









根据最近jieba分词的使用情况,对于英文句子的分词方式,整体感觉不如NLTK,因此通过本文具体记录NLTK如何安装,配置和基本的案例学习,实现了分词、词性标注、NER、句法分析、用户自定义分词方式等功能,供参考;同时由于nltk_data资源太大,下载速度太慢,这里也提供给大家,供研究使用。
1.安装NLTK,命令:pip install nltk
2.下载:直接从这里下载nltk_data资源,地址:https://download.csdn.net/download/hhue2007/86912857
3.解压:解压到当前文件夹后,将nltk_data拷贝到nltk能够识别到的任意一个路径下。
4.nltk能够识别的路径查找方法如下:
import nltk
print(nltk.find('.'))
5.进入nltk_data\tokenizers目录,解压punkt到当前文件夹
6.开始正常使用。NLTK的典型示例如下:
#coding:utf8
"""
Description:nltk分词操作详解
Author:hh by 2022-10-31
Prompt: code in Python3 env
Install:pip install nltk
"""
import nltk
from nltk.tokenize import MWETokenizer
from nltk.corpus import stopwords
from nltk.tokenize.punkt import PunktSentenceTokenizer, PunktParameters
# print(nltk.find('.'))
def cut_sentences_en(content):
punkt_param = PunktParameters()
abbreviation = ['i.e.', 'dr', 'vs', 'mr', 'mrs', 'prof', 'inc','99/22','North China Sea'] # 自定义的词典
punkt_param.abbrev_types = set(abbreviation)
tokenizer = PunktSentenceTokenizer(punkt_param)
tokenizer._params.abbrev_types
sentences = tokenizer.tokenize(content)
return sentences
if __name__=='__main__':
#********************1 nltk中文分词基本操作***********************************
print('='*40)
str="Geological Final Well Report Well LH35-13-1 Block 99/22,我来自北京大学"
token_list=nltk.word_tokenize(str)
print("\n1.分词: ", "$ ".join(token_list))
taged_list=nltk.pos_tag(token_list)
print("\n2.词性标注: ", taged_list)
#NER需要利用词性标注的结果
ners = nltk.ne_chunk(taged_list)
print("\n3.实体识别(NER): ", ners)
entity_list=nltk.chunk.ne_chunk(taged_list)
print("\n4.句法分析: ", entity_list)
str2='Geological Final Well Report Well LH35-13-1 Block 99/22, North China Sea,LH35-13-1 GEOLOGICAL COMPOSITE LOG,Geological Final Well Report'
tokenized_string = nltk.word_tokenize(str2)
mwe = [('Geological','Final','Well','Report','Well'),('99/','22'),('North','China','Sea'),('GEOLOGICAL','COMPOSITE','LOG')] # 添加这个短语(phrase)
mwe_tokenizer = nltk.tokenize.MWETokenizer(mwe)
result = mwe_tokenizer.tokenize(tokenized_string)
print("\n5.用户自定义分词: " + "/ ".join(result))
print('\n6.用户自定义分词(简称):',cut_sentences_en(str2))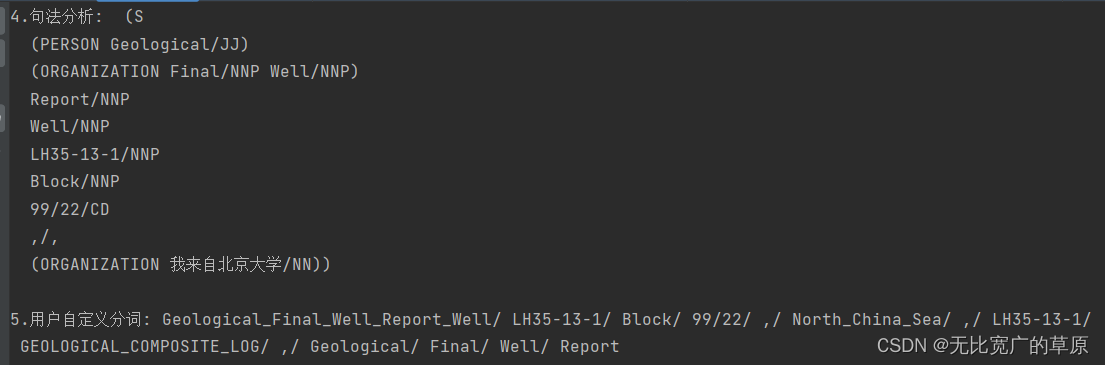















 815
815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











