









贪婪深度字典学习
原文地址:http://blog.csdn.net/hjimce/article/details/50876891
作者:hjimce
一、相关理论
近几年深度学习声名鹊起,一个又一个AI领域被深度学习攻破,然而现在大部分深度学习所采用的算法都是有监督学习的方法;有监督学习需要大量的标注数据,需要耗费大量的人力物力。因此当有监督学习算法达到瓶颈的时候,无监督学习必将成为未来深度学习领域的研究焦点,使得深度学习更接近于人类;毕竟无标签数据一抓一大把、到处都是,如果我们可以搞好无监督学习,这才是牛逼人工智能。
无监督表征学习,除了自编码、受限玻尔兹曼机之外,k-means、稀疏编码等也是无监督表征学习的重要算法。无监督表征学习算法的应用主要分两种:
(1)用于神经网络的无监督预训练。这个我们在深度学习里面经常遇到,比如自编码、RBM就可以分别用于SAE、DBN深度网络的预训练;
(2)无监督特征抽取,然后用抽取到的特征做分类任务;这个说白了就是先用无监督算法抽取高层特征,然后再用SVM来训练特征分类器,像稀疏编码、k-means表征学习一般是这么使用的,当然AE、RBM也可以这样使用。
本篇博文主要讲解我最近所学的一篇paper:《Greedy Deep Dictionary Learning》。这篇文献主要提出了一个深度字典学习方法,字典学习也可以简单的称之为稀疏编码。文献算法主要是受了栈式自编码、DBN训练方法的启发,提出逐层贪婪深度字典学习。
二、贪婪深层字典学习
之前人们所研究的算法都是针对单层字典学习(浅层字典学习),然而我们知道深层模型具有更抽象、更牛逼的表征能力。既然单层自编码对应的DL模型“栈式自编码”;RBM也有对应的DL模型“深度信念网络”;于是文献借助于这思想,也提出了单层字典学习的对应DL算法:深度字典学习。
1、字典学习相关概念
从矩阵分解角度看字典学习过程:给定样本数据集X,X的每一列表示一个样本;字典学习的目标是把X矩阵分解成D、Z矩阵:
X≈DZ
同时满足约束条件:X尽可能稀疏,同时D的每一列是一个归一化向量。这样就相当于求解目标函数:
D称之为字典,D的每一列称之为原子;Z称之为编码矢量、特征、系数矩阵。除了上面这个损失函数之外,字典学习还有另外两种形式的损失函数,比如k-svd字典学习算法,求解的目标函数就是:
具体字典学习相关概念,可以参考我的另外一篇博文《k-svd字典学习》,这边不再啰嗦。
2、深层字典学习
我们前面讲到字典学习说白了就是矩阵分解:
X=DZ
这是一个单层矩阵分解,就相当于单层神经网络一样。而文献所提出的算法是多层字典学习,也就是多层矩阵分解:
X=D1*D2*Z
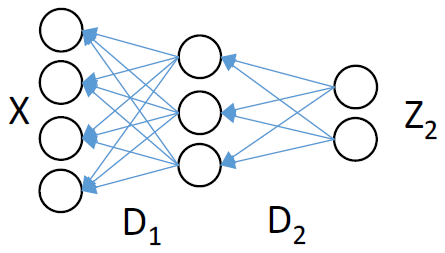
首先字典学习它是个非凸优化问题,多层字典学习将会变得更加复杂;另外多层字典学习的所要求解的参数大大增加,在有限的训练样本下,容易引起过拟合问题。因此文献提出类似于SAE、DBN一样,采用逐层训练学习的思想,这样可以保证网络的每一层都是收敛的。算法其实非常简单,以双层分解为例进行逐层分解,具体示意图如下:
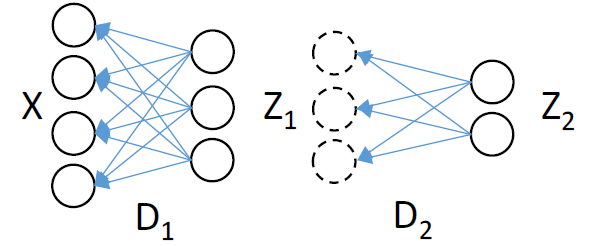
(1)我们首先训练学习出第一层特征Z1、权重D1:
X=D1*Z1
(2)然后对特征Z1进行分解,求解第二层权重D2、特征Z2:
Z1=D2*Z2
以此类推,就可以实现更深层的字典学习。OK,这就是文献的算法,没了……(感觉啥也没学到的样子,给我的感觉很low,跟文献《A deep matrix factorization method for learning attribute representations》没得比呀,这篇文献至少还有整体微调阶段)
3、paper使用方法
在每一层字典学习的时候,我们可以通过添加约束项,选择稠密特征或者是稀疏特征。
(1)如果要求解稠密特征,那我们就直接求解目标函数:
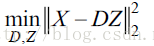
也就是没有了稀疏约束项。求解方法采用类似lasso,即对两个变量Z、D交替迭代的方法:
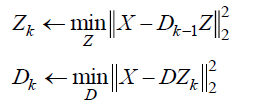
(2)如果要求解稀疏特征,那么我们就用L1正则约束项:

然后迭代公式就是:
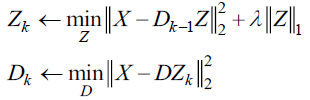
对于第二个公式Dk的求解,也是求解一个最小二乘问题。对于稀疏编码Zk的求解采用ISAT算法,如下公式:
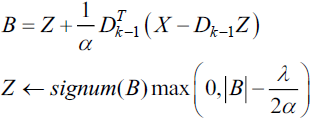
以前字典学习,一般字典的初始化都是从样本中随机抽取的,然而本文采用的是QR分解,从Q矩阵中按顺序,提取出正交向量,作为初始字典。另外文献最后采用的网络模型是,除了最后一层采用稀疏编码之外,其它层都采用的稠密特征。
三、与RBM、自编码的区别、联系
1、与RBM的联系
RBM是损失函数是采用数据分布相似性度量,而字典学习是采用欧式距离损失函数。RBM要求数据介于0~1之间,如果数据超过这个范围,那么就需要做归一化处理。在大部分情况下,归一化对于我们所要的性能可能没啥影响,但是在某些特定的情况下它会抑制一些重要的信息。然而字典学习可以让我们输入任意复杂的数据。
2、与自编码的联系
从我们的分析来看,自编码是学习W,使得W*X=Z,然而字典学习的目标是学习D使得X=DZ。也难怪文献中的字典学习网络的线是画相反的方向。
四、试验结果
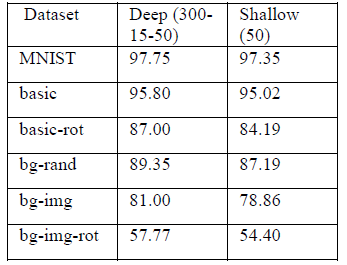
1、浅层学习与深层学习对比
文献对比了浅层表征学习和深层表征学习的结果,采用两种方法进行特征Z的学习,然后采用k近邻进行分类测试,结果如表一所示。
2、与SAE、DBN的对比
三个网络模型都采用3层网络,每层网络神经元一次减半。同样的我们利用这两个算法进行表征学习提取高层特征,然后利用高层特征进行分类:KNN,SVM,测试结果得到表格2、3
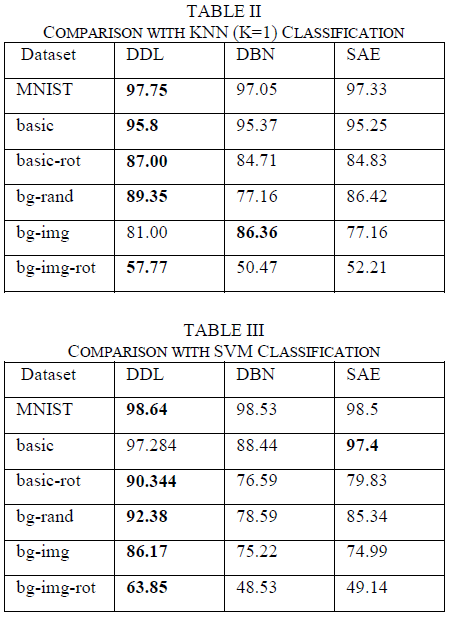
最后再采用fune-tuning后的DBN、SAE,与本文的算法做出了对比,得到结果表格IV。可以看到,在某些情况下,即使是fine-tuning的DBN、SAE,精度也比不上文献的算法DDL:

个人总结:这篇文献其实非常简单,就仅仅是讲解X=D1*D2*Z的一个求解方法,然而文献竟然啰嗦了将近10页;而我竟让这篇博文也写了这么多,感觉自己快成了说书的了,越来越能扯……不过文献所提出的算法虽然简单,但是作者通过验证对比,确实是非常牛逼的效果,在无监督的条件下,比自编码、RBM都要牛逼,甚至连fine-tuning的自编码、RBM在某些任务下,都无法与之匹敌。不过这个还是比较喜欢另外一篇文献:《A deep matrix factorization method for learning attribute representations》,这篇文献讲的是深度非负矩阵分解,里面的创新点非常多,这样可以学到更多的知识,感觉才比较充实。
参考文献:
1、《Greedy Deep Dictionary Learning》
2、《A deep matrix factorization method for learning attribute representations》
**********************作者:hjimce 时间:2016.3.13 联系QQ:1393852684 原创文章,转载请保留作者、原文地址信息********************















 1929
1929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









