









目录
1. Celery简介
Celery是由纯python编写的,但是协议可以用任何语言实现。目前,已有Ruby实现的RCelery、Node.js实现的node-celery及一个PHP客户端,语言互通也可以通过using webhooks实现。在使用Celery之前,我们先来了解以下几个概念:
任务队列:简单来说,任务队列就是存放着任务的队列,客户端将要执行的任务的消息放入任务队列中,执行节点worker进行持续监视队列,如果有新任务,就取出来执行该任务。这种机制就像生产者消、费者模型一样,客户端作为生产者,执行节worker点作为消费者,它们之间通过任务队列进行传递,如图:
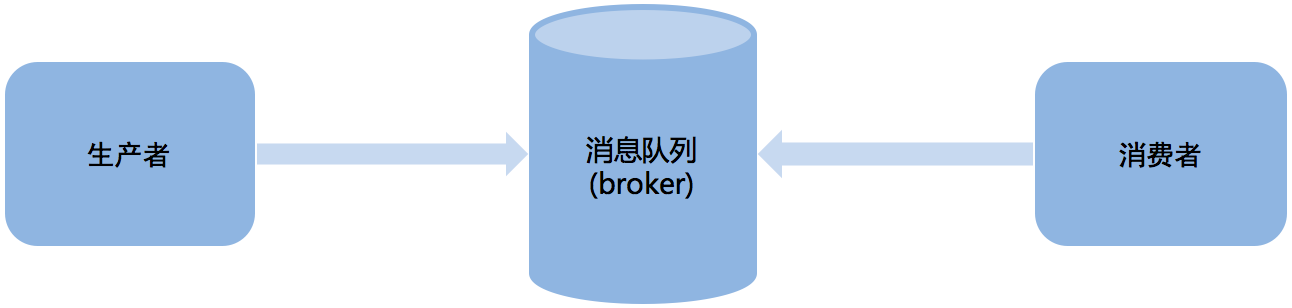
中间人(broker):Celery用于消息通信,通常使用中间人(broker)在客户端和worker之间传递,这个过程从客户端(生产者)向队列添加消息开始,之后中间人把消息派送给worker(消费者)。官方给出的实现broker的工具如下:
| 名称 | 状态 | 监视 | 远程控制 |
| RabbitMQ | 稳定 | 是 | 是 |
| Redis | 稳定 | 是 | 是 |
| MongoDB | 实验性 | 是 | 是 |
| Beanstalk | 实验性 | 否 | 否 |
| AmazonSQS | 实验性 | 否 | 否 |
| Zookeeper | 实验性 | 否 | 否 |
| DjangoDB | 实验性 | 否 | 否 |
| SQLAlchemy | 实验性 | 否 | 否 |
| CouchDB | 实验性 | 否 | 否 |
| Iron MQ | 第三方 | 否 | 否 |
提示: 在实际的使用中,推荐使用RabbitMQ或者Redis作为broker
- 任务生产者:调用Celery提供的API、函数、装饰器产生任务并交给任务队列的都是任务生产者。
- 执行单元worker:属于任务队列的消费者,持续地监控任务队列,当队列中有新的任务时,便取出来执行。
- 任务结果存储backend:用来存储worker执行任务的结果,Celery支持不同形式的存储任务结果,包含Redis,MongoDB等。
- 任务调度器beat:Celery Beat进程会读取配置文件的内容,周期性地将配置中需要到期执行的任务发送到任务队列执行。
Celery的特性:
- 高可用:如果连接丢失或失败,worker和客户端就会自动重试,并且中间人broker通过主/主,主/从方式来提高可用性。
- 快速:单个Celery进程每分钟执行数以百万计的任务,且保持往返延迟在亚毫秒级,可以选择多进程、Gevernt等并发执行。
- 灵活:Celery几乎所有模块都可以扩展或单独使用。可以自制连接池,日志、调度器、消费者、生产者等等。
- 框架集成:Celery易于和web框架集成,如django-celery,web2py-celery、tornado-celery等等。
- 强大的调度功能:Celery Beat进程来实现强大的调度功能,可以指定任务在若干秒后或一个时间点来执行,也可以基于单纯的时间间隔或支持分钟、小时、每周的第几天、每月的第几天等等,用crontab表达式来使用周期任务调度。
- 易监控:可以方便地查看定时任务的执行情况,如执行是否成功,当前状态、完成任务花费时间等,还可以使用功能完备的管理后台或命令行添加、更新、删除任务,提供了完善的错误处理机制。
2. 安装Celery
推荐使用pip安装Celery,方式如下:
pip3 install celery
# 或者,该方式安装celery时,捆绑了一组特性依赖:librabbitmq,redis,auth,msgpack
pip3 install celery[librabbitmq,redis,auth,msgpack]以下是可用的捆绑,供使用时做参考:
序列化
celery[auth]:用于使用auth安全序列化程序。
celery[msgpack]:用于使用 msgpack 序列化程序。
celery[yaml]:用于使用 yaml 序列化程序。
传输和后端
celery[librabbitmq]:用于使用 librabbitmq C 库。
celery[redis]:使用 Redis 作为消息传输或结果后端。
celery[sqs]:使用 Amazon SQS 作为消息传输(实验性)。
celery[tblib]:用于使用该task_remote_tracebacks功能。
celery[memcache]:使用 Memcached 作为结果后端(使用pylibmc)
celery[pymemcache]:使用 Memcached 作为结果后端(纯 Python 实现)。
celery[cassandra]:使用 Apache Cassandra 作为 DataStax 驱动程序的后端。
celery[couchbase]:使用 Couchbase 作为结果后端。
celery[arangodb]:使用 ArangoDB 作为结果后端。
celery[elasticsearch]:使用 Elasticsearch 作为结果后端。
celery[riak]:使用 Riak 作为结果后端。
celery[dynamodb]:使用 AWS DynamoDB 作为结果后端。
celery[zookeeper]:使用 Zookeeper 作为消息传输。
celery[sqlalchemy]:使用 SQLAlchemy 作为结果后端(支持)。
celery[consul]:使用 Consul.io 键/值存储作为消息传输或结果后端(实验性)。
celery[django]:指定 Django 支持可能的最低版本。
使用源代码安装如下:(celery · PyPI)
# 下载源代码文件
wget https://files.pythonhosted.org/packages/66/60/2713f5be1906b81d40f823f4c30f095f7b97b9ccf3627abe1c79b1e2fd15/celery-5.1.2.tar.gz
# 解压
tar zxvf celery-5.1.2.tar.gz
# 进入目录
cd celery-5.1.2
# 构建
python3 setup.py build
# 安装,注意权限,可在前面添加sudo
python3 setup.py install3. 安装RabbitMQ或Redis
3.1 安装redis
本文将以redis作为broker
以Ubuntu为例,其他操作系统可参考RabbitMQ官网:Downloading and Installing RabbitMQ — RabbitMQ
在Ubuntu系统安装redis可以使用一下命令
sudo apt-get update
sudo apt-get install redis-server启动redis
redis-server查看redis是否启动
redis-cli上面的命令将打开以下终端
redis 127.0.0.1:6379>其中127.0.0.1是本机ip,6379是redis服务端口号,现在输入ping命令:
redis 127.0.0.1:6379> ping
PONG以上说明redis已经安装成功。以下是通过源码包安装redis。
wget http://download.redis.io/releases/redis-6.0.6.tar.gz
tar xzf redis-6.0.6.tar.gz
cd redis-6.0.6
makemake命令执行完,在redis-6.0.6/src目录下会出现编译后的Redis服务程序redis-server和启动客户端程序redis-cli
如下命令启动Redis,此命令会一直处于占用状态,我们再重新开一个命令行连接
cd redis-6.0.6/src
./redis-server ../redis.conf
注意:如果redis-server 后面指定配置文件,则会以默认的配置启动redis服务。此处我们是使用的指定的默认redis配置文件。也可以根据需要使用自己的配置文件。
启动redis服务后,显示如下:
以上表示启动成功,可以使用测试客户端程序redis-cli和redis进行交互了,例如:
# 有$ 的一行表示shell命令
$ cd src
$ ./redis-cli
redis> set foo bar
OK
redis> get foo
"bar"配置celery的BROKER_URL,redis的默认连接URL如下:
BROKER_URL = 'redis://localhost:6379/0'3.2 安装RabbitMQ
这里仍以Ubuntu为例
Centos7.6系统参考:CentOS7.6 安装RabbitMQ_大帅的博客-CSDN博客
首先安装erlang。由于RabbitMQ需要Erlang语言的支持,因此需要先安装Erlang,执行命令:
sudo apt-get install erlang-nox再安装RabbitMQ
sudo apt-get update
sudo apt-get install rabbitmq-server启动、关闭、重启、状态RabbitMQ服务的命令如下:
# 启动
sudo rabbitmq-server start
# 关闭
sudo rabbitmq-server stop
# 重启
sudo rabbitmq-server restart
# 查看rabbitmq状态
sudo rabbitmqctl status要使用celery,需要创建一个RabbitMQ用户和虚拟主机,并且允许用户访问改虚拟主机。
# 创建rabbitmq的用户名为myuser,密码为mypassword,请自行设置
sudo rabbitmqctl add_user myuser mypassword
# 创建虚拟主机
sudo rabbitmqctl add_vhost myvhost
# 设置权限
sudo rabbitmqctl set_permissions -p myvhost myuser ".*" ".*" ".*"RabbitMQ是默认的中间人的URL位置,生产环境根据实际情况修改即可。
BROKER_URL = 'amqp://guest:guest@localhost:5672'4. 第一个Celery程序
我们选redis作为broker,首先要修改一下redis的配置文件redis.conf,修改bind=127.0.0.1为bind=0.0.0.0,意思是允许远程访问Redis数据库。修改完毕需要重启一下redis服务。
# sudo apt-get 方式安装重启
service redis-server restart
# 源码安装重启
src/redis-server ../redis.conf
启动成功后检查:
[root@python celery_demo]# ps -elf | grep redis
0 S root 38987 110789 0 80 0 - 28203 pipe_w 06:19 pts/2 00:00:00 grep --color=auto redis
4 S root 104561 2276 0 80 0 - 40606 ep_pol 04:00 pts/0 00:00:23 src/redis-server 127.0.0.1:6379
说明已成功启动。
现在来编写一个Celery程序
【示例1】(my_first_celery.py)
# encoding=utf-8
from celery import Celery
import time
app = Celery(
'tasks',
broker='redis://127.0.0.1:6379/0',
backend='redis://127.0.0.1:6379/0'
)
@app.task
def add(x, y):
time.sleep(3) # 模拟耗时操作
res = x + y
print(f"x + y = {res}")
return res
代码说明:
Celery()的第一个参数为当前模块的名称,只有在 __main__ 模块中定义任务时才会生产名称;第二个参数指定了中间人broker,第三个参数指定了后端存储。实现了一个add函数,该函数模拟了耗时操作,等待3秒,传入两个参数并返回之和,使用app.task来装饰该函数。
接下来我们启动任务执行单元worker。
celery -A my_first_celery worker -l info命令说明:
-A 表示程序段模块名称,worker表示启动一个执行单元,-l是指-level,表示打印的日志等级,可以使用celery -help命令查看celery命令的帮助文档。
启动成功后显示如下:
如果不想用celery命令启动worker,则可以直接使用文件驱动,修改my_first_celery.py如下所示:
【实例2】使用入口函数启动(my_first_celery.py)
添加了app.start()启动
# encoding=utf-8
from celery import Celery
import time
app = Celery(
'tasks',
broker='redis://127.0.0.1:6379/0',
backend='redis://127.0.0.1:6379/0'
)
@app.task
def add(x, y):
time.sleep(3) # 模拟耗时操作
res = x + y
print(f"x + y = {res}")
return res
if __name__ == '__main__':
app.start()
然后再命令中执行python3 my_first_celery.py worker即可,启动后的界面和使用celery命令的结果是一致的。
接下来,编写任务调度程序:start_task.py
from my_first_celery import add # 导入任务函数add
import time
# delay异步调用,因为add函数里面会等待3秒,这里调用不会阻塞,程序会立即向下执行
result = add.delay(12, 12)
# ready方法检查任务是否执行完毕,此处会循环检查
while not result.ready():
print(time.strftime("%H:%M:%S"))
time.sleep(1)
print(result.get()) # 获取任务返回的结果,也就是两个数相加之和
print(result.successful()) # 判断任务是否成功执行
执行 python3 start_task.py 得到以下结果:
[root@python celery_demo]# python3 start_task.py
06:48:05
06:48:06
06:48:07
24
True
等待了3秒后(有可能会打印4次秒数),任务返回了24,并且成功完成。此时worker界面增加的信息如下:
[2021-09-11 06:48:05,236: INFO/MainProcess] Task my_first_celery.add[41425cd6-63c8-41df-bb74-74fd0c5c7438] received
[2021-09-11 06:48:08,242: WARNING/ForkPoolWorker-8] x + y = 24
[2021-09-11 06:48:08,242: WARNING/ForkPoolWorker-8]
[2021-09-11 06:48:08,244: INFO/ForkPoolWorker-8] Task my_first_celery.add[41425cd6-63c8-41df-bb74-74fd0c5c7438] succeeded in 3.007353223998507s: 24
启动 41425cd6-63c8-41df-bb74-74fd0c5c7438 是 taskid ,只要指定了backend,根据这id就可以随时去backend查找运行结果。使用方法如下:
>>> from my_first_celery import add
>>> taskid='41425cd6-63c8-41df-bb74-74fd0c5c7438'
>>> add.AsyncResult(taskid).get()
24
>>>
或者
>>> from celery.result import AsyncResult
>>> AsyncResult(taskid).get()
24
5. 第一个Celery工程项目
上面的celery程序非常简单,实际的项目开发应该是模块化的,程序的功能分散在对个主文件中,Celery也不例外。下面扩展第一个Celery程序。
新建myCeleryProj目录,并在目录中新建__init__.py、app.py、settings.py、tasks.py文件,其中__init__.py保持为空即可,其作用是把myCeleryProj目录当成一个python包,让python程序导入。

【示例3】第一个工程项目(myCeleryPro)
setting.py存放配置信息,如下所示:(更多配置项查看官网文档:First Steps with Celery — Celery 5.2.0b3 documentation)
# 使用redis 作为消息代理
broker_url = 'redis://127.0.0.1:6379/0'
# 任务结果存在Redis
result_backend = 'redis://127.0.0.1:6379/0'
# 读取任务结果一般性能要求不高,所以使用了可读性更好的JSON
result_serializer = 'json'
app.py是celery worker是入口,如下所示:
# 引用标准库,而不是当前目录下的同名文件。
from __future__ import absolute_import
from celery import Celery
# 初始化app,导入任务
app = Celery("myCeleryProj", include=["myCeleryProj.tasks"])
# 加载配置
app.config_from_object("myCeleryProj.settings")
if __name__ == "__main__":
app.start()
tasks.py主要存放具体执行的任务,如下所示:
from myCeleryProj.app import app
import time
@app.task
def add(x, y):
time.sleep(3) # 模拟耗时操作
s = x + y
print(f"x + y = {s}")
return s
@app.task
def taskA():
print("taskA")
time.sleep(3)
@app.task
def taskB():
print("taskB")
time.sleep(3)
在myCeleryProj的同级目录下执行如下命令,运行工程项目。
celery -A myCeleryProj.app worker -c 3 -l info-c 3 表示启用三个子进程执行该队列中的任务。运行结果如下:
也可以设置后台运行并指定日志文件
celery -A myCeleryProj.app worker -logfile /tmp/celery -l info -c 3现在我们已经启动了worker,从运行的打印输出可以看到有三个任务:
[tasks]
. myCeleryProj.tasks.add
. myCeleryProj.tasks.taskA
. myCeleryProj.tasks.taskB
接下来手动执行异步调用。
>>> from myCeleryProj.tasks import *
>>> add.delay(5,6);taskA.delay();taskB.delay()
<AsyncResult: b2729c4e-84f9-4247-b3aa-79a71d746e41>
<AsyncResult: 12ac1a74-08b3-40a3-91be-d096de9d5651>
<AsyncResult: 879dbfb7-f216-4e46-b83f-020985b7efec>
>>>
这里的add.delay(5,6);taskA.delay();taskB.delay()写在一行是在于同时发出异步执行的命令,worker界面新增的信息如下:
[2021-09-11 10:34:50,423: INFO/MainProcess] Task myCeleryProj.tasks.add[b2729c4e-84f9-4247-b3aa-79a71d746e41] received
[2021-09-11 10:34:50,424: INFO/MainProcess] Task myCeleryProj.tasks.taskA[12ac1a74-08b3-40a3-91be-d096de9d5651] received
[2021-09-11 10:34:50,426: WARNING/ForkPoolWorker-1] taskA
[2021-09-11 10:34:50,426: WARNING/ForkPoolWorker-1]
[2021-09-11 10:34:50,426: INFO/MainProcess] Task myCeleryProj.tasks.taskB[879dbfb7-f216-4e46-b83f-020985b7efec] received
[2021-09-11 10:34:50,428: WARNING/ForkPoolWorker-3] taskB
[2021-09-11 10:34:50,428: WARNING/ForkPoolWorker-3]
[2021-09-11 10:34:53,429: WARNING/ForkPoolWorker-2] x + y = 11
[2021-09-11 10:34:53,430: WARNING/ForkPoolWorker-2]
[2021-09-11 10:34:53,453: INFO/ForkPoolWorker-2] Task myCeleryProj.tasks.add[b2729c4e-84f9-4247-b3aa-79a71d746e41] succeeded in 3.028609608998522s: 11
[2021-09-11 10:34:53,453: INFO/ForkPoolWorker-1] Task myCeleryProj.tasks.taskA[12ac1a74-08b3-40a3-91be-d096de9d5651] succeeded in 3.027193174002605s: None
[2021-09-11 10:34:53,453: INFO/ForkPoolWorker-3] Task myCeleryProj.tasks.taskB[879dbfb7-f216-4e46-b83f-020985b7efec] succeeded in 3.0251767819972883s: None
可以看出,worker在10:34:50同时接收到了三个任务,由于并发数是3,且三个任务都执行了time.sleep(3)等待3秒的耗时操作,因此他们都在10:34:53打印了相应的信息并退出。大家可以将并发数设置为1再试验一下运行结果。
调用任务task有三种方法:
(1)apply_async()方法,发送一个task到任务队列,支持更多的参数控制,如:add.apply_async(countdown=10, expires=120)表示执行add函数的时间限制最多为10秒,add函数的有效期为120秒。使用apply_async还支持回调,例如:
add.apply_async((2,2), link=add.s(16))Celery 支持将任务链接在一起,以便一个任务跟随另一个任务。回调任务将应用父任务的结果作为部分参数,这里第一个任务 (4) 的结果将被发送到一个新任务,该任务将前一个结果加 16,形成表达式 (2+2) + 16 = 20
(2)delay()方法,该方法是apply_async的快捷方式,提供便捷的异步调度,但是如果想要更多的参数控制,就必须使用apply_async方法。
(3)直接调用,相当于普通函数的调用,但是不会再worker上执行。
6. Celery框架
前面的知识对Celery程序进行了初探,有了初步了解后,我们再来看看Celery的架构,有助于深入理解Celery。
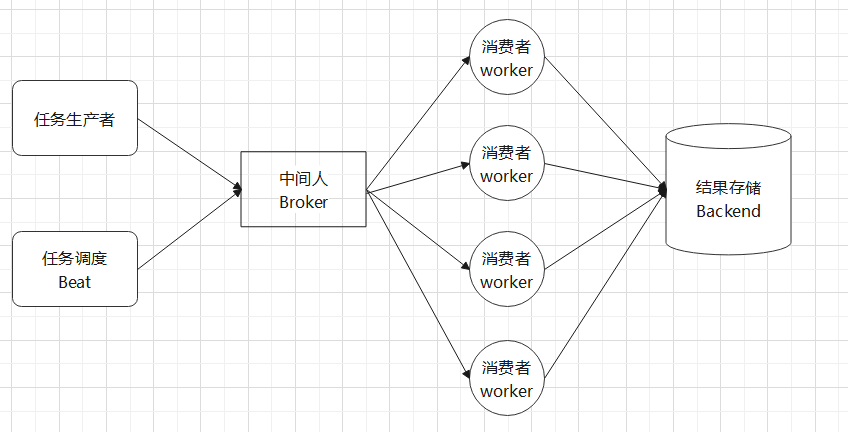
任务生产者生产任务并将任务发送给你中间人worker,有多个消费者,即执行单元worker持续地监控消息中间人,如有属于自己队列的任务需要执行,就从中间人取出作业名称,查找对应的函数代码并执行。执行完成后将结果存储在Backend。这里的worker可以分不熟部署。彼此之间是独立的。
任务调度器Beat:Celery Beat进程会读取配置文件的内容,然后将配置中需要执行的任务发送给中间人。
7. celery路由任务分配队列
Celery非常容易设置和运行,它通常会使用默认名为Celery的队列(可以通过CELERY_DEFAULT_QUEUE修改)来存放任务。Celery支持同时运行多个队列,还可以使用优先级不同的队列来确保高优先级的任务不需要等待就立即执行。
基于前面的示例,我们来实现不同队列来执行不同的任务:任务add在队列default执行,任务taskA在队列tasks_A执行,任务taskB在队列tasks_B执行。
【示例4】将任务自动分配队列
首先修改配置文件setting.py
from kombu import Queue
task_queues= ( # 定义任务队列
Queue("default", routing_key="task.#"), # 路由键以“task.”开头的消息都进default队列
Queue("tasks_A", routing_key="A.#"), # 路由键以“A.”开头的消息都进tasks_A队列
Queue("tasks_B", routing_key="B.#"), # 路由键以“B.”开头的消息都进tasks_B队列
)
task_routes = (
[
("myCeleryProj.tasks.add", {"queue": "default"}), # 将add任务分配至队列 default
("myCeleryProj.tasks.taskA", {"queue": "tasks_A"}), # 将taskA任务分配至队列 tasks_A
("myCeleryProj.tasks.taskB", {"queue": "tasks_B"}), # 将taskB任务分配至队列 tasks_B
],
)
# 使用redis 作为消息代理
broker_url = 'redis://127.0.0.1:6379/0'
# 任务结果存在Redis
result_backend = 'redis://127.0.0.1:6379/0'
# 读取任务结果一般性能要求不高,所以使用了可读性更好的JSON
result_serializer = 'json'
一次启动对个队列,执行以下命令:
celery -A myCeleryProj.app worker -Q default,tasks_A,tasks_B -l info为了方便演示,我们开了三个终端,分别启动三个队列
celery -A myCeleryProj.app worker -Q default -l info
celery -A myCeleryProj.app worker -Q tasks_A -l info
celery -A myCeleryProj.app worker -Q tasks_B -l info然后再开一个终端来调用task
>>> from myCeleryProj.tasks import *
>>> add.delay(1,1);taskA.delay();taskB.delay()
<AsyncResult: 0b0aaef7-c8af-4dc0-8bd3-0224d720f9bc>
<AsyncResult: 5ac76092-55f6-4a0b-bf1f-63cae36832a9>
<AsyncResult: f11e0f76-cf3a-426d-bc29-438b94288da6>
可以看到三个终端都有一个任务的输出显示



任务的路由:前面的代码中觉定任务具体在哪个队列 运行是通过下面的代码去分配的
task_routes = (
[
("myCeleryProj.tasks.add", {"queue": "default"}), # 将add任务分配至队列 default
("myCeleryProj.tasks.taskA", {"queue": "tasks_A"}), # 将taskA任务分配至队列 tasks_A
("myCeleryProj.tasks.taskB", {"queue": "tasks_B"}), # 将taskB任务分配至队列 tasks_B
],
)实际生产环境可能有对个任务需要路由,可以使用正则的方式批量分配任务到队列中
将tasks.py中所有的任务分配到队列default
task_routes = (
[
("myCeleryProj.tasks.*", {"queue": "default"}),
],
)将任务taskA和taskB分配到队列task_A中,任务add分配到default中
task_routes = (
[
# 将add任务分配至队列 default
(
"myCeleryProj.tasks.add",
{"queue": "default", "routing_key": "task.default"}
),
# 将taskA taskB任务分配至队列 tasks_A
(
re.compile(r'myCeleryProj\.tasks\.(taskA|taskB)'),
{"queue": "tasks_A", "routing_key": "A.#"}),
],
)更多有关路由的信息参考:Routing Tasks — Celery 5.2.0b3 documentation
8. Celery Beat自动任务调度
前面演示的任务调度都是手动出发的,使用Celery Beat可以自动调度任务。
Celery Beat是Celery的调度器,可定期启动任务,然后由集群中的可用工作节点worker执行这些任务。默认情况下,Beat进程读取配置文件中的CELERYBEAT_SCHEDULE的设置,也可以自定义存储,比如将启动任务的规则存储在SQL数据库中。请确保每次调度任务可以运行一个调度程序,否则任务将被重复执行。使用集群的方式意味着调度不需要同步,服务可以在不使用锁的情况下运行。
先明确一个概念--时区,间隔性的任务调度默认使用UTC时区,也可以通过设置来改变时区:
# 通过配置文件修改
timezone = "Asia/Shanghai"
# 通过app配置修改
app.conf.timezone = "Asia/Shanghai"时区的设置必须加入Celery的app中,默认的调度器(将调度计划存储在celerybeat-schedule文件中)将自动检测时区是否改变,如果时区改变,则自动重置调度计划。其他调度器可能不会自动重置,比如Django数据库调度器就需要手动重置调度计划。
【示例5】Celery调度
仍基于myCeleryProj项目,修改setting文件
from kombu import Queue
from celery.schedules import crontab, timedelta
task_queues = ( # 定义任务队列
Queue("default", routing_key="task.#"), # 路由键以“task.”开头的消息都进default队列
Queue("tasks_A", routing_key="A.#"), # 路由键以“A.”开头的消息都进tasks_A队列
Queue("tasks_B", routing_key="B.#"), # 路由键以“B.”开头的消息都进tasks_B队列
)
task_routes = (
[
("myCeleryProj.tasks.add", {"queue": "default"}), # 将add任务分配至队列 default
("myCeleryProj.tasks.taskA", {"queue": "tasks_A"}), # 将taskA任务分配至队列 tasks_A
("myCeleryProj.tasks.taskB", {"queue": "tasks_B"}), # 将taskB任务分配至队列 tasks_B
],
)
# 使用redis 作为消息代理
broker_url = 'redis://127.0.0.1:6379/0'
# 任务结果存在Redis
result_backend = 'redis://127.0.0.1:6379/0'
# 读取任务结果一般性能要求不高,所以使用了可读性更好的JSON
result_serializer = 'json'
# 修改时区
timezone = 'Asia/Shanghai'
# 任务调度
beat_schedule = {
"add": {
"task": "myCeleryProj.tasks.add",
"schedule": timedelta(seconds=10), # 定义间隔为5s的任务
"args": (10, 16),
},
"taskA": {
"task": "myCeleryProj.tasks.taskA",
"schedule": crontab(hour=15, minute=9), # 定义间隔为对应时区下14:09分执行的任务
},
"taskB": {
"task": "myCeleryProj.tasks.taskB",
"schedule": crontab(hour=15, minute=9), # 定义间隔为对应时区下14:09分执行的任务
},
}
打开两个终端,一个执行worker
celery -A myCeleryProj.app worker -Q tasks_A,tasks_B,default -l info执行beat调度
celery -A myCeleryProj.app beat
work输出结果:
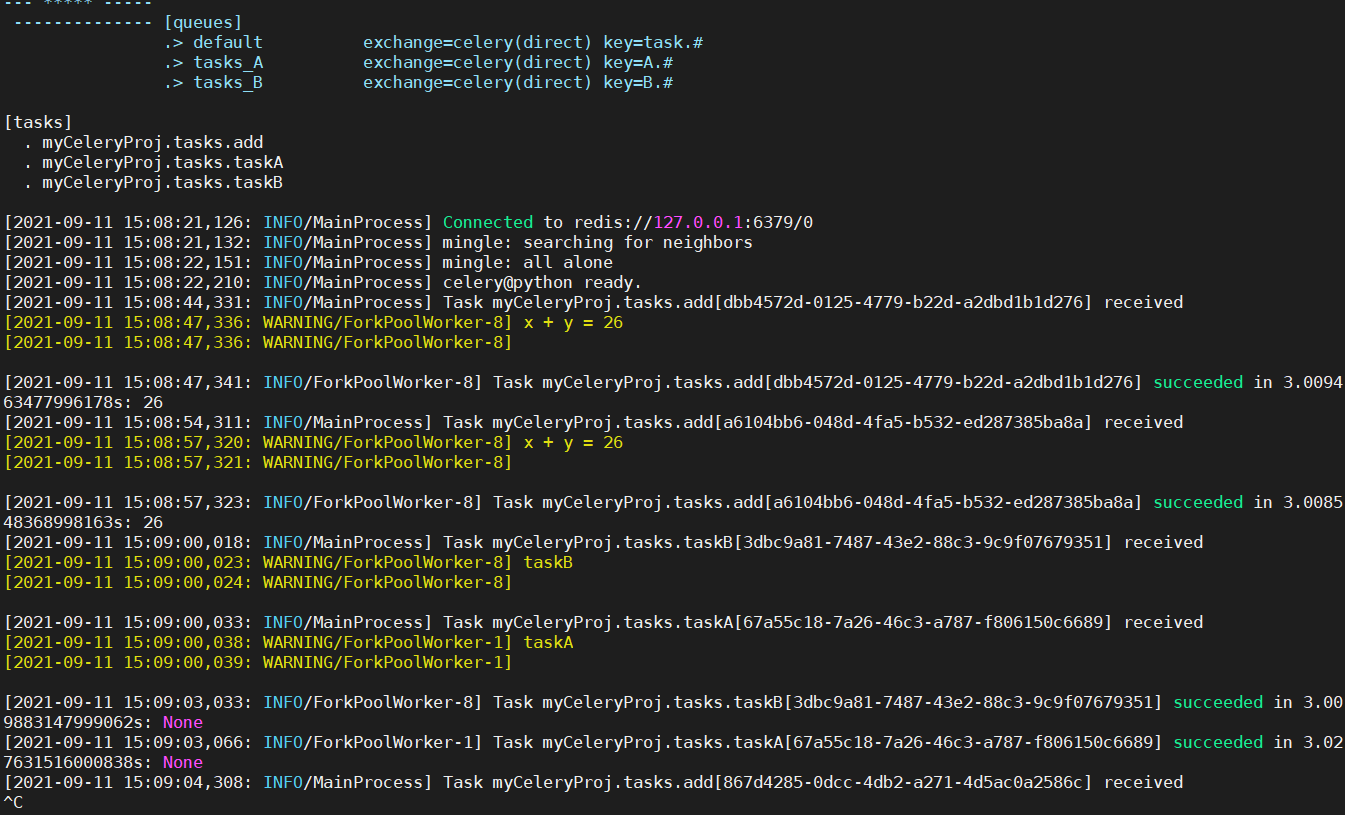
更多定时任务调度参考:Periodic Tasks — Celery 5.2.0b3 documentation
9. Celery 远程调用
前述的任务调度都是在本机在调度,在实际应用中,可能有许多任务需要远程调用,如主机C上的程序需要调用主机A和主机B上的任务。本节我们仍基于myCeleryProj目录下的代码来实现主机C上远程调用主机A和主机B
- 主机C的ip地址为:192.168.41.41
- 主机A的ip地址为:192.168.41.42
- 主机B的ip地址为:192.168.41.43
首先修改setting.py,使得任务taskA运行在队列task_A上,任务taskB运行在task_B上,中间人broker均指向主机C上的redis数据库:redis://192.168.41.41:6379:0,不一定必须在主机C上启用redis数据库,redis数据库可以运行在任意一台主机上,只要确保能够远程访问即可。
完整的setting.py如下:
from kombu import Queue
timezone = "Asia/Shanghai"
task_queues= ( # 定义任务队列
Queue("default", routing_key="task.#"), # 路由键以“task.”开头的消息都进default队列
Queue("tasks_A", routing_key="A.#"), # 路由键以“A.”开头的消息都进tasks_A队列
Queue("tasks_B", routing_key="B.#"), # 路由键以“B.”开头的消息都进tasks_B队列
)
task_routes = (
[
("myCeleryProj.tasks.add", {"queue": "default"}), # 将add任务分配至队列 default
("myCeleryProj.tasks.taskA", {"queue": "tasks_A"}), # 将taskA任务分配至队列 tasks_A
("myCeleryProj.tasks.taskB", {"queue": "tasks_B"}), # 将taskB任务分配至队列 tasks_B
],
)
# 使用redis 作为消息代理
broker_url = 'redis://192.168.41.41:6379/0'
# 任务结果存在Redis
result_backend = 'redis://192.168.41.41:6379/0'
# 读取任务结果一般性能要求不高,所以使用了可读性更好的JSON
result_serializer = 'json'
为了区别是在哪一台主机执行的任务,我们再tasks.py中添加了一个函数get_host_ip,该函数只是用来获取本机的ip而已。
完整的tasks.py代码
from myCeleryProj.app import app
import time
import socket
def get_host_ip():
"""
查询本机ip地址
:return: ip
"""
try:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.connect(("8.8.8.8", 80))
ip = s.getsockname()[0]
finally:
s.close()
return ip
@app.task
def taskA():
print("taskA begin...")
print(f"主机IP: {get_host_ip()}, 等待3秒")
time.sleep(3)
print("taskA done.")
@app.task
def taskB():
print("taskB begin...")
print(f"主机IP: {get_host_ip()}, 等待3秒")
time.sleep(3)
print("taskB done.")
(1)确保主机C上的redis数据已经启动,如有以下信息说明已经成功启动
[root@python celery_demo]# ps -elf | grep redis
4 S root 8152 7986 0 80 0 - 40606 ep_pol 04:14 pts/1 00:00:01 src/redis-server 127.0.0.1:6379
0 S root 12933 8222 0 80 0 - 28204 pipe_w 04:27 pts/2 00:00:00 grep --color=auto redis
(2)将myCeleryProj目录分别复制到三台主机上。
scp -r myCeleryProj root@192.168.41.42:/opt/celery_demo/
scp -r myCeleryProj root@192.168.41.43:/opt/celery_demo/(3)在主机A上启用worker,监控队列task_A(前提是已经安装完python库celery和redis)
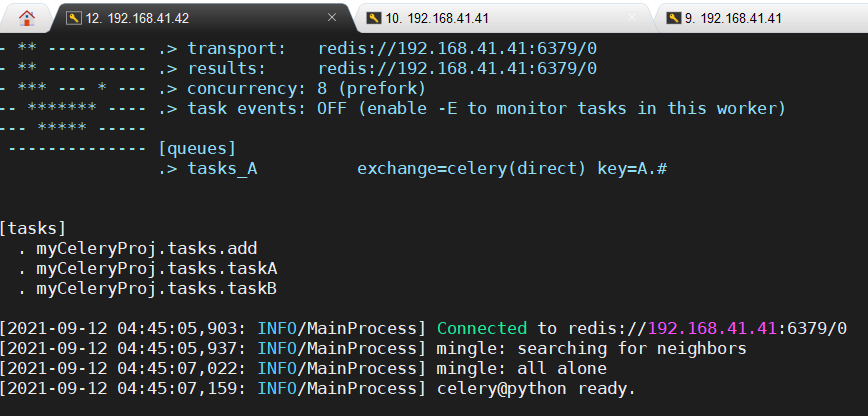
celery -A myCeleryProj.app worker -Q tasks_A -l info在主机B上执行同样的操作:
celery -A myCeleryProj.app worker -Q tasks_B -l info启动成功会提示连接到192.168.41.41的redis数据库
(4)在主机C上编写调用程序start_tasks.py
from myCeleryProj.tasks import taskA, taskB
import time
# 异步执行 方法一
# resultA = taskA.delay()
# resultB = taskB.delay()
# 异步执行 方法一
resultA = taskA.apply_async()
resultB = taskB.apply_async(args=[])
resultC = taskA.apply_async(queue='tasks_B')
while not (resultA.ready() and resultB.ready()): # 循环检查任务是否执行完毕
time.sleep(1)
print(resultA.successful()) # 判断任务是否成功执行
print(resultB.successful()) # 判断任务是否成功执行
上述代码中的第11行可通过指定queue='tasks_B'的方式在调用任务时改变taskA执行的列队,这在实际应用中是非常方便的。
执行 python3 start_tasks,py得到如下结果:
[root@python celery_demo]# python3 start_task.py
True
True
主机A、主机B上worker运行情况如下:
[2021-09-12 05:00:29,467: INFO/MainProcess] Task myCeleryProj.tasks.taskA[93bc569f-e542-4d0e-99ba-94bef9db1d22] received
[2021-09-12 05:00:29,468: WARNING/ForkPoolWorker-8] taskA begin...
[2021-09-12 05:00:29,469: WARNING/ForkPoolWorker-8]
[2021-09-12 05:00:29,469: WARNING/ForkPoolWorker-8] 主机IP: 192.168.41.41, 等待3秒
[2021-09-12 05:00:29,469: WARNING/ForkPoolWorker-8]
[2021-09-12 05:00:32,474: WARNING/ForkPoolWorker-8] taskA done.
[2021-09-12 05:00:32,475: WARNING/ForkPoolWorker-8]
[2021-09-12 05:00:32,481: INFO/ForkPoolWorker-8] Task myCeleryProj.tasks.taskA[93bc569f-e542-4d0e-99ba-94bef9db1d22] succeeded in 3.0132306259997677s: None
[2021-09-12 04:57:45,926: INFO/MainProcess] Task myCeleryProj.tasks.taskB[f5503972-919d-4271-99d8-a73268a8007c] received
[2021-09-12 04:57:45,943: INFO/MainProcess] Task myCeleryProj.tasks.taskA[8621d934-cc05-43a5-909c-a3e473d8fd88] received
[2021-09-12 04:57:46,099: WARNING/ForkPoolWorker-8] taskB begin...
[2021-09-12 04:57:46,099: WARNING/ForkPoolWorker-1] taskA begin...
[2021-09-12 04:57:46,100: WARNING/ForkPoolWorker-8]
[2021-09-12 04:57:46,100: WARNING/ForkPoolWorker-1]
[2021-09-12 04:57:46,100: WARNING/ForkPoolWorker-8] 主机IP: 192.168.41.43, 等待3秒
[2021-09-12 04:57:46,100: WARNING/ForkPoolWorker-1] 主机IP: 192.168.41.43, 等待3秒
[2021-09-12 04:57:46,100: WARNING/ForkPoolWorker-8]
[2021-09-12 04:57:46,100: WARNING/ForkPoolWorker-1]
[2021-09-12 04:57:49,106: WARNING/ForkPoolWorker-8] taskB done.
[2021-09-12 04:57:49,106: WARNING/ForkPoolWorker-1] taskA done.
[2021-09-12 04:57:49,106: WARNING/ForkPoolWorker-1]
[2021-09-12 04:57:49,106: WARNING/ForkPoolWorker-8]
[2021-09-12 04:57:50,161: INFO/ForkPoolWorker-8] Task myCeleryProj.tasks.taskB[f5503972-919d-4271-99d8-a73268a8007c] succeeded in 4.086183274000177s: None
[2021-09-12 04:57:50,127: INFO/ForkPoolWorker-1] Task myCeleryProj.tasks.taskA[8621d934-cc05-43a5-909c-a3e473d8fd88] succeeded in 4.085574190999978s: None
可以看到主机B上运行的队列tasks_B中,taskA任务也被执行了
10. 监控与管理Celery
Celery有两种监控工具:命令行工具和Web实时监控工具Flower
1. Celery命令行实用工具
Celery命令行实用工具可以用来检查和管理工作节点worker和任务。我们可以列出所有可用的命令:
celery help
# 或者列出具体命令的帮助信息
celery <command> --help下面介绍几种常用的命令及其功能。
(1)shell环境命令。进入含有celery变量的python解释器环境,Celery变量有当前的celery,app,task,除非设置了--without-tasks标志。可以在shell中直接调用taskA.delay(),相当于调试功能。
[root@python celery_demo]# celery -A myCeleryProj.app shell
Python 3.8.2 (default, Jun 15 2021, 01:08:16)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>> locals().keys()
dict_keys(['app', 'celery', 'Task', 'chord', 'group', 'chain', 'chunks', 'xmap', 'xstarmap', 'subtask', 'signature', 'taskA', 'taskB', '__builtins__'])
>>> app
<Celery myCeleryProj at 0x7f7982ce6a60>
>>> taskA
<@task: myCeleryProj.tasks.taskA of myCeleryProj at 0x7f7982ce6a60>
>>> taskA.delay()
<AsyncResult: e44e27b9-9c3f-42f2-bd2f-52893cc86220>
>>>
(2)status命令:在这个集群中列出激活的节点、
[root@python celery_demo]# celery -A myCeleryProj.app status
-> celery@python: OK
1 node online.
(3)purge命令:从所有配置的任务队列清除任务消息
celery -A myCeleryProj.app purge也可以指定要清除的任务队列
celery -A myCeleryProj.app purge -Q default,tasks_A或者排除指定的任务队列
celery -A myCeleryProj.app purge -X tasks_B(4)inspect active命令:列出激活的任务
celery -A myCeleryProj.app inspect active(5)inspect scheduled命令:列出计划任务
celery -A myCeleryProj.app inspect scheduled(6)inspect registered命令:列出已注册的任务
celery -A myCeleryProj.app inspect registered(7)inspect stats命令:列出worker的统计信息
celery -A myCeleryProj.app inspect stats(8)inspect query_task命令:通过id获取任务信息
celery -A myCeleryProj.app inspect query_task
# 也可以一次查询多个任务
celery -A myCeleryProj.app inspect query_task id1 id2 id3 ...(9)control enable_events/disable_event:启用/不启用事件
celery -A myCeleryProj.app control enable_events/disable_event(10)migrate命令:将任务由一个中间人broker转移到另一个中间人broker
celery -A myCeleryProj.app migrate redis://localhost amqp://localhost这个命令将把一个中间人上的所有任务迁移到另一个中间人上。由于这个命令是实验性的,因此在执行命令之前,要确保对重要数据的备份。
提示:inspect和contol默认对所有的worker生效,可单独指定一个worker或者一个worker的列表。命令如下:
celery -A myCeleryProj.app inspect -d w1@e.com,w2@e.com reserved
celery -A myCeleryProj.app control -d w1@e.com,w2@e.com enable_envents2. Web实时监控工具Flower
Flower是一个实时Web服务的celery监控和管理工具,其后续版本正在积极开发中,但对于celery监控来说已经是一个必不可少的工具。作为Celery推荐的监视器,它淘汰了Djang-Admin监视器、celerymon监视和基于ncurses的监视器。
Flower具有一下的特性:
-
用Celery事件实时监控
- 任务进程和历史
- 能够显示任务的详细信息(arguments, start time, runtime等)
- 图形化和统计
-
远程控制
- 查看worker状态和统计
- 关闭和重启worker实例
- 控制进程池大小,平滑配置(autoscale settings)
- 查看和修改一个worker实例消费的队列
- 查看当前正在运行的tasks
- 查看计划任务(ETA(估计到达的时间)/倒计时)
- 应用时间和速率限制
- 配置浏览器(Configuration viewer)
- 撤销或终止任务
-
Broker monitoring(中间人监控)
- 查看所有Celery 队列的统计
- 队列长度图
-
提供HTTP接口
- 列出worker
- 关闭一个worker
- 重启worker缓冲池
- 增加/减少/自动定量worker的缓冲池
- 从任务队列消费(取出任务执行)
- 停止从任务队列消费
- 列出任务列表/任务类型
- 获取任务信息
- 执行一个任务
- 按名称执行任务
- 获得任务结果
- 改变工作的软硬时间限制
- 改变任务的速率限制
- 撤销一个任务
Flower的使用方法
(1)使用pip安装Flower。
pip3 install flower(2)启动Flower,输入命令,若不添加--port参数,则默认端口是5555,端口号可以修改。
celery -A myCeleryProj.app flower --port=5555
# 也可以指定broker
celery -A myCeleryProj.app flower --port=5555 --broker=redis://127.0.0.1:6379/0启动成功显示如下
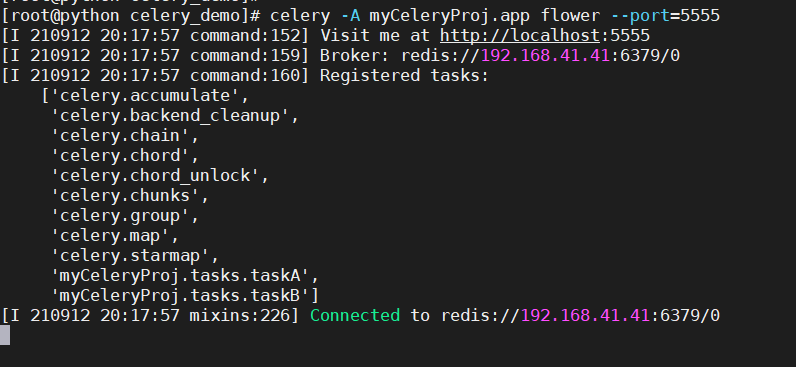
打开浏览器,访问地址http://192.168.41.41:5555,可以看到Flower的Web页面,如下所示。在Flower-Dashboard页面中可以看到worker节点的状态。激活的任务个数、已处理的任务数、失败的任务数、成功的任务数、重试的任务数,并且还可以检索。
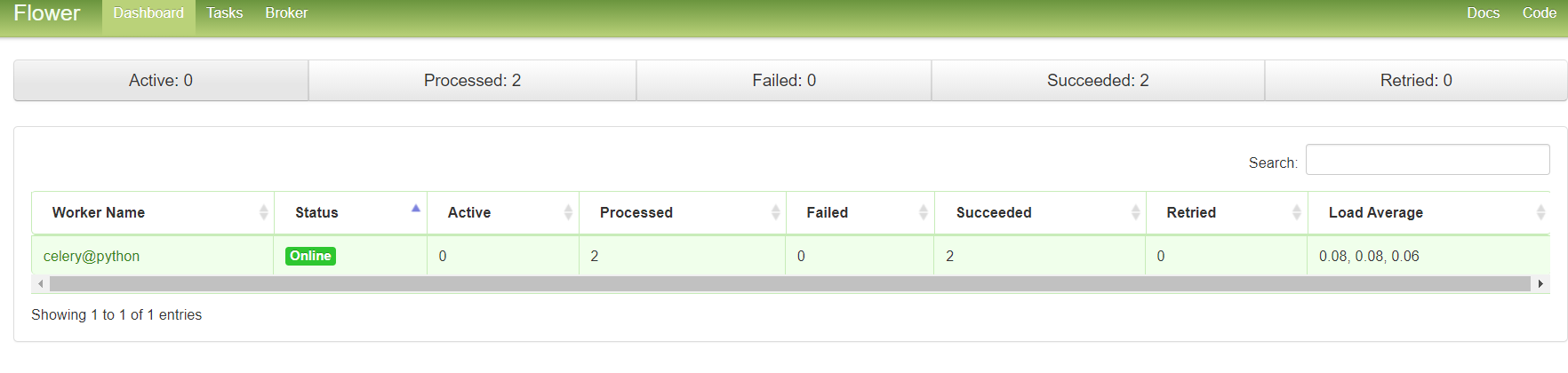
在Flower-Tasks页面,可以看到每一个任务更加详细的信息,包含任务的ID、状态、参数、返回值、开始时间、结束时间等。
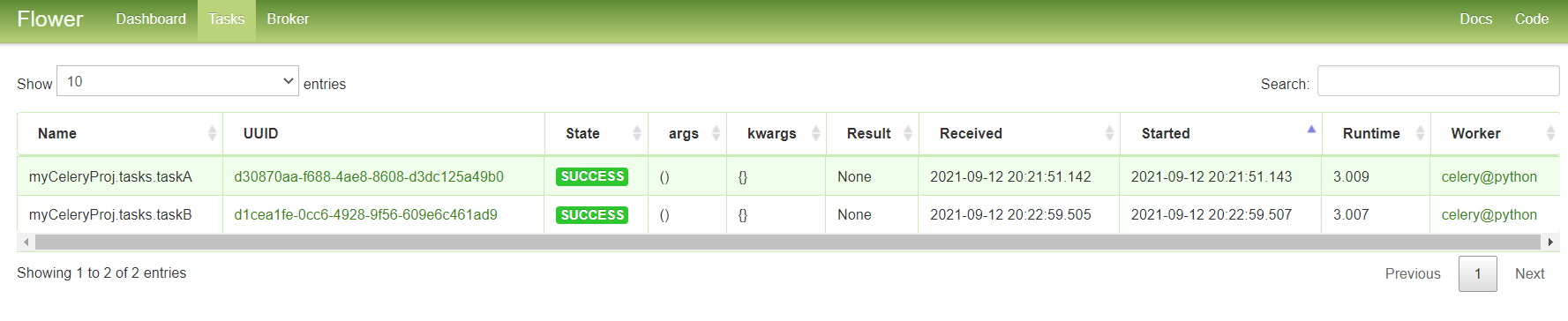
broker页面可以看到任务队列的信息
Flower还有更多功能,包括用户授权功能,更多详细信息访问官方网站:Flower - Celery monitoring tool — Flower 1.0.1 documentation
3. 从redis数据库查看任务相关信息
以redis作为broker,使用redis-cli命令列出消息队列中任务的个数
redis-cli -h HOST -p PORT -n DATABASE_NUMBER llen QUEUE_NAME如下显示:
[root@python src]# ./redis-cli -h 127.0.0.1 -p 6379 -n 0 keys \*
1) "celery-task-meta-6636043c-53e2-459a-952e-dc86ee0d1087"
2) "_kombu.binding.reply.celery.pidbox"
3) "celery-task-meta-8a1425dd-39fd-4617-a104-8685ca784beb"
4) "_kombu.binding.tasks_B"
5) "_kombu.binding.tasks_A"
6) "_kombu.binding.task_B"
7) "_kombu.binding.default"
8) "celery-task-meta-9458a481-6ce1-429c-a91b-88d74252269d"
9) "celery-task-meta-d1cea1fe-0cc6-4928-9f56-609e6c461ad9"
10) "_kombu.binding.celery"
11) "celery-task-meta-d30870aa-f688-4ae8-8608-d3dc125a49b0"
12) "celery-task-meta-93aca506-2d4f-4919-9a6b-be20071ce75c"
13) "celery"
14) "_kombu.binding.celeryev"
15) "celery-task-meta-93bc569f-e542-4d0e-99ba-94bef9db1d22"
16) "celery-task-meta-f5503972-919d-4271-99d8-a73268a8007c"
17) "_kombu.binding.celery.pidbox"
18) "_kombu.binding.task_A"
19) "celery-task-meta-e44e27b9-9c3f-42f2-bd2f-52893cc86220"
20) "celery-task-meta-8621d934-cc05-43a5-909c-a3e473d8fd88"
我们使用具体的键来获取任务的详细信息。
[root@python src]# ./redis-cli -n 0 get celery-task-meta-8621d934-cc05-43a5-909c-a3e473d8fd88
"{\"status\": \"SUCCESS\", \"result\": null, \"traceback\": null, \"children\": [], \"date_done\": \"2021-09-11T20:57:49.107062\", \"task_id\": \"8621d934-cc05-43a5-909c-a3e473d8fd88\"}"
















 1223
1223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











