<i id="recCount">(?P<week>.*?)</i></p>.*?id="rewardNum">'
r'(?P<rewardNum>.*?)</i></p>')
find_result = result2.finditer(child_content) # 用迭代器返回数据
for itt in find_result: # 遍历迭代器
content = itt.groupdict()
print(content)
self.content_list.append(content) # 将解析数据添加在content_list列表里
return self.content_list7、写入csv文件
@staticmethod
def write_csv(content_list):
with open('./qidian.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['名字', '作者', '类型', '月票榜', '周票榜', '打赏人数']) # 在csv文件里创建表头
for i in content_list:
writer.writerow(i.values()) # 写入数据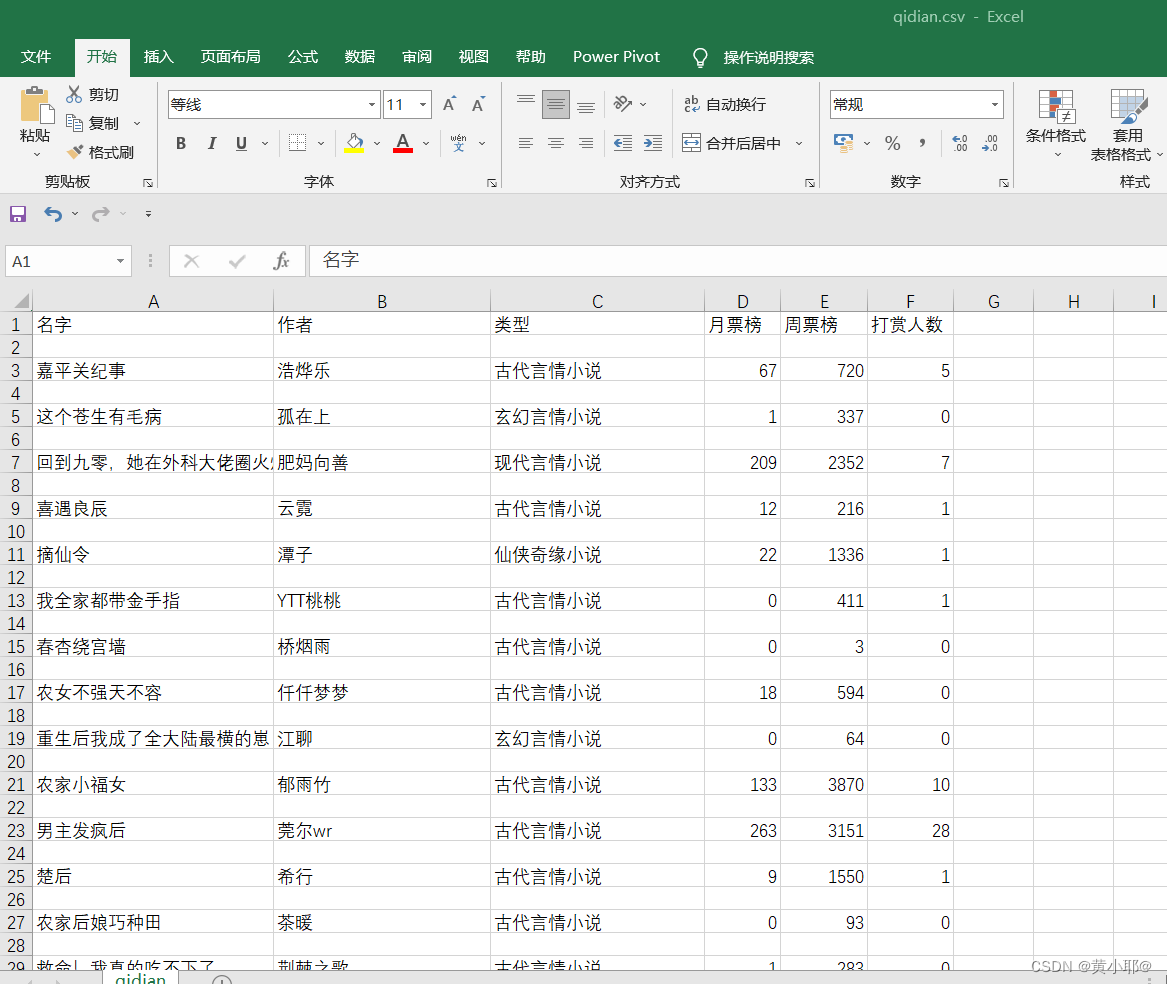
8、定义主方法
def run(self): # 实现翻页功能,并调用之前的功能方法
for month in range(1, 10, 1): # 循环月份
for page in range(1, 6, 1): # 循环页数
url = self.url.format(month, page)
print(f'正在爬取第{month}月的第{page}页!')
content = self.get_content(url)
href_list = self.parse_herf(content)
for a in range(1, 21):
child_content = self.get_child_content(href_list)
content_list=self.parse_child_content(child_content)
self.write_csv(content_list)
print('全部爬取结束!')9、运行主方法
if __name__ == '__main__':
book = Book()
book.run()三、以下是完整代码
# coding=utf-8
import requests
import re
import random
from time import sleep
import csv
from fake_useragent import UserAgent
class Book(object):
def __init__(self):
self.url = 'https://www.qdmm.com//rank/yuepiao/year2022-month0{0}-page{1}/'
self.headers = {
'User-Agent': UserAgent().random, # 构造随机请求头
}
self.herf_list = []
self.content_list = []
def get_content(self, url): # 获取列表页内容
res = requests.get(url=url, headers=self.headers)
content = res.text
return content
def parse_herf(self, content): # 解析详情页的链接
result = re.compile(r'<h2><a href="(?P<href>.*?)" target="_blank"')
find_result = result.finditer(content)
for it in find_result:
herf = it.group('href').replace('//', 'https://') # 由于链接不全,我们用replace来实现替换
self.herf_list.append(herf) # 将获取的链接添加在herf_list列表中
return self.herf_list
def get_child_content(self, herf_list): # 请求列表页链接
# print(herf_list.pop(0))
sleep_time = random.randint(1, 5) # 设置1到5的随机时间来随机等待向详情页发送的请求
sleep(sleep_time)
res = requests.get(url=herf_list.pop(-1), headers=self.headers) # 向详情页发送请求
child_content = res.text
return child_content
def parse_child_content(self,child_content): # 解析详情页名字,作者类型,月票榜,周票榜,打赏人数等字段
result2 = re.compile(
r'<div class="book-info ">.*?<em>(?P<title>.*?)</em> <span><a class="writer".*?data-eid="qd_G08">'
r'(?P<auther>.*?)</a> 著</span>.*?data-eid="qd_G10" title="(?P<type>.*?)">.*?</a>'
r'.*?<i id="monthCount">'
r'(?P<month>.*?)</i></p>.*?<i id="recCount">(?P<week>.*?)</i></p>.*?id="rewardNum">'
r'(?P<rewardNum>.*?)</i></p>')
find_result = result2.finditer(child_content) # 用迭代器返回数据
for itt in find_result: # 遍历迭代器
content = itt.groupdict()
print(content)
self.content_list.append(content) # 将解析数据添加在content_list列表里
return self.content_list
@staticmethod
def write_csv(content_list):
with open('./qidian.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['名字', '作者', '类型', '月票榜', '周票榜', '打赏人数']) # 在csv文件里创建表头
for i in content_list:
writer.writerow(i.values()) # 写入数据
def run(self): # 实现翻页功能,并调用之前的功能方法
for month in range(1, 10, 1): # 循环月份
for page in range(1, 6, 1): # 循环页数
url = self.url.format(month, page)
print(f'正在爬取第{month}月的第{page}页!')
content = self.get_content(url)
href_list = self.parse_herf(content)
for a in range(1, 21):
child_content = self.get_child_content(href_list)
content_list=self.parse_child_content(child_content)
self.write_csv(content_list)
print('全部爬取结束!')
if __name__ == '__main__':
book = Book()
book.run()



















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











