






《Deep Learning for Single Image Super-Resolution: A Brief Review》
《A Deep Journey into Super-resolution: A Survey》
LR图像建模:
↓s
其中x⊗k是模糊核k和未知HR图像x之间的卷积,↓s是具有比例因子s的下采样算子,n是独立噪声项。用图像可表示为:
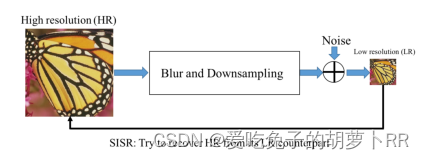
迄今为止,SISR的主流算法主要分为三类:基于插值的方法、基于重构的方法和基于学习的方法。
1、基于插值的SISR方法,如双三次插值和Lanczos重采样,非常快速和直接,但存在精度缺陷。
2、基于重构的SISR方法,通常采用复杂的先验知识来限制可能的解决方案空间,优点是生成灵活和清晰的细节。然而,当比例因子增加时,许多基于重建的方法的性能迅速下降,且较为耗时。
3、基于学习的SISR方法,也称为基于示例的方法。这些方法通常使用机器学习算法从大量的训练实例中分析LR与其对应的HR之间的统计关系。研究人员将稀疏编码方法应用于SISR问题,如随机森林也被应用于改善重建性能。
4、最近,基于DL的SISR算法已经证明了其优于基于重构和其他基于学习的方法。
SRCNN中使用插值的三个不足之处:
1、输入引入的细节平滑效果可能导致图像结构的进一步错误估计;
2、使用内插作为输入非常耗时;
3、当下采样核未知时,作为原始估计的一个特定内插输入是不合理的。
当前网络的改进方向:
1、使用CNN学习上采样映射,以代替插值法;
2、使用更深的网络增加精度;
3、将SISR过程的特性与CNN框架的设计相结合。
现有SISR方法分类:
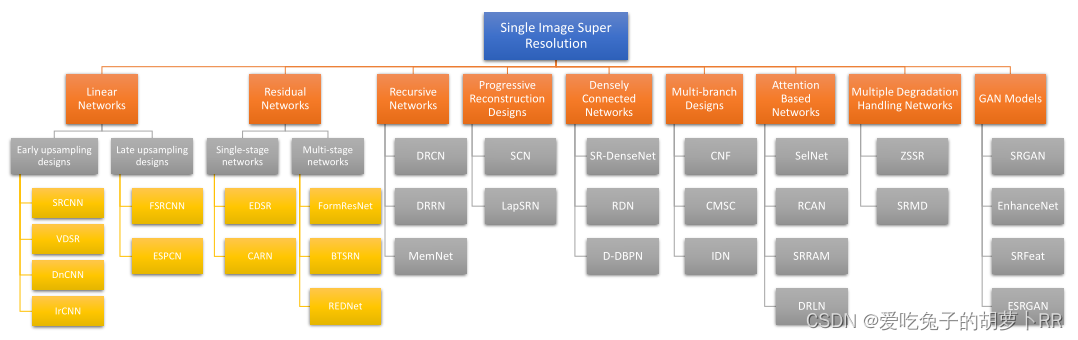
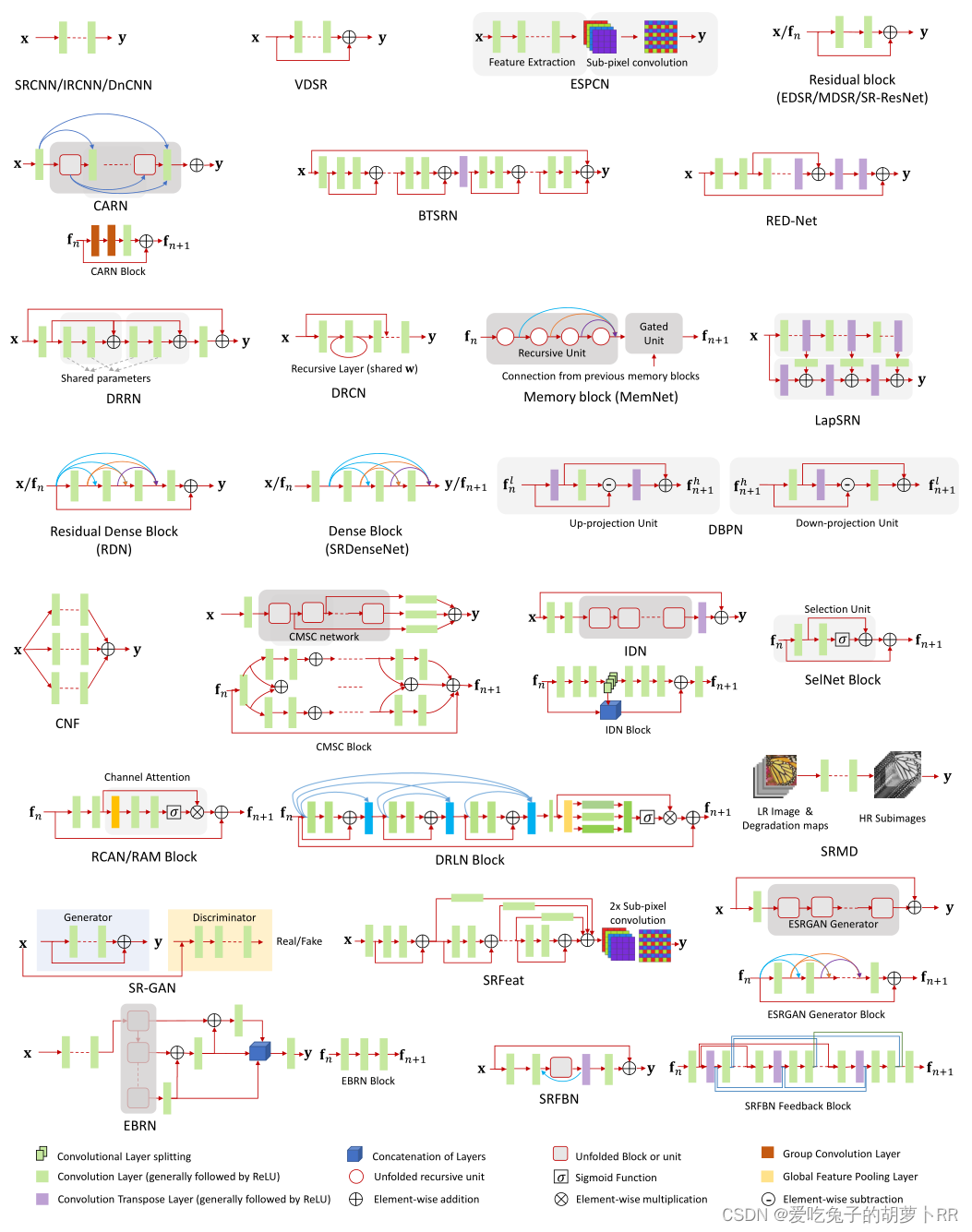
现有基于深度学习的SR重建网络的一些架构:















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









