







Scalca笔记总结
1、变量定义:有两种val 和var
val 类似于Java中的final 变量,初始化之后不能再赋值;
var类似java中的变量,可以在生命周期中多次赋值;
与Java不同 的时类型声明在变量后面,用:分割,如果没有指定变量类型,编译器将会自动推断。
val a:string = 'hello scala'
注意:当val被声明为lazy时,初始化将被推迟,直到首次获取它的值
2.数据类型
摘抄自网络:

3. 复合类型:
数组array 、列表list、元组tuple、集合set、映射map
数组声明方法:
val 数组名 = new Array[类型名] (数组大小)
多维数组:
声明方式:Array.ofDim[类型] (维度1,维度2。。。。)
val mulDimArr = Array.ofDim[Double] (2,3)
也可以通过Array[Array[Int] (维度)], 获得不规则数组
val difLenMulArray = new Array[Array[Inte] (3)]
for(i<- 1 to difLenMulArray.length ){
difLenMulArray (i-1)=new Array[Int](i)
}
4. 列表List:
val one = List(1,2)
val two = List(3,4)
val oneTwo = one ::: two
List 通过::: 实现叠加功能
val two = List(3,4)
val three = 1::: two
List 通过:: 把一个新元素组合到已有List的最前端,然后返回List结果
5. 元组tuple:
元组可以包含不同类型的元素;
可以用_n形式访问元组元素
val test = (99, "hello scala")
println(test._1)
println(test._2)
6. 集合set:

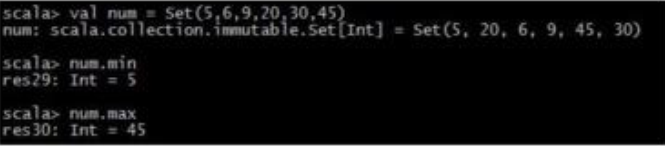
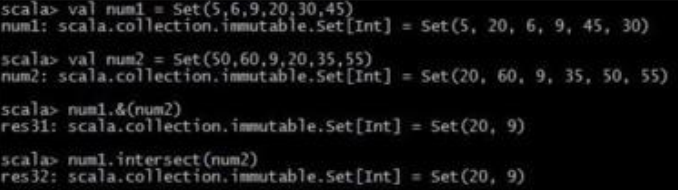
7. 映射map:



8、scala函数:
函数定义格式:
def 函数名(参数列表):返回值类型={函数体}
def max(x:Int, y: Int): Int={
if(x>y) x
else y
}
max(4,9)
返回值可以用return指定,使用return时函数必须定义返回值类型;
对于递归函数,必须指定返回值类型;
可以在函数内部再定义函数,如同定义一个局部变量;
匿名函数:
var add = (x:Int)=>x+1
add(8)
scala 允许使用函数作为参数,比如foreach方法
val num = List(1,2,4,8,5,-9,-5)
num.foreach((x:Int)=>println(x))
也可以使用一个filter方法过滤集合中的元素
val num = List(1,2,4,8,5,-9,-5)
num.filter(x=>x>0)
scala函数的简化表达:
可以使用 _ 代替单个参数如_=>_>0
val num = List(1,2,4,8,5,-9,-5)
num.filter(x=>x>0)
num.filter(_=>_>0)
类和对象
scala类定义和java相似,也是通过class关键字声明的
不同的是scala缺省修饰符为public
单例对象:scala 不提供静态变量或者静态方法
提供Singleton(单例对象);
9. 实现Word count

scala> import scala.io.Source
scala> val lines = Source.fromFile("/usr/local/src/data/The_man_of_property.txt").getLines
lines: Iterator[String] = non-empty iterator

Iterator it 这是一个迭代器
it.next(): 获取迭代器中下一个元素
it.hasNext():判断集合中是否还有元素
最简单采用while循环进行遍历scala> val lines = Source.fromFile("/usr/local/src/data/The_man_of_property.txt").getLines.toList
toList: 将上面迭代器中放入列表中进行返回
scala> lines.length 和 wc -l The_Man_of_Property.txt 返回的数据结果一致
res0: Int = 2866
需要对每一行的数据进行单词的切割(提取单词)

理解Range:
定义:可以理解为一个序列
Range 就是区间类型
scala> val a = Range(0,5) [0,5) 步长是1
a: scala.collection.immutable.Range = Range(0, 1, 2, 3, 4)
等价于
val b = 0 until 5
包含起始
scala> val c = 1 to 5 <==> val d = 1.to(5)
Range转换为List:
a.toList
val list1 = (1 to 10).toList
理解map:
scala> a.map(x=>x*2) <==> a.map(_*2) 对每个元素进行遍历操作 *2
理解Vector: 可以认为是保存数据的容器,也称为集合
1、创建Vector 对象
scala> val v1 =Vector(1,2,3)
获取 Vector元素 索引下标从0 开始
scala> println(v1(0))
2、Vector 遍历
scala> for(i<- v1) print(i+" ")
1 2 3
理解_:
作用是通配符
(1)集合中每一个元素
a.map(_*2)
(2)获取tuple中的元素
scala> val s = (“hello”,“badou”)
s: (String, String) = (hello,badou)
s._1 s.2
(3) 导入所有包
import scala.collection.immutable.xxx 指定具体包
import scala.collection.immutable.
(4)初始化变量
val a=1 定义的变量不能被修改 , var可以修改
scala> var name:String=_
name: String = null
scala> var score:Int=_
score: Int = 0
理解split:
scala> val s = “The Man of Property”
scala> s.split(" ")
res18: Array[String] = Array(The, Man, of, Property)
结合:
scala> lines.map(x=>x.split(" “))
scala> lines.map(_.split(” "))
返回的是List (Array(), Array*()…) ?
目标:将Array进行打平
理解flatten函数
scala> val s1 = List(Range(0,5), Range(0,5), Range(0,5))
scala> val s2 = s1.flatten
s2: List[Int] = List(0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0, 1, 2, 3, 4)
每个元素遍历操作
s2.map(x=>x+2)
s2.map(_+2)
直接针对s1进行处理
scala> s1.map(x=>x.map(x=>x*2))
scala> s1.map(.map(*2))
将Vector进行打散
scala> s1.flatMap(.map(*2))
等价于
scala> s1.map(.map(*2)).flatten
res30: List[Int] = List(0, 2, 4, 6, 8, 0, 2, 4, 6, 8, 0, 2, 4, 6, 8)
映射到lines
map + flatten <==> flatMap
scala> lines.map(x=>x.split(" “)).flatten
scala> lines.flatMap(_.split(” "))
MR Map:
scala> lines.flatMap(x=>x.split(" “)).map(x=>(x,1))
scala> lines.flatMap(.split(" ")).map(x=>(x,1))
scala> lines.flatMap(.split(” ")).map((_,1))
scala> lines.flatMap(.split(" ")).map((,1)).groupBy(_._1)
res36: scala.collection.immutable.Map[String,List[(String, Int)]] =
Map(forgotten -> List((forgotten,1), (forgotten,1), (forgotten,1)))
从tuple 中(forgotten,1) 获取第一个单词 forgotten 作为key
将整个tuple作为value,收集到一个List中
这样对应的value
_1: forgotten _2: List((forgotten,1), (forgotten,1), (forgotten,1))
整个list的大小,就是forgotten 出现的次数
scala> lines.flatMap(.split(" ")).map((,1)).groupBy(_.1).map(x=>(x.1, x.2.length))
等价于
scala> lines.flatMap(.split(" ")).map((,1)).groupBy(._1).map(x=>(x._1, x._2.size))
理解数组求和的方式:
scala> val a1 = List((1,2), (3,4),(5,6))
scala> a1.map(.2).sum
scala> a1.map(.2).reduce(+)
reduce(+)计算原理:
List(1,1,1) => ((1+1)+1) => sum +=x
scala> lines.flatMap(.split(" ")).map((,1))
.groupBy(_.1)
.map(x=>(x.1,x.2.map(.2).sum))

等价于
scala> lines.flatMap(.split(" ")).map((,1))
.groupBy(._1)
.map(x=>(x.1,x.2.map(.2)
.reduce(+)))
















 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









