








这个blog的系列文章会介绍最近的security Spectre和Meltdown。
程序是如何执行的
一段程序就是在memory中的一系列指令。这些指令在处理器中一条接一条的被执行。每个指令执行时都有其对应的特权级别,privilege level。
特权级别在X86指令集中,控制当前运行在处理器上的程序的访问资源权限,比如memory区域,I/O 端口以及特殊的指令。
因此,这基本上也意味着在处理器上执行的任何指令都是有特殊的权限级别,可能只能访问系统资源(memory region或者IO端口)的一个子集。
Intel X86架构提供了4中特权级别,可以被操作系统厂商使用。Linux只使用了其中的两种。
- Level3 (ring 0)
内核工作在这个模式。这个特权级别确保我们拥有所有的硬件,指令集,memory的权限。这是必须的,因为内核需要访问所有的硬件资源以及不同的进程的memory region。 - Level0 (ring 3)
所有的用户进程工作在这个模式。使用这个模式,用户只对memory的一段有着受限制的权限。任何硬件相关的任务(磁盘IO或者网络IO),都需要通过系统调用,来引入内核。系统调用可以将特权级别从用户模式切换到内核模式。

Note:不只是memory区域或者IO端口,这些level也会阻止特权指令在用户模式下被执行。比如HLT,RDMSR指令。参见
Memory Isolation
内存被不同的进程以及kernel通过页表进行划分。每个进程都有page table。
进程使用虚拟地址,而不是物理地址来进行load/store操作。这意味着从虚拟地址到物理地址的转换需要经过页表的帮助。因为页表也是存储在内存中的,这样每次内存访问都会花费大量的时间,而降低我们进程的性能。因此,我们处理器都有TLB(translation lookaside buffer)作为一个fast cache实现虚拟地址到物理地址的映射。
页表也被分为两个部分。一个是用户进程页表,另一个存储内核页表项。内核页表在memory寻址时也十分重要,在特权模式的内核模式时,用于访问内核数据。

此外,处理器中也有cache,用于缓存最近访问过的数据,用于加速访问。
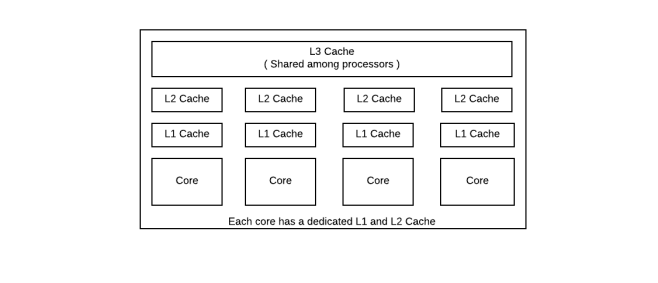
此时,我希望你们对CPU架构已经有了大致的了解。但是在进一步讨论spectre和meltdown危害时,让我们先理解以下概念
:
- Flush Reload Attack
- Speculative Execution
Flush Reload Attack
这种攻击中,攻击者会利用cache的行为来确定victim进程在memory中的访问。L3 cache在不同core上运行的不同的进程中共享,因此通过这种攻击,我们可以观测victim 进程的执行过程。
问:但是我们如何利用cache的行为呢?
答:我们知道,如果一个数据在L3 cache中被缓存,那么相对于数据没有被缓存,数据从DDR中读取,需要的时间会很短。
因此如果一个攻击者想要发现是否一个地址的数据已经被另一个core访问过,attacker只需要知道attacker读取该数据的时间即可。如果时间比较久,那么,那么另一个core就没有被访问过,数据没有被缓存。反之,那么另一个core已经访问过。这个方法的先决条件是,在进行攻击之前,该地址已经被从cache中flush掉。
因此,攻击者可以明确victim进程执行了哪段代码。
另一个有趣的发现就是,参见,我们可以明确victim process在操作那个数据。这个有点意思,让我们先通过例子理解它。
Victim Process A
for (int i = 0; i < PUBLICLY_NOT_KNOWN; i++) {
performFunction(PUBLICLY_KNOWN);
}
1. 有数据PUBLICLY_KNOWN
2. 在该数据上执行特定的操作performFunction
3. 这个操作函数f会被调用PUBLICLY_NOT_KNOWN次
4. 现在我们的目标就是找到数字PUBLICLY_NOT_KNOWN
Attacker Process B
1. 我们已经知道 PUBLICLY_KNOWN
2. 我们已经知道performFunction的内存地址
3. 我们也知道这个函数需要t ms
4. 我们先flush掉performFunction函数所在的cacheline
5. 然后初始化PUBLICLY_NOT_KNOWN为0
6. 每过t ms,我们检查是否这个函数被访问过,这个可以通过上面提到的flush-reload操作来说确定是否该内存被访问过
7. 如果访问过,那么就将PUBLICLY_NOT_KNOWN+1。否则就结束loop
8. 结束时,我们就得到了PUBLICLY_NOT_KNOWN的值。
译者注:这个应该是认为每tms,都会又一次f函数的调用,直到循环结束。通过持续的判断该函数有没有被加载进cache,即可判断是否已经结束循环,停止调用。
因此这个flush-reload attack可以被attacker使用,来确认victim 进程中的秘钥。以上的攻击方法可以在RSA解密秘钥中使用,参见
Speculative Execution
推测执行是一种优化技术,处理器可能会执行不需要的任务。在其直到最终是否需要执行之前,预先执行,因此可以减少最终知道是否执行这段时间的延迟。如果最终不需要执行,那么就退回给之前的变化,并忽视不需要执行的任务的结果。
之前的处理器顺序的逐条执行指令。但是推测执行的技术使得处理器可以进行一些预测执行。预测执行显著的增加了现代处理器的性能。
为了更好的预测执行,我们执行下面的简单操作:
if (x < p.size) { // first instruction
int b = p[x] // second instruction
} else {
int b = 1 // third instruction
}
在这段代码中,我们可以看到我们会为x检查边界,如果x在边界内,则使用x作为offset访问p。
Inline processing(逐条执行)意味着每次都会检查X与边界进行比对,然后按照x作为offset访问memory。换句话说,我们顺序的执行,一条接着一条。
但是如果是预测执行,我们不需要等待第一条指令的结果,就可以开始后面的指令的执行。
大多数的时候,这段代码执行时,分支1都会被taken,因此一般也会将branch1的结果预测为1.
因此有了分支预测的帮助,推测执行,一般会执行第二条指令。
注意:我们可能会在最终结束时,分支预测器预测错误而执行了错误的分支。在这些情况下,这些错误的指令相关的状态会被清除掉。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









