








9.7 Stack Engine
Sandy Bridge 设计了独立的stack engine,工作方式与之前的处理器中的Stack Engine相同。
引入7.7 Stack Engine对stack的介绍
栈指令,比如push,pop,call 和ret都会修改栈指针。例如,指令push EAX将会在P3 处理器上产生3条uop,两条用于存储EAX,一条用于将ESP减4。在PM中,相同的指令只会产生一条uop。两条存储uops通过uop fusion的方式合并为一条,ESP-4则是通过一个专门用于计算ESP的加法器执行的,成为stack engine。Stack Engine 被放置在指令被译码的阶段,在乱序执行core之前。Stack Engine可以每周期处理3条加法。因此,没有指令需要在栈操作之后等待栈指针的更新。使用这个技术的并发症就是ESP的值可能在乱序执行core中读取或者修改。需要一个特殊的机制来同步stack engine和乱序执行核的栈指针的值。ESPp的真实逻辑值通过一个乱序执行核内的32bit的ESPo寄存器,或者是寄存器File 以及有符号存储在stack engine中的ESPd寄存器来获得。
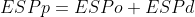
译者注:我们再来回顾一下为什么早期的一条push指令需要3条uop
push EAX
1)将ESP-4;
2)读取EAX的值,将EAX的值存入ESP-4地址Stack Engine 将偏移值ESPd作为偏移放入每个栈操作的一个地址字节中,因此它可以在port2或者port3的地址计算单元中加到ESPo上。ESPd的值不能被放到每一个可能使用栈指针的uop中,只能是那些up由push,pop,call和ret产生的uop中。如果stack engine遇到了其他的使用ESP的uop,或者是ESPd的值非0。那么后面的uop可以使用ESPo作为栈指针的真实的值。这条操作栈指针的指令之后的同步ESP的指令已经被译码,并且不会影响译码器。
同步机制可以被下面的简单的例子阐述:
; Example 7.3. Stack synchronization
push eax
push ebx
mov ebp, esp
mov eax, [esp+16]这个指令序列将会产生4条uops。假设启动时ESPd为0,第一条push 指令将会产生1条uop,将EAX的指写入[ESPo-4]的内存中并且将ESPd-4。第二条Push指令将会产生另一条uop,将EAX的指写入[ESPo-8]的内存中并且将ESPd-8。当stack engine接收到来自译码器的mov ebp, esp的微指令,他将会插入一个同步uop,将-8加到乱序执行核内部的ESPo上。在同一时刻,它会将ESPd设置为0. 同步uop在mov ebp, esp之前进入流水线,所以mov指令可以将ESPo认为是真实的ESPp的值。在最后一条指令,mov eax, [esp+16],也需要ESP的值,但是我们不会再增加同步操作,因为ESPd的值在此刻为0,所以没有必要进行同步操作。
需要同步ESPo的指令包括所有的使用ESP作为源操作数或者目标操作数,比如mov eax esp,mov esp eax和add esp,4 也包括那些使用esp作为指针的指令,比如mov eax,[esp+16]。如果只是写入esp看上去是没必要插入同步指令。如果是将ESPd设置为0,那么是没必要的。但是如果想要区分mov esp,eax和add esp,eax就会将逻辑复杂化。
同步uop在ESPd将要溢出时,也会进行。8bit的有符号ESPd将会overflow,在连续进行32次push eax或者64次push ax的指令时。在大多数的case中,我们将会在29条push或者是call 指令时插入同步uop,以防止下一个周期连续进入3个译码器的都是push指令而导致overflow。在同步uop之前最多31条uop,会发生在最后三条push指令在同一个周期进入的case中。POP和RET指令同理。实际上你可以使用比PUSH更多的POP指令,因为esp value存储的形式是-ESPd。而最小的有符号数是-128,最大的是127。
【译者注】CALL和RET指令的介绍
CALL 指令调用一个过程,指挥处理器从新的内存地址开始执行。过程使用 RET(从过程返回)指令将处理器转回到该过程被调用的程序点上。
从物理上来说,CALL 指令将其返回地址压入堆栈,再把被调用过程的地址复制到指令指针寄存器。当过程准备返回时,它的 RET 指令从堆栈把返回地址弹回到指令指针寄存器。32 位模式下,CPU 执行的指令由 EIP(指令指针寄存器)在内存中指岀。16 位模式下,由 IP 指出指令。
调用和返回示例
假设在 main 过程中,CALL 指令位于偏移量为 0000 0020 处。通常,这条指令需要 5 个字节的机器码,因此,下一条语句(本例中为一条 MOV 指令)就位于偏移量为 0000 0025 处:
main PROC
00000020 call MySub
00000025 mov eax,ebx
然后,假设 MySub 过程中第一条可执行指令位于偏移量 0000 0040 处:
MySub PROC
00000040 mov eaxz edx
.
.
ret
MySub ENDP
当 CALL 指令执行时如下图所示,调用之后的地址(0000 0025)被压入堆栈,MySub 的地址加载到 EIP。
执行 MySub 中的全部指令直到 RET 指令。当执行 RET 指令时,ESP 指向的堆栈数值被弹岀到 EIP(如下图所示,步骤 1)。在步骤 2 中,ESP 的数值增加,从而指向堆栈中的前一个值(步骤 2)。同步uop可以在port0 和 por1的两个整数计算单元中的任何一个进行计算。他们的retire与其他的uop的退休方式类似。PM有一个恢复表用于在分支预测错误的情况下恢复,以解耦stack engine带来的影响。
下面的例子说明了同步uop是如何在典型的程序流中生成的:
; Example 7.4. Stack synchronization
push 1
call FuncA
pop ecx
push 2
call FuncA
pop ecx
...
...
FuncA:
push ebp
mov ebp, esp ; Synch uop first time, but not second time
sub esp, 100
mov eax, [ebp+8]
mov esp, ebp
pop ebp
retMOV EBP, ESP 指令在FuncA函数中在push、call、和push指令之后。如果ESPd在一开始是0,那么最后它会变成-12。在执行MOV EBP,ESP指令之前,我们需要一个同步uop。SUB ESP,100 和MOV ESP EBP不需要同步指令,因为在同步指令之后就没有push 或者pop指令了。在此之后,我们有一个指令序列POP/RET/POP/PUSH/CALL/PUSH,而后我们再次遇到MOV EBP,ESP(第二次调用函数时)。ESPd此时已经计数到12然后又回到了0(即三次累加和三次递减)。所以第二次的时候我们不需要同步指令。如果POP ECX 被ADD ESP,4所取代,那么我们需要在执行ADD ESP,4之前需要一个同步指令,在第二次遇到MOV ESP,ESP时也是需要。如果我们将POP ECX/PUSH 2替换成MOV DWORD [ESP],2 时也会发生相同的情况(即需要同步uop)。但是如果替换成MOV DWORD [EBP],就不需要了。
我们可以制定一个规则,以预测同步指令会在插入以下指令流的情况下会产生:
- 使用如下的stack engine的指令:push,pop,call,ret,除了RET n.
- 在乱序核中使用栈指针。比如指令使用ESP作为源、目标或者指针以及CALL FAR,RETF,ENTER
- 既使用stack engine,又使用乱序核的栈指针的指令,比如:PUSH ESP, PUSH [ ESP] +4, POP [ESP+8], RET n.
- 总是同步ESPo的指令,PUSHF(D),POPF(D),PUSHA(D),POPA(D),LEAVE.
- 无论如何都不唤醒栈指针的指令
从上面1-5的一系列的指令都不会产生任何的同步指令,除非ESPd要溢出了。从2-5的一系列的指令不会产生任何的同步指令。如果来自2类的指令在1类的指令之后,那么会产生一个同步uop,除非ESPd是0。来自3的指令在大多数的情况下都会产生同步指令。来自4类的指令会产生一个来自decoder的同步uop,而不是来自stack engine。即使是ESPd=0。
你可能想要使用这个规则以减少同步指令的数目,以避免那些每周期3条uop是瓶颈 和 执行单元0和1都已经满负荷的情况。你不需要在意这些指令,如果瓶颈在其他地方。
【译者注】
总的来说,stack engine位于decoder和乱序执行核之间。
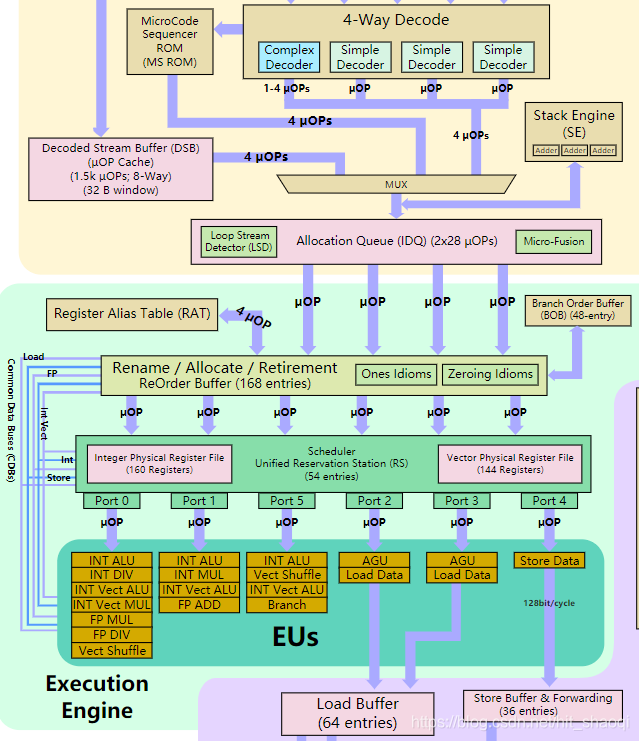
正常的push EAX 这样的指令,是需要ALU对ESP的值计算后,再调用store(如果是pop会是load),那么对应的uop就会三条(如果采用了microuop fusion技术,会是两条)。而如果出现连续的push指令,如果没有采用stack engine,按照传统的寄存器重命名技术,会存在读后写的依赖,即需要读取ESP的值后+/- 4,再存回ESP,以便下一条push仍然可以使用准确的值,而导致性能的降低。
stack engine的思想就是一旦检测到push,pop指令,既然他们都是固定的+4/-4,那么直接就只乱序执行核之前把偏移计算好,那么就只需要store、load uop了(偏移和基准ESP的计算在AGU中执行),这样将三条uop减少到1条uop,而且解除了对ESP的依赖。
另一方面,我们知道在乱序执行核内,会存在物理架构寄存器即physical register file,用于存放寄存器的值。而如果是mov eax, [esp+16]这样的指令,是需要获取真实的esp的值的。所以Stack Engine会检测decoder发出的指令流中是否会使用ESP作为源/目标寄存器,如果存在这样的指令,就在该指令之前加上一条同步ESP的指令,更改physical register file 中的ESP的值,这样后续的指令流可以拿到真实的ESP了。
翻译自【Microarchitecture of Intel and AMD CPU An optimization guide for assembly programmers and compiler makers】
欢迎关注我的公众号《处理器与AI芯片》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









