







由于单台机器的计算能力和I/O能力已经无法满足不断增长的数据处理需求,越来越多的组织需要将应用扩展到更大规模的集群上。但在集群环境中,可编程性方面将遇到以下几个挑战:
- 并行编程问题;为了将应用并行化,需要并行编程模型的支撑。
- 容错和慢节点问题;当集群规模相当大时,这个问题也是非常严重的。
- 多用户共享集群要求能具备弹性计算的能力,此外还要考虑干扰问题。
结果就是出现了很多编程模型,首先是MapReduce使数据批处理变得简单通用同时能处理容错。但很难处理其它类型的负载,于是就出现了各种各样专用的编程模型:
- Pregel,用来解决迭代图算法问题
- F1,处理SQL查询
- MillWheel,持续流处理
- Storm,Impala,Piccolo,GraphLib...
我们认为能够设计一种通用的编程抽象,不仅仅能够处理现在各种各样的工作类型负载,还能处理未来新的应用类型。我们提出了RDD(Resilient Distributed Dataset,弹性分布式数据集),一种高效的数据共享原语,从而大幅度提升了其通用性。围绕RDD建立起来的框架相比于现有框架有以下几种优势:
- 一个运行时系统同时支持批处理,迭代,流处理计算,交互式查询。这让由这几种计算模型组合而成的大量的新兴应用成为可能。同时在性能上比单独的分布式系统有更大的提升。
- 提供高强度的容错和慢节点容忍方案。
- 相比于MapReduce,性能有100倍以上的提升。
- 支持多租户,支持资源弹性调度。
围绕RDD建立的Spark系统如图1所示。
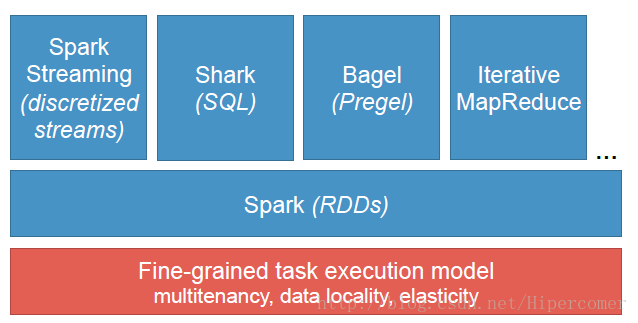
图 1 Spark系统
专用系统的问题
- 重复工作,每个系统都需要考虑容错和负载分布等问题。
- 组合,不同专用系统的计算组合起来非常苦难
- 范围有限,如果应用和系统不符,要么修改应用,要么发明新系统
- 资源共享,不同计算系统之间共享数据非常困难,因为每个系统都假设自己拥有整个集群的资源
- 管理维护,每个系统都需要重新学习其API,运行原理,部署方法等等...
基于这些问题,我们需要一个对集群计算的统一抽象来提升集群的可用性,性能,对多用户的处理以及对复杂应用的支持。
弹性分布式数据集(RDD)
仔细研究MapReduce不能支持其它不同类型的应用,就会发现问题都归结为一个,那就是在计算阶段缺少高效的数据共享机制。RDD正是为了解决这个问题而诞生的。以MapReduce和Dryad为例,他们对都通过计算任务的有向无环图(DAG)对计算进行结构化。除了将文件系统的数据做多份副本以外,这些模型并没有提供存储抽象。当发生故障时,需要通过网络拷贝大量的数据。RDD是一个不使用数据复制的容错分布式内存抽象,通过对RDD创建图的记忆,在遇到故障时,可以像批处理一样重新恢复出丢失的数据。只要这些创建RDD的操作时粗粒度的,这种方法就比单纯的数据复制高效很多。
为什么RDD的通用性这么强?从表达能力的角度看,RDD可以模仿任意的分布式系统。2.从系统的角度看,RDD给应用足够的控制来优化集群中可能造成计算瓶颈的资源。通过优化这些资源,基于RDD的应用性能上几乎可以和专用系统媲美。
基于RDD的模型
- 迭代算法,RDD可以解决迭代算法问题
- 关系数据库查询,对应的是Shark SQL
- MapReduce,RDD可以支持MapReduce类型和Dryad类型的应用
- 流处理,基于RDD实现的流处理,称之为D-Stream
- 组合模型,基于RDD可以将以上几种模型组合起来以构造更加复杂的应用。
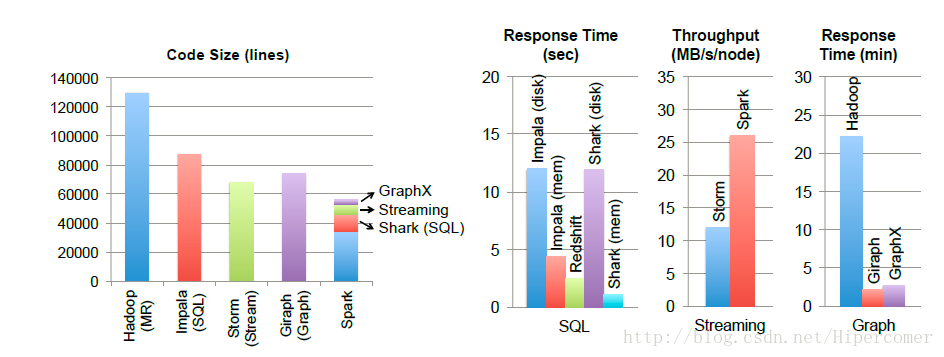
图2 和专用系统的比较
图2为基于Spark实现的各种编程模型和专用系统的比较。左侧为代码量的比较,右侧为效率比较。可以看到,无论是表达能力还是运行效率RDD都达到了预期的目标。















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









