






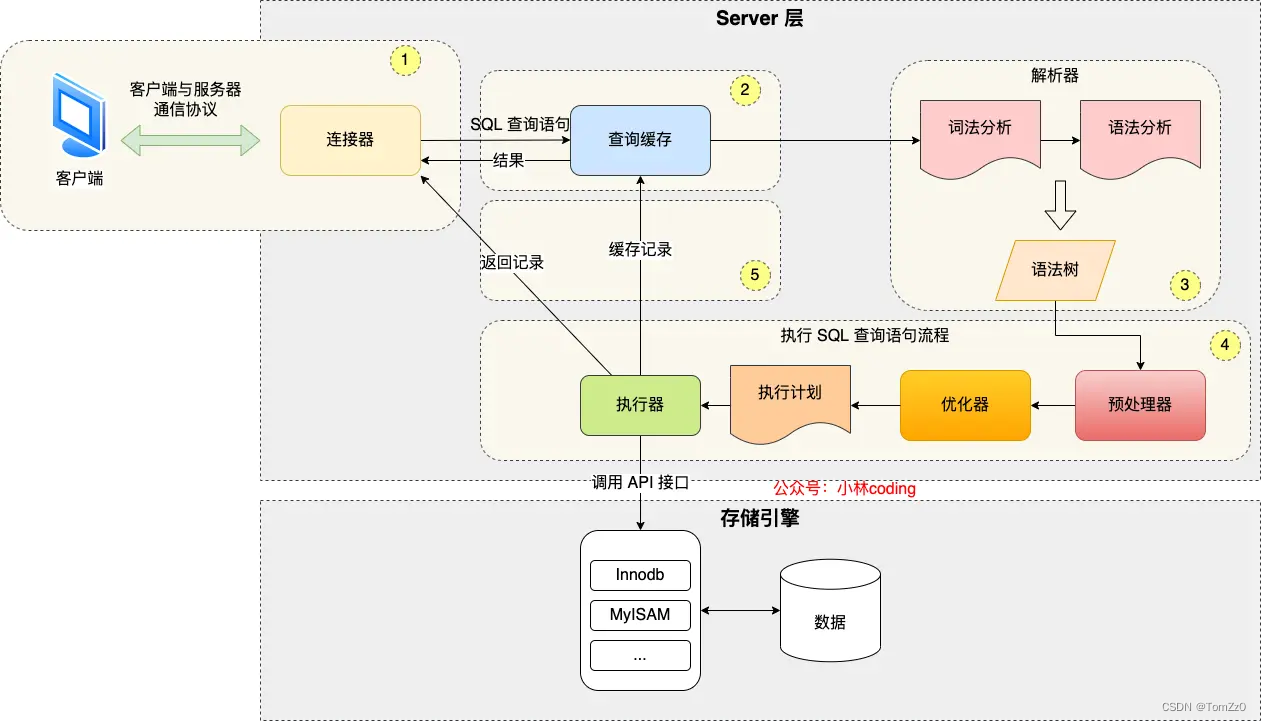
前置:sql执行流程
包括两层,server层和存储引擎层
server层:查询缓存,解析sql语句生成语法树,执行sql。在执行sql中包括预处理器,优化器和执行器。
预处理器:将查询字段展开(如select * 展开为具体字段)并检查字段是否合法
优化器:指定sql执行计划,如选择合适的索引
执行器:与存储引擎层交互,执行sql语句
存储引擎层:如InnoDB和MyISAM。以InnoDB为例,访问B+树数据结构获取记录(聚簇索引,二级索引等的访问都在存储引擎层)
1 limit查询原理
在server层获取到sql的结果,准备发送给客户端时才会进行limit操作。
比如如下sql
select * from user where sex = 'm' order by age limit 10000,10
在执行器调存储引擎api获取到一条数据时,会查看数据是否是第10000以后条数据,如果不是就不会发送到客户端,只进行计数。直到10001才会发送到客户端。也就是说,limit m n语句实际上也会访问前m条数据,然后返回后n条数据。
正是因为limit会扫描每条记录,因此如果我们查询的字段需要回表扫描,每一次查询都会拿着age列的二级索引查到的主键值去回表,limit 10000就会回表10000次,效率极低。所以如果我们使用explain查看查询计划:
explain select * from user where sex = 'm' order by age limit 10000,10
其往往不会走age索引,而是全表扫描+filesort,因为优化器认为选择age索引效率甚至不如全表扫描+排序。当翻页靠后时,查询会变得很慢,因为随着偏移量的增加,我们需要排序和扫描的非目标行数据也会越来越多,这些数据再扫描后都会被丢弃。
2 延迟查询解决深度分页问题
通过连接+子查询,上述查询语句可以改成
select * from user join(
select id from user where sex = 'm' order by age limit 10000,10
) as temp on user.id = temp.id
这条sql语句中子查询会先执行,这个查询会使用到age二级索引,而排序字段也是age,就省去了filesort这一步,因为索引就是有序的。对每一条记录,只需判断sex,最终分页获得目标id即可。通过id再进行表连接得到整行的数据。
总结就是连接+子查询使用到了覆盖索引,消去了filesort的开销。关于filesort以及更多细节可以看如下文章:深入理解MySQL分页查询机制,提升数据库查询效率
不过这种优化方法还取决于子查询返回数据的条数,如果子查询条件区分度低,返回的数据很多以至于表连接规模过大,那么大量时间又会被用在数据的读取和发送,优化效率不会得到显著的提升。
3 索引下推:
假设student表中有如下字段id,class,math,english,存在索引(class,math,english)
对于sql语句
select * from student where class < 20 and math = 140 and english = 140
该组合索引会先按照class排序,class相同时才会按math排序,english同样。显然class是范围查询,所以math和english不会走索引。
某一时刻存在如下记录:
id class math english
1 15 135 135
2 15 140 140
3 15 135 135
4 15 135 135
当没有开启索引下推时:server层调用存储引擎执行查询,对于每条记录只能对走了索引的字段进行初步过滤,然后回表查询整行数据,将结果交给server层执行器进行后续判断。对于本例,会根据class走组合索引,发现四个class字段全部小于20,于是会根据组合索引的主键值id(1,2,3,4)回表得到完整的四行数据,交给server层执行器进行后续math,english的判断。
当开启了索引下推时:server层调用存储引擎执行查询,不光会根据class过滤,存储引擎还会考虑math和english,这时就只有id为2的这条数据符合要求,存储引擎会根据主键值2回表查询,得到整行数据再返回给server层执行器。
对比两者,当开启索引下推时会根据索引字段过滤掉更多记录,减少后续数据量。















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









