







文章目录
一. 情况说明
CREATE TABLE `kafka01` (
`name` STRING,
`id` INTEGER,
`name1` STRING,
`num_dou` DOUBLE,
`num_float` DOUBLE,
`num_int` INTEGER,
`stringmessages` STRING,
`cloud_wise_proc_time` AS `proctime`()
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'kafka_Flink_xiaoneng_1kb_006',
'properties.bootstrap.servers' = 'xxx',
'properties.max.poll.records' = '5000',
'properties.group.id' = 'shuhf',
'format' = 'json',
'json.ignore-parse-errors' = 'true',
'scan.startup.mode' = 'earliest-offset'
);
CREATE TABLE `kafka02` (
`name` STRING,
`id` INTEGER,
`name1` STRING,
`num_dou` DOUBLE,
`num_float` DOUBLE,
`num_int` INTEGER,
`stringmessages` STRING,
`cloud_wise_proc_time` AS `proctime`()
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'kafka_Flink_xiaoneng_1kb_005',
'properties.bootstrap.servers' = 'xxx',
'properties.max.poll.records' = '5000',
'properties.group.id' = 'sdkdsd',
'format' = 'json',
'json.ignore-parse-errors' = 'true',
'scan.startup.mode' = 'earliest-offset'
);
CREATE TABLE `kafka03` (
`name` STRING,
`id` INTEGER
) WITH (
'connector' = 'kafka-0.11',
'topic' = 'kafka_Flink_1302',
'properties.bootstrap.servers' = 'xxx',
'properties.acks' = '1',
'properties.retries' = '3',
'properties.batch.size' = '16384',
'properties.linger.ms' = '30',
'properties.buffer.memory' = '33554432',
'json.ignore-parse-errors' = 'true',
'format' = 'json'
);
INSERT INTO `kafka03`
(SELECT `b`.`name` AS `name`, `a`.`id` AS `id`
FROM `kafka01` AS `a`
INNER JOIN `kafka02` AS `b` ON `a`.`id` = `b`.`id`
WHERE `a`.`name1` IS NOT NULL);
下图展示了一个双流join的job(Kafka join Kafka输出到Kafka),任务总是跑到18分钟的时候挂掉,本文从checkpoint大小、job state大小、taskmanager内存等方面考虑,分析一下任务挂掉的原因,并尝试性能调试。
两个kafka都各有15个分区,分别存储了3000万的数据。
flink任务运行在yarn上,机器:CPU:8核;物理内存:32G。

二. 日志查看分析
1. checkpoint 完成不了
2022-07-28 14:45:25,972 INFO org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable [] - Window(TumblingProcessingTimeWindows(300000), ProcessingTimeTrigger, CoGroupWindowFunction) -> SourceConversion(table=[default_catalog.default_database.a72f3fe72d3e8445db5e9fba364c92811], fields=[name1, num_dou, a2c7ab0b1e6b940278812f755a8e426bd, num_float, num_int, stringmessages, id, cloud_wise_proc_time, stream_tmp_time_field]) -> Calc(select=[name1,num_dou, num_float, num_int, stringmessages, id, cloud_wise_proc_time, stream_tmp_time_field]) -> SinkConversionToTuple2 -> Map -> SourceConversion(table=[Unregistered_DataStream_19], fields=[name1, num_dou, num_float, num_int, stringmessages, id, cloud_wise_proc_time, stream_tmp_time_field, abccebc9ac5100246c993bd2d036fddcc8e]) -> Calc(select=[name1, id]) -> Sink: Sink(table=[default_catalog.default_database.kafka03], fields=[name1, id]) (1/3)#0 - asynchronous part of checkpoint 4 could not be completed.
java.util.concurrent.ExecutionException: java.io.IOException: Could not flush to file and close the file system output stream to hdfs://sts-hadoop-0.svc-hadoop-headless:18136/flink-checkpoints/87a083bde412a2d89919023fc1f262b0/chk-4/ce12428f-448b-4b03-b7d9-37b8ec2f28b3 in order to obtain the stream state handle
at java.util.concurrent.FutureTask.report(FutureTask.java:122) ~[?:1.8.0_152]
at java.util.concurrent.FutureTask.get(FutureTask.java:192) ~[?:1.8.0_152]
at org.apache.flink.runtime.concurrent.FutureUtils.runIfNotDoneAndGet(FutureUtils.java:636) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at org.apache.flink.streaming.api.operators.OperatorSnapshotFinalizer.<init>(OperatorSnapshotFinalizer.java:54) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.run(AsyncCheckpointRunnable.java:127) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_152]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_152]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_152]
Caused by: java.io.IOException: Could not flush to file and close the file system output stream to hdfs://sts-hadoop-0.svc-hadoop-headless:18136/flink-checkpoints/87a083bde412a2d89919023fc1f262b0/chk-4/ce12428f-448b-4b03-b7d9-37b8ec2f28b3 in order to obtain the stream state handle
at org.apache.flink.runtime.state.filesystem.FsCheckpointStreamFactory$FsCheckpointStateOutputStream.closeAndGetHandle(FsCheckpointStreamFactory.java:373) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at org.apache.flink.runtime.state.CheckpointStreamWithResultProvider$PrimaryStreamOnly.closeAndFinalizeCheckpointStreamResult(CheckpointStreamWithResultProvider.java:75) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at org.apache.flink.runtime.state.heap.HeapSnapshotStrategy$1.callInternal(HeapSnapshotStrategy.java:216) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at org.apache.flink.runtime.state.heap.HeapSnapshotStrategy$1.callInternal(HeapSnapshotStrategy.java:167) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at org.apache.flink.runtime.state.AsyncSnapshotCallable.call(AsyncSnapshotCallable.java:78) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_152]
at org.apache.flink.runtime.concurrent.FutureUtils.runIfNotDoneAndGet(FutureUtils.java:633) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
... 5 more
2. 组件通讯时心跳超时
2022-07-26 15:09:04,454 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Window(TumblingProcessingTimeWindows(300000), ProcessingTimeTrigger, CoGroupWindowFunction) -> SourceConversion(table=[default_catalog.default_database.a85793bccf98f429a9c65b9d7f543a63f], fields=[name1, num_dou, ab19bf812d43241d69d6d279423058f2d, num_float, num_int, stringmessages, id, cloud_wise_proc_time, stream_tmp_time_field]) -> Calc(select=[name1, num_dou, num_float, num_int, stringmessages, id, cloud_wise_proc_time, stream_tmp_time_field]) -> SinkConversionToTuple2 -> Map -> SourceConversion(table=[Unregistered_DataStream_19], fields=[name1, num_dou, num_float, num_int, stringmessages, id, cloud_wise_proc_time, stream_tmp_time_field, abcb732da05297d4a1687ec9cb8dd8e2653]) -> Calc(select=[name1, id]) -> Sink: Sink(table=[default_catalog.default_database.kafka03], fields=[name1, id]) (6/15) (6764cdaa394dd742e35a0d770dc92a5a) switched from DEPLOYING to RUNNING.
2022-07-26 15:09:04,454 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Window(TumblingProcessingTimeWindows(300000), ProcessingTimeTrigger, CoGroupWindowFunction) -> SourceConversion(table=[default_catalog.default_database.a85793bccf98f429a9c65b9d7f543a63f], fields=[name1, num_dou, ab19bf812d43241d69d6d279423058f2d, num_float, num_int, stringmessages, id, cloud_wise_proc_time, stream_tmp_time_field]) -> Calc(select=[name1, num_dou, num_float, num_int, stringmessages, id, cloud_wise_proc_time, stream_tmp_time_field]) -> SinkConversionToTuple2 -> Map -> SourceConversion(table=[Unregistered_DataStream_19], fields=[name1, num_dou, num_float, num_int, stringmessages, id, cloud_wise_proc_time, stream_tmp_time_field, abcb732da05297d4a1687ec9cb8dd8e2653]) -> Calc(select=[name1, id]) -> Sink: Sink(table=[default_catalog.default_database.kafka03], fields=[name1, id]) (14/15) (10c590f6ba227d69ec02072c5a227d45) switched from DEPLOYING to RUNNING.
2022-07-26 15:09:04,455 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: TableSourceScan(table=[[default_catalog, default_database, datalake_502c786a6f4efaa4625a10e7296308b4419]], fields=[mame1, id, num_dou, num_float, num_int, stringmessages]) -> Calc(select=[num_float, num_int, stringmessages, id, PROCTIME_MATERIALIZE(()) AS cloud_wise_proc_time]) -> SinkConversionToTuple2 -> Map -> Map -> Map (12/15) (ffed3ff4a4554a210948ba7c95804cf0) switched from DEPLOYING to RUNNING.
2022-07-26 15:11:01,552 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Triggering checkpoint 1 (type=CHECKPOINT) @ 1658819461343 for job 1207d0f501e4667a74b7c1ec6adeb35b.
2022-07-26 15:13:31,944 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Completed checkpoint 1 for job 1207d0f501e4667a74b7c1ec6adeb35b (35255436 bytes in 150514 ms).
2022-07-26 15:16:01,753 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Triggering checkpoint 2 (type=CHECKPOINT) @ 1658819761342 for job 1207d0f501e4667a74b7c1ec6adeb35b.
2022-07-26 15:18:42,547 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Completed checkpoint 2 for job 1207d0f501e4667a74b7c1ec6adeb35b (18547907 bytes in 161205 ms).
2022-07-26 15:21:01,448 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Triggering checkpoint 3 (type=CHECKPOINT) @ 1658820061342 for job 1207d0f501e4667a74b7c1ec6adeb35b.
2022-07-26 15:25:26,159 INFO org.apache.flink.runtime.resourcemanager.active.ActiveResourceManager [] - The heartbeat of TaskManager with id container_1658818822445_0002_01_000002(sts-hadoop-0.svc-hadoop-headless.dodp.svc.cluster.local:18131) timed out.
2022-07-26 15:25:26,159 INFO org.apache.flink.runtime.resourcemanager.active.ActiveResourceManager [] - Closing TaskExecutor connection container_1658818822445_0002_01_000002(sts-hadoop-0.svc-hadoop-headless.dodp.svc.cluster.local:18131) because: The heartbeat of TaskManager with id container_1658818822445_0002_01_000002(sts-hadoop-0.svc-hadoop-headless.dodp.svc.cluster.local:18131) timed out.
2022-07-26 15:25:26,164 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: TableSourceScan(table=[[default_catalog, default_database, datalake_502dc50fd805b9b458eba6cce97f7a63de3]], fields=[name, id, name1, num_dou, num_float, num_int, stringmessages]) -> Calc(select=[name1, num_dou, id AS ab19bf812d43241d69d6d279423058f2d, PROCTIME_MATERIALIZE(()) AS cloud_wise_proc_time]) -> SinkConversionToTuple2 -> Map -> Map -> Map (6/15) (b128a07b944613c2ea332e07e402a169) switched from RUNNING to FAILED on container_1658818822445_0002_01_000002 @ sts-hadoop-0.svc-hadoop-headless.dodp.svc.cluster.local (dataPort=37115).
java.util.concurrent.TimeoutException: The heartbeat of TaskManager with id container_1658818822445_0002_01_000002(sts-hadoop-0.svc-hadoop-headless.dodp.svc.cluster.local:18131) timed out.
at org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener.notifyHeartbeatTimeout(ResourceManager.java:1454) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at org.apache.flink.runtime.heartbeat.HeartbeatMonitorImpl.run(HeartbeatMonitorImpl.java:111) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_152]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_152]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:440) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:208) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:77) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:158) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.actor.Actor$class.aroundReceive(Actor.scala:517) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.actor.ActorCell.invoke(ActorCell.scala:561) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.dispatch.Mailbox.run(Mailbox.scala:225) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.dispatch.Mailbox.exec(Mailbox.scala:235) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) ~[flink-dist_2.11-1.12.5.jar:1.12.5]
2022-07-26 15:25:26,243 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Discarding the results produced by task execution b128a07b944613c2ea332e07e402a169.
2022-07-26 15:25:26,245 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Discarding the results produced by task execution b128a07b944613c2ea332e07e402a169.
3. taskManager报内存溢出
三、故障与性能调优分析
1. checkpoint
日志中有checkpoint失败的信息,一般来说是job的state太大,cp做的时间太短,间隔过小导致的。所以需要扩大job的设置,主要关注参数有两个:生成间隔与超时时间。都设置为10分钟触发一次。
//1、检查点
if (StringUtils.isBlank(properties.getCheckpointPower())
|| !ConstantType.CHECKPOINT_POWER_OFF.equalsIgnoreCase(properties.getCheckpointPower())) {
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//1.1、启动checkpoint并生成间隔
if (properties.getCheckpointInterval() > 0) {
env.enableCheckpointing(properties.getCheckpointInterval() * 1000);
}
//检查点失败容忍次数
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);
//当取消拥有的作业时,所有检查点状态都会保留。 取消作业后,必须手动删除检查点元数据和实际程序状态
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//1.2、超时时间
if (DragStringUtils.isNotNullNumber(properties.getCheckpointTimeout())) {
checkpointConfig.setCheckpointTimeout(properties.getCheckpointTimeout() * 1000);
}
//1.3、检查点生成的模式
if (StringUtils.isNotBlank(properties.getCheckpointMode())) {
if (CheckpointingMode.AT_LEAST_ONCE.name().equals(properties.getCheckpointMode())) {
checkpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);
}
if (CheckpointingMode.EXACTLY_ONCE.name().equals(properties.getCheckpointMode())) {
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
}
}
}
设置之后看到仍然有两个checkpoint失败,但整体不影响job运行。
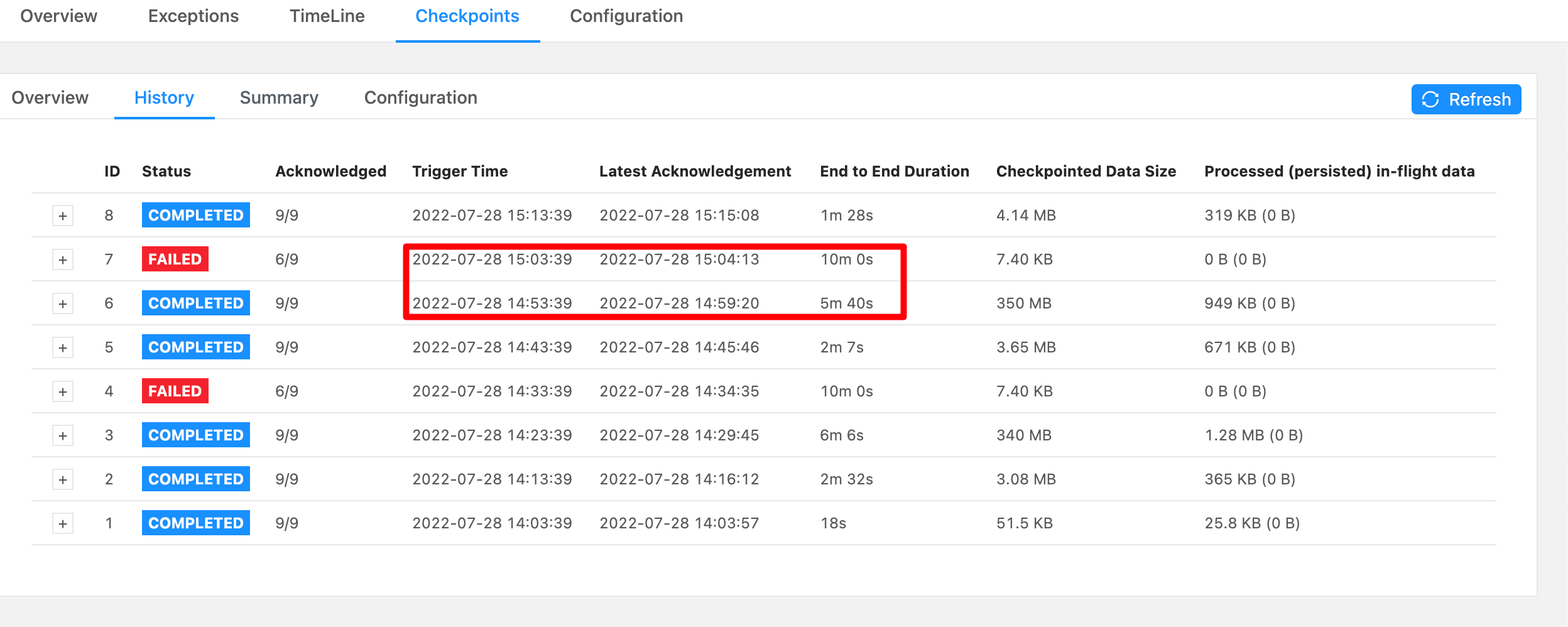
2. 组件通讯时心跳超时
扩大心跳超时时间:
heartbeat.timeout=1800000;
/**
* 将类似如下配置切割为k=v存入新的ConfigOption对象中,传入flink-conf.yml
* 比如:taskmanager.memory.jvm-overhead.fraction=0.1
* //org.apache.flink.configuration.Configuration flinkConfiguration flinkConfiguration = new Configuration();
*/
private void addExtraFlinkJobParams(org.apache.flink.configuration.Configuration flinkConfiguration, String flinkConfExtraParam) {
if (StringUtils.isEmpty(flinkConfExtraParam)) {
return;
}
Arrays.stream(flinkConfExtraParam.split(";"))
.forEach(kvs->{
String[] split = kvs.split("=");
if (split.length!=2) {
return;
}
flinkConfiguration.set(ConfigOptions.key(split[0].trim()).stringType().noDefaultValue() ,split[1].trim());
});
}
3. 数据倾斜
可以看到右表的加载的数据要比左表的数据大的多,此时将右表kafka拉取数据的频率减小
//flink sql的参数
properties.max.poll.records
4. 扩大运行内存
既然出现了内存溢出的情况那就先扩大运行的内存,一般地,flink Jobmanager的内存一般用于启动flink、做checkpoint、各个组件相互通讯、以及JVM class元数据加载与JVM的一些开销,它的内存一般比较固定,不会在job运行时受到较大的影响,所以jobManager的内存一般可以不设置。
扩大TaskManager的内存
flink-conf.yaml 下有这样一段描述关于flink内存:
# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.
# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.
大概的意思是:不推荐使用taskmanager的进程内存,而是使用total Flink memory 即taskmanager.memory.flink.size。有下面的公式:
taskmanager.memory.framework.off-heap.size +
taskmanager.memory.framework.heap.size +
taskmanager.memory.network.max +
taskmanager.memory.managed.size +
taskmanager.memory.task.heap.size = taskmanager.memory.flink.size
具体每个内存分析见:Flink内存模型:从宏观(Flink内存模型)、微观(Flink内存结构)、数据传输等角度分析Flink的内存管理。
一般地,framework.heap/off-heap、JVM Metaspace、JVM Overhead 这几个参数一般情况下是不需要配置,走默认值就可以。
我们主要关注的是 Task Heap、Managed Memory、Network 这几部分的内存,Flink 本身也会计算出这 3 部分的内存,我们自己也需要根据任务的特点,比如流量大小,状态大小等去调整。
我们再回到双流job本身,有几个特点:1. kafka分区数为15; 2. 双流在运行过程中状态比较大。
所以基本思路是在调大taskmanager的内存同时,提高Managed Memory的fraction,同时将slot数量和并行度都调整为和kafka分区数一致。
四. 小结
对于双流job有以下特点:
我们再回到双流job本身,有几个特点:1. kafka分区数为15; 2. 双流在运行过程中状态比较大。
针对上述特点以及在运行过程中遇到的问题我们对job做了以下调整:
调整:
//通讯时心跳延迟
heartbeat.timeout=180000;
//观察checkpoint的生成规律,调整checkpoint的生成周期和超时时间
见上
//数据倾斜:调小右表拉取速率
//flink connector kafka sql的参数
properties.max.poll.records = 500;
//并行度和slot根据kafka的分区数调整
taskmanager.numberOfTaskSlots=15;
parallelism.default=15;
//taskmanager内存调大、managed比例调大:默认为0.4
taskmanager.memory.flink.size = 4G
taskmanager.memory.managed.fraction=0.6;
//打印GC信息到flink 控制台,以便任务分析
env.java.opts=-XX:+PrintGCDetails -XX:+PrintGCDateStamps;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











