







⛳️ 实战场景
作为程序员,你是否碰到这样的场景:领导指着电脑上的某块区域数据,告诉你 10 分钟整理下来!
谁说提需求的就一定要是产品经理,老板不就是最大的产品经理么。
今天咱们就来实战一下,这个任务能否在 10 分钟内完成,目标数据呈现样式如下。
最终需要整理的 Excel 格式如下所示:
| 大类 | 专业 | |
| ------ | -------- | -------- | — |
| 语言类 | 汉语 | 商务英语 |
| 文秘类 | 文秘 | 文秘速录 | |
| 教育类 | 早期教育 | 小学教育 |
⛳️ 第 1 分钟,分析目标源
打开目标站点,进行数据分析,使用到的核心工具是 浏览器开发者工具。
直接检查页面源码,在其中搜索关键字,例如 运动训练,发现源码中无数据,此时表示数据来源为异步,使用检索关键字进行快速定位。
切换到开发者工具的网络视图,按下键盘的 Ctrl+F,参考下图进行设置。

这里已经获取到了数据所在地址,即 http://hebei.danzhaowang.com/html/majorlib.html,忽略页面文字编码错误。

整个流程耗时 1 分钟,已经找到目标数据源。
⛳️ 第 2~5 分钟,编写爬虫程序
下面用 4 分钟实现一个爬虫程序的编写,重点使用 requests 模块的 get() 方法请求数据,由于目标页面只有一页,所以不需要使用多线程。
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.71",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Accept-Encoding": "gzip, deflate, br"
}
# 请求数据
res = requests.get('http://hebei.danzhaowang.com/html/majorlib.html', headers=headers)
# 设置网页编码
res.encoding = 'utf-8'
element = etree.HTML(res.text)
li_list = element.xpath("//li")
# 遍历数据
for item in li_list:
# 获取大类
t = item.xpath(".//h3/text()")
# 获取专业,同时去除列表中的 "更多" 选项
major_list = item.xpath(".//a/text()")[1:]
t.extend(major_list)
简单编写代码,获取到数据,上述代码学习的重点有 2 个。
- 设置网页编码,用于汉字的展示;
- 获取大类和专业,同时将大类和专业合并到一个列表中,并设置第一项为大类。
4 分钟写完的代码,运行之后得到下述所示内容。
['护理类', '护理', '助产']
['药学类', '药学', '中药学', '蒙药学', '维药学', '藏药学']
['临床医学类', '临床医学', '口腔医学', '中医学', '中医骨伤', '针灸推拿', '蒙医学', '藏医学', '维医学', '傣医学', '哈医学', '朝医学']
['医学技术类', '医学检验技术', '医学生物技术', '医学影像技术', '医学美容技术', '口腔医学技术', '卫生检验与检疫技术', '眼视光技术', '放射治疗技术', '呼吸治疗技术']
['康复治疗类', '康复治疗技术', '言语听觉康复技术', '中医康复技术']
['公共卫生与卫生管理类', '预防医学', '公共卫生管理', '卫生监督', '卫生信息管理']
['财务会计类', '财务管理', '会计', '审计', '会计信息管理']
上述数据仅做了打印输出,下面在用 1 分钟的时间做一下数据存储。
⛳️ 第 6 分钟,存储数据
代码存储到 Excel 中,优先将数据写到 csv 文件中。
my_str = ",".join(t)
with open('./data.csv', 'a', encoding='utf-8') as f:
f.write(my_str + "\n")
运行代码,会在代码目录生成一个 csv 文件,打开如下所示。
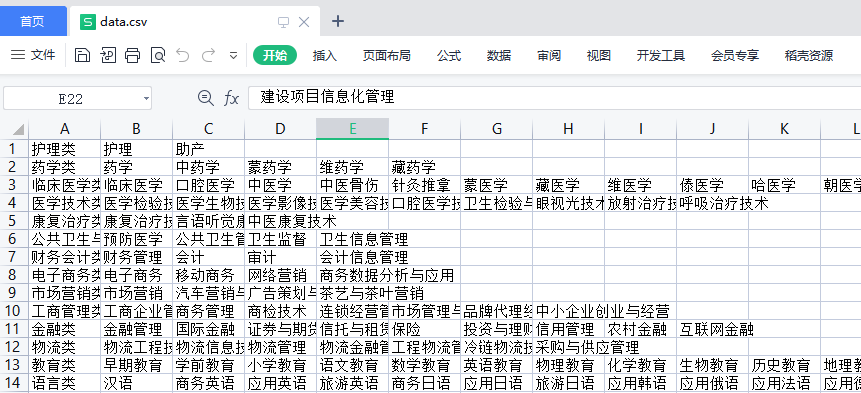
目前累计耗时 6 分钟,剩下的 4 分钟可以优化一下 PPT,或者直接甩给领导去摸鱼。
为了加薪升职,为了卷别人,我们优化一下格式。
⛳️ 第 7-8 分钟,存储数据
美化步骤:
- 统一字体,统一文字大小;
- 设置列名称;
- 单元格水平居中,垂直居中;
- 设置单元格边框。
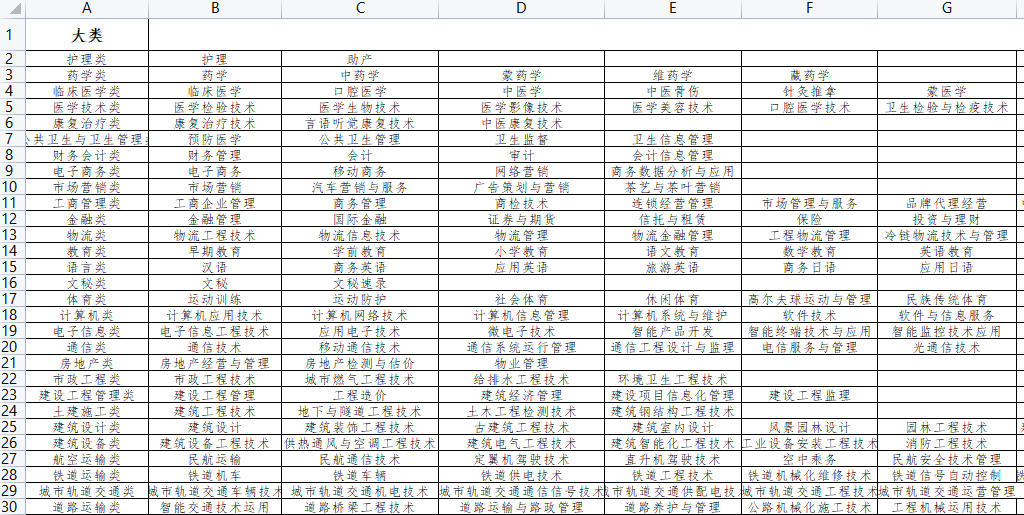
完成任务,交给领导,摸鱼 2 分钟到无穷大时间。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 735 篇原创博客
从订购之日起,案例 5 年内保证更新
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











