







开始跟随课本张利兵的《Flink设计与实现:核心原理与源码解析》阅读flink的源码,
- 希望对flink的流实现、窗口、容错、sql、jm与tm的通讯等逻辑与原理有一个更加细致的理解,
- 能够吸收flink的代码思想,并运用到实际项目中(已借鉴connector 类型转换的策略模式)
- 还有更重要的,能够在遇到问题时,知道出问题的地方源码大致逻辑是什么,能比较效率的定位并解决问题。
文章目录
简介
DataStream API主要用于构建流式类型的Flink应用,处理实时无界数据流。
DataStream API属于定义式编程接口,可以编写复杂的例如对状态数据的操作、窗口的定义等功能。
1. datastream的程序结构
对于flink的datastream的执行程序来说,程序固定的包含这几个动作:
- StreamExecutionEnvironment初始化
- 业务逻辑转换代码
- 执行应用程序
看一个代码的例子:
具体的:
1.1. StreamExecutionEnvironment初始化
主要通过DataStream API构建Flink作业需要的执行环境,包括设定ExecutionConfig、
CheckpointConfig等配置信息以及StateBackend和TimeCharacteristic等变量。
1.2. 业务逻辑转换代码
streamExecutionEnvironment提供了创建DataStream的方法,例如socketTextStream(ip,port) 可以构建socket流。
之后转换操作会以DataStreamSource为头部节点,DataStream API中提供了各种转换操作,例如map、reduce、join等算子,用户可以用来构建完整的Flink计算逻辑。
1.3. 执行应用程序
编写完Flink应用后,必须调用ExecutionEnvironment.execute()方法执行整个应用程序。
execute()方法中会基于DataStream之间的转换操作生成StreamGraph,并将StreamGraph结构转换为JobGraph,最终将JobGraph提交到指定集群中运行。
2. DataStream的主要成员
DataStream通过转换操作可以生成新的DataStream。DataStream主要用于表达业务转换逻辑,实际上并没有存储真实数据。
2.1. Pipeline拓扑的构建
StreamExecutionEnvironment会将DataStream之间的转换操作存储至其
List<Transformation<?>> transformations集合中,然后基于这些转换操作构建作业Pipeline拓扑,用于描述整个作业的计算逻辑。
其中流式作业对应的Pipeline实现类为StreamGraph,批作业对应的Pipeline实现类为Plan。
2.2. 算子的源码结构
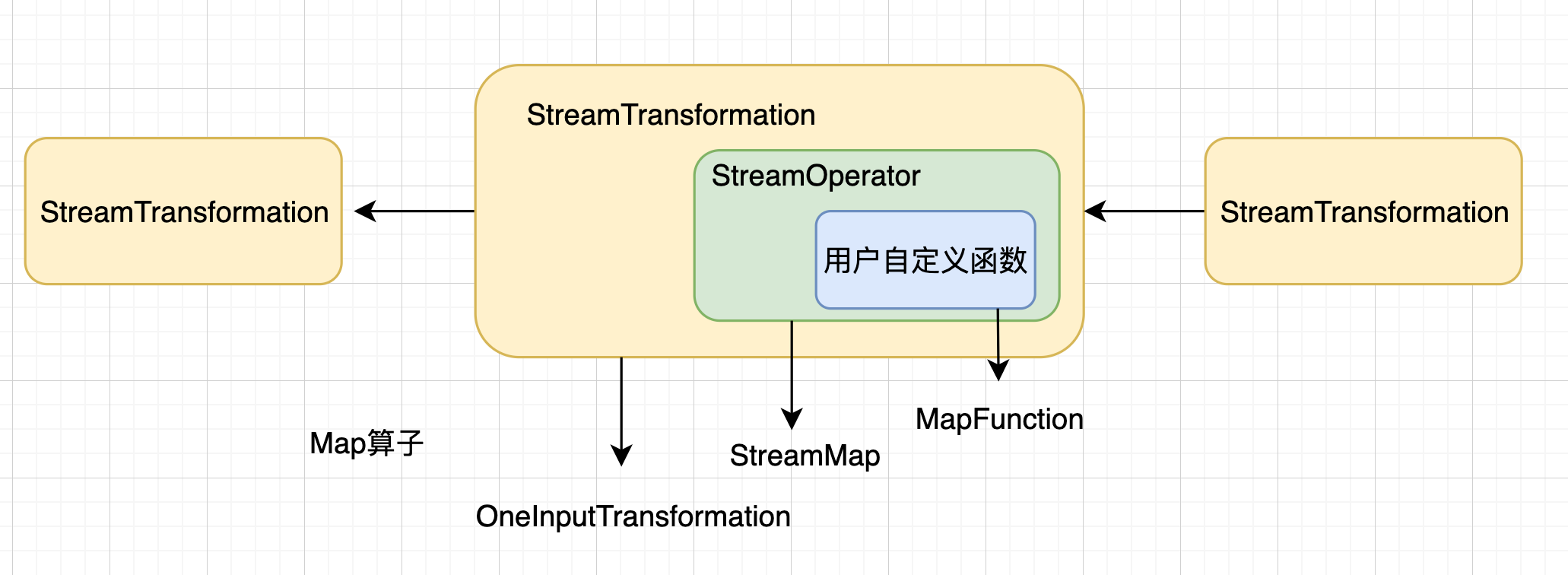
StreamTransformation结构
DataStream之间的转换操作都是通过StreamTransformation结构展示的。
如上图:当执行DataStream.map()方法转换时,底层对应的便是OneInputTransformation转换操作。
StreamOperator
每个StreamTransformation都包含相应的StreamOperator。
如上图,执行DataStream.map-(new MapFunction(…))后,会生成StreamMap算子。
用户自定义函数
StreamOperator包含了用户自定义函数的信息,如上图,StreamMap算子包含了MapFunction。
MapFunction就是用户自定义的map转换函数。还有其他类型的函数,例如ProcessFunction、SourceFunction和SinkFunction等。
3. DataStream底层源码之map源码
通过DataStream中的map转换操作为例,对DataStream底层源码实现进行说明。
map的使用逻辑:
.map(new MapFunction<String, Tuple2<String, Integer>>() {
public Tuple2<String, Integer> map(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
}).
用户首先定义MapFunction的具体逻辑,然后调用DataStream.map() 将实例封装在map的转换中。
接着看下map的源码
/**
调用MapFunction来处理datastream的每一条数据。
*/
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper, TypeInformation<R> outputType) {
return transform("Map", outputType, new StreamMap<>(clean(mapper)));
}
map调用了transform()进行后续处理:会基于MapFunction实例创建StreamMap实例,即StreamOperator的实现子类。
transform()的具体逻辑在doTransform()中:
protected <R> SingleOutputStreamOperator<R> doTransform(
String operatorName,
TypeInformation<R> outTypeInfo,
StreamOperatorFactory<R> operatorFactory) {
//获取上一算子输出的typeinformation信息
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
//创建本算子的(OneInput)Transformation
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism());
//主要用于每次转换操作后返回给用户继续操作的数据结构
@SuppressWarnings({"unchecked", "rawtypes"})
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
//将创建好的OneInputTransformation添加到StreamExecutionEnvironment的Transformation集合中,用于生成StreamGraph对象。
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
逻辑如下:
1.获取TypeInformation
从上一次转换操作中获取TypeInformation信息,确定没有出现MissingTypeInfo错误,以确保下游算子转换不会出现问题。
2.创建OneInputTransformation
OneInputTransformation也会包含当前DataStream对应的上一次转换操作。
3.创建SingleOutputStreamOperator
SingleOutputStreamOperator继承了DataStream类,属于特殊的DataStream,主要用于每次转换操作后返回给用户继续操作的数据结构。
4.将OneInputTransformation添加到trans集合
调用addOperator(resultTransform),将创建好的OneInputTransformation添加到StreamExecutionEnvironment的Transformation集合中,用于生成StreamGraph对象。
5.按顺序存储
将returnStream返回给用户,继续执行后续的转换操作。
基于这样连续的转换操作后,会将所有DataStream的转换按顺序存储在StreamExecutionEnvironment中。
小结:
在DataStream转换的过程中,不管是哪种类型的转换操作,都是按照同样的方式进行的:
首先将用户自定义的函数封装到Operator中,然后将Operator封装到Transformation转换操作结构中,最后将Transformation写入StreamExecutionEnvironment提供的Transformation集合。
通过DataStream之间的转换操作形成Pipeline拓扑,即StreamGraph数据结构,最终通过StreamGraph生成JobGraph并提交到集群上运行。
参考:
张利兵的《Flink设计与实现:核心原理与源码解析》

















 1226
1226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











