







在java中,会用到很多集合类,种类很多,有的时候反而会让人感觉难以选择最优的数据结构,于是总结了一下各个集合类的用法,以便随时查阅。
先来一张集合类框图:
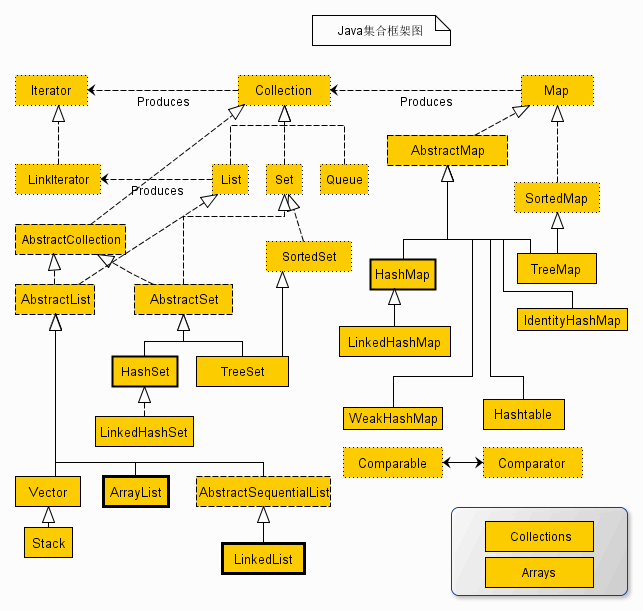
图片转自http://www.cnblogs.com/xwdreamer/archive/2012/05/30/2526822.html
本文只关注实现类的使用和注意事项 ,不涉及接口抽象类和源码分析,没什么干货,谅解。。
- Set类
HashSet: 元素在该集合中时无序的,插入顺序和遍历顺序不一样,同时,重复添加会造成覆盖。非线程安全,只能自己在外部进行控制;
TreeSet: 元素默认情况下按某种方式排序,若用户需要自定义排序,放入该集合中的元素需要实现Comparable接口,同样非线程安全;
LinkedHashSet: 不可重复,但能够保持插入顺序,非线程安全。 - List类
ArrayList:插入顺序和遍历顺序相同,因为是基于数组实现的,所以查找效率较高,适合插入删除操作较少,查询较多的数据结构。非线程安全;
LinkedList: 基于链表结构实现,适合插入删除操作,但是不利于查找。非线程安全; - Map类
HashMap: 这几乎是最常用的Map类了,键值型的数据结构为程序员提供了不同于list和set的选择。同时,HashMap基于散列表存储,性能表现很好。对于key来说,不能重复。如果发生hash冲突则会影响性能。因为根据hashcode决定存储地址,所以是无序的。非线程安全。
LinkedHashMap: 初始化的时候有两个选择需要注意
LinkedHashMap<String,String> linkedHashMap=new LinkedHashMap<String,String>();
LinkedHashMap<String,String> lruMap=new LinkedHashMap<>(12, 0.75f, true)第一种map,插入顺序和和遍历顺序保持一致,发生key值重复的话在相同位置覆盖原来的元素,但不影响遍历的顺序。
第二种,构造函数参数为true的话,实现LRU算法,即最近最少使用,每次访问map中的元素时,该键值对将被移动到表头,如以下代码:
//实现lru算法
LinkedHashMap<String,String> lruMap=new LinkedHashMap<>(12, 0.75f, true);
for(int i=1;i<=10;i++){
lruMap.put("key"+i, "fucked"+i);
}
lruMap.get("key"+3);
for(Map.Entry<String, String> entry:lruMap.entrySet()){
System.out.println(entry.getKey());
}程序输出:
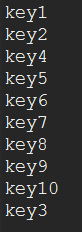
可以看到,key3在访问之后,键值对移动了位置;有的时候需要设计一定长度的LRU队列,老化节点出队, 统计在一定时间内某些数据的活跃程度,可以继承LinkedHashMap,并重写相关方法,设计自己的LRU队列;
TreeMap:底层实现基于红黑树结构,非常复杂,但用起来比较简单,值不能重复。默认按照key值进行升序排序 。若想实现自定义排序,在初始化的时候构造函数中实现comparator比较器,同样也是基于key值进行排序,若想基于value值进行排序,比较麻烦,可以转换成其他数据结构,比如list。用Collection.sort()方式实现自定义按照value值排序。关于TreeMap和红黑树的详细介绍参看chenssy大神的java提高篇之TreeMap:http://blog.csdn.net/chenssy/article/details/26668941
WeakHashMap:当除了自身的key的引用外,若此key没有其他的引用,那么Map将自动丢弃该键值对:
WeakHashMap<String,String> whm=new WeakHashMap<String,String>();
String a=new String("shit");
String b=new String("fuck");
whm.put(a, "this is a");
whm.put(b, "this is b");
a=null;
System.gc();
Iterator<Map.Entry<String, String>> it=whm.entrySet().iterator();
while(it.hasNext()){
Map.Entry<String, String> entry=it.next();
System.out.println(entry.getKey());
}程序只输出一个fuck,注意,只有在遍历或者访问的时候才会执行回收!如果你什么都不干,是不会释放内存的!很哲学的问题,在打开盒子之前,你永远不知道盒子里有什么以及有多少东西。
IdentityHashMap: 在比较key值是否相等时,比较的是引用,即使用==,而HashMap比较key则是用equal,看代码:
String a=new String("shit");
String b="shit";
IdentityHashMap<String,String> map=new IdentityHashMap<>();
map.put(a, "this is a");
map.put(b, "this is b");
for(Map.Entry<String, String> entry:map.entrySet()){
System.out.println(entry.getKey()+"|"+entry.getValue());
}程序输出:
shit|this is b
shit|this is a
比如需要统计学生成绩,key为name,value为grade,如果使用HashMap,不太好处理同名的情况,但使用IdentityHashMap就可以简单的避免这种问题;
Hashtable: 和hashmap特性差不多,但是线程安全的,实际上并不绝对,还是需要更高层次的并发控制,不接受null值,不管是key或者value放入null值会报异常;
以上就是各种集合的简单总结,水平有限,只能在表面上学习一点用法,底层的实现和细节还需要慢慢的学习理解。















 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









