







原理
hadoop中声明是有机架感知的功能,能够提高hadoop的性能。
- hadoop启动时会检查core-site.xml中的一个配置选项:topology.script.file.name,如果这个选项不为空,hadoop就会认为这是一个可运行脚本,于是在每检测到一个slave连接上jobtracker或者namenode时就会把这个slave的hosts或者IP地址作为参数传给这个脚本,然后期待这个脚本的返回值返回这台slave所述的rack名。而这个脚本内部具体是如何决定slave和rack的映射hadoop是不关心的。所以,哪台机器属于那个rack,其实是由写这个脚本的人决定。如果topology.script.file.name没有设定,则每个hosts和IP都会翻译成/default-rack。
实现步骤
- 在core-site.xml配置文件中加入一下配置选项:
<property>
<name>topology.script.file.name</name>
<value>/opt/sohuhadoop/conf/rack.sh</value>
</property>
-
编写rack.sh脚本,为每一个地址输出其所属的rack,由于jobtracker只识别hosts,而namenode只识别IP,所以在配置机架信息时,hosts和IP都得配置
rack.sh代码如下:
#!/bin/bash
HADOOP_CONF=/opt/sohuhadoop/conf
while [ $# -gt 0 ] ; donodeArg=$1exec< ${HADOOP_CONF}/topology.dataresult=""while read line ; doar=( $line )if [ "${ar[0]}" = "$nodeArg" ] || [ "${ar[1]}" = "$nodeArg" ]; thenresult="${ar[2]}"fidoneshiftif [ -z "$result" ] ; thenecho -n "/default/rack "else#echo -n "$result "echo "$result "fidonetopology.data机架信息如下(只列出部分):
10.10.69.167 zw-hadoop-slave-69-167. /rack/ZWB1
10.10.69.168 zw-hadoop-slave-69-168. /rack/ZWB1
10.10.69.169 zw-hadoop-slave-69-169. /rack/ZWB1
10.10.69.170 zw-hadoop-slave-69-170. /rack/ZWB3
10.10.69.171 zw-hadoop-slave-69-171. /rack/ZWB3
10.10.69.172 zw-hadoop-slave-69-172. /rack/ZWB4
10.10.69.173 zw-hadoop-slave-69-173. /rack/ZWB4
10.10.69.174 zw-hadoop-slave-69-174. /rack/ZWB4
10.10.69.175 zw-hadoop-slave-69-175. /rack/ZWB4
10.10.69.176 zw-hadoop-slave-69-176. /rack/ZWB4
10.10.69.177 zw-hadoop-slave-69-177. /rack/ZWB6 - 重启jobtracker和namenode
网络拓扑
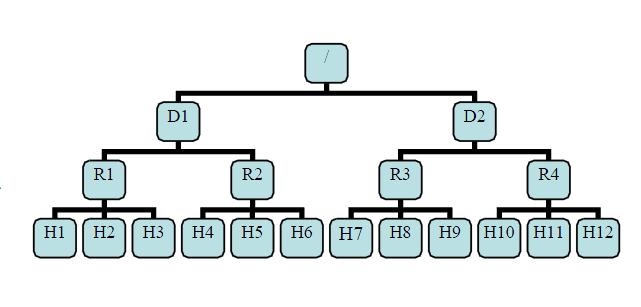
有了机架感知,NameNode就可以画出上图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
副本放置策略
第一个block副本放在和client所在的node里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node)。
第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
第三个副本和第二个在同一个机架,随机放在不同的node中。
如果还有更多的副本就随机放在集群的node里。
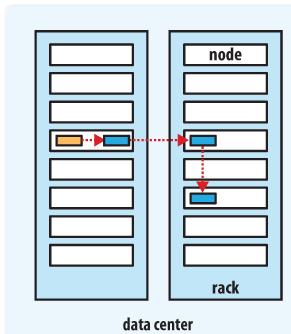
Hadoop的副本放置策略在可靠性(block在不同的机架)和带宽(一个管道只需要穿越一个网络节点)中做了一个很好的平衡。下图是备份参数是3的情况下一个管道的三个datanode的分布情况。















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









