







 本文是Python网络爬虫系列的第二部分,主要讲述如何解析网页并提取所需数据。通过requests库获取网页内容,讨论了当响应头部没有明确字符编码时,requests如何使用'chardet'模块猜测编码,以及如何自定义函数提高解码准确性。推荐使用parsel模块进行网页结构化数据提取,因为它基于lxml且使用简便。最后,提供了作者的网页解析封装代码示例。
本文是Python网络爬虫系列的第二部分,主要讲述如何解析网页并提取所需数据。通过requests库获取网页内容,讨论了当响应头部没有明确字符编码时,requests如何使用'chardet'模块猜测编码,以及如何自定义函数提高解码准确性。推荐使用parsel模块进行网页结构化数据提取,因为它基于lxml且使用简便。最后,提供了作者的网页解析封装代码示例。
在第一篇中,我们介绍了如何进行发起一个http请求,并接受响应。在这一部分中,我们介绍一下如何解析网页并提取我们需要的数据。
我们采用requests这个库进行一个网页请求。
r = requests.get('https://www.example.com', headers, **kwargs )通过这一句代码,我们即可获得服务器传给我们的响应内容(不考虑连接错误等情况)。
假设返回的是200的响应。一般情况下我们请求的都是静态的html纯文本网页,采用r.text即可获得我们想要的网页内容。requests会自动为我们解压缩以及进行网页字符解码。默认情况下,requests会采用响应headers中的指定的字符编码进行解码。
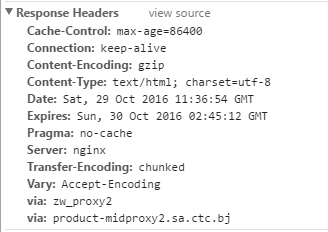
如上图所示,这是一个非常标准的http response头部,现在我们重点看content-type那一行,在这一行中,我们可以看到’charset=utf-8’,这就说明了网页是采用’utf-8’字符编码的,requests也会采用’utf-8’为网页进行解码,完全没有任何问题。
但是,如果response的头部没有’charset=utf-8’字符编码提示呢?那requests是如何进行解码的呢?
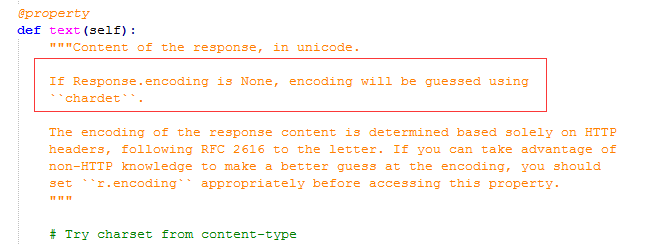
上图是requests模块对r.text这个资料描述符的解释。我们可以看到,如果在响应的头部没有’charset=utf-8’,那么requests就会用’chardet’这个模块进行编码猜测。然后用猜测到的字符编码进行网页解码。那么,问题来了,字符编码猜错的可能性是存在的。那我们该如何降低这种错误率呢?
其实在目前大部分的网页中(可以用4个9表示), 是给出了网页对应的字符编码的,如下图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









