






网易云评论进行LDA主题模型分析
前言
这个项目是在学校参加竞赛下与另一个同学一起做的,我负责的是对评论进行LDA主题模型的分析。写这篇文章是想记录一下学习过程,有什么地方描述的不对还请大家多多指教,一起进步。
在此之前,也是在网上学习了一些关于LDA主题模型的知识。下面就看看如何通过Python将数据进行 LDA 主题提取。
什么是LDA主题模型,它可以用来做什么?
我想大家都很好奇LDA主题模型是什么,它可以用来做什么呢?
下面是chatGPT的回答:LDA (Latent Dirichlet Allocation) 是一种无监督学习的主题模型,它可用来捕获文本中的主题结构。LDA 假设一个文档由多个主题组成,每个主题又由若干单词组成。在这个模型中,每个词都被赋予属于某个主题的概率,并由此推导出每个文档的主题分布以及每个主题的单词分布。LDA 主题模型可以用于很多自然语言处理的任务,如文本分类、信息提取、知识图谱构建、信息检索等。通过使用 LDA,我们可以挖掘大量文本中的潜在主题,从而帮助我们理解文本中的语义关系,抽取文本中的信息,并进一步应用于其他领域如推荐系统和广告推荐等。
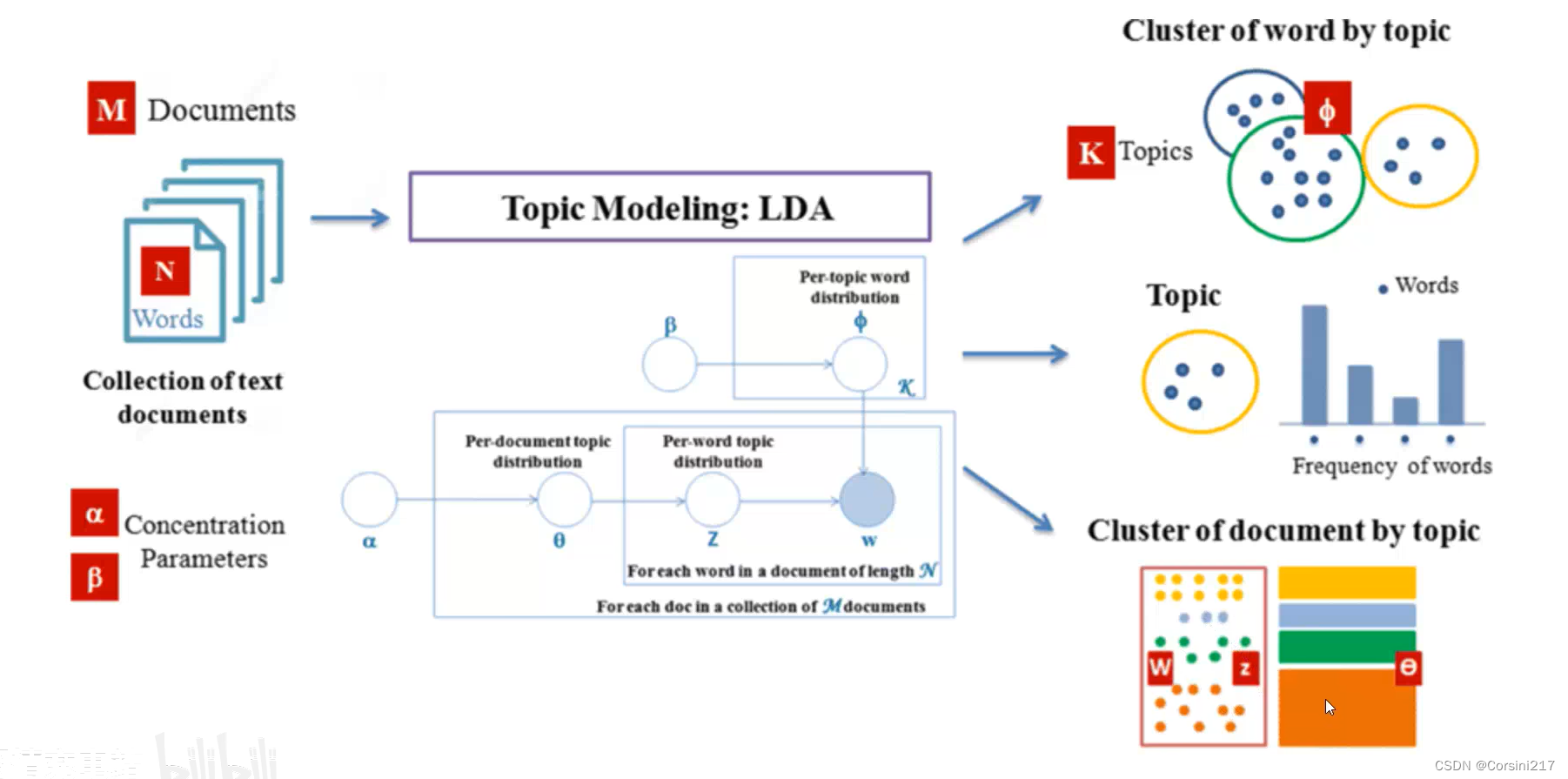
这张图是在b站学习中看到的,有兴趣的可以去看一下:https://www.bilibili.com/video/BV1a84y1b7vK/?spm_id_from=333.337.search-card.all.click&vd_source=551494896847f071eb11ab141c15a02d
首先,你要有语料,可以是几十或几百篇文章,然后把这些数据放进LDA模型,LDA模型会进行比较严格的数据统计,然后得到三个结果:
1.识别出语料中到底包含了哪些隐含的主题
2.在隐含主题中有哪些相关词,可以通过这些相关词对隐含主题进行名列
3.得到不同主题在一篇文章中的概率发布,依据概率的大小将该文章划入到某一主题中去
所用工具
pycharm2020.3.5
python3.9
库:
数据展示
这里我将数据放在了E盘
这里有两份数据一份是源数据,另外一份是进行数据预处理后的数据
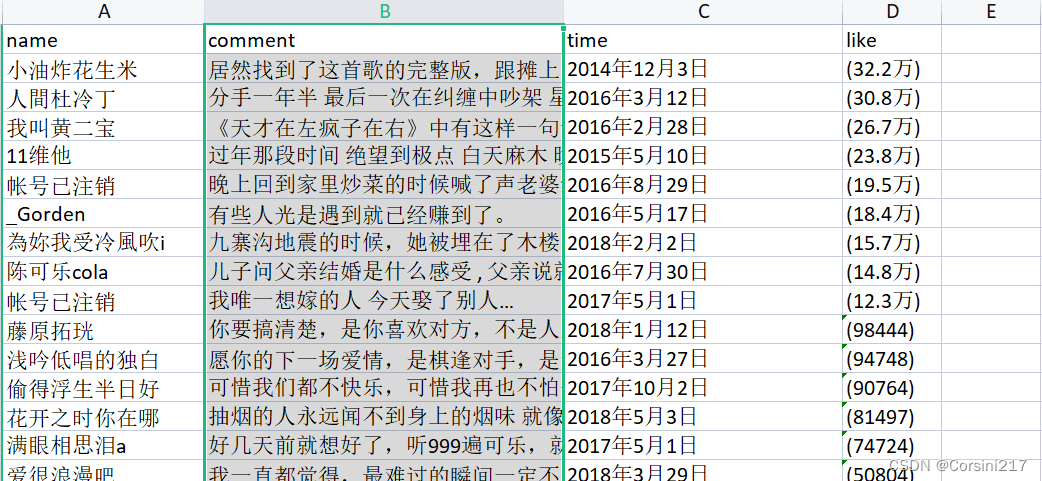
源数据内容如下:
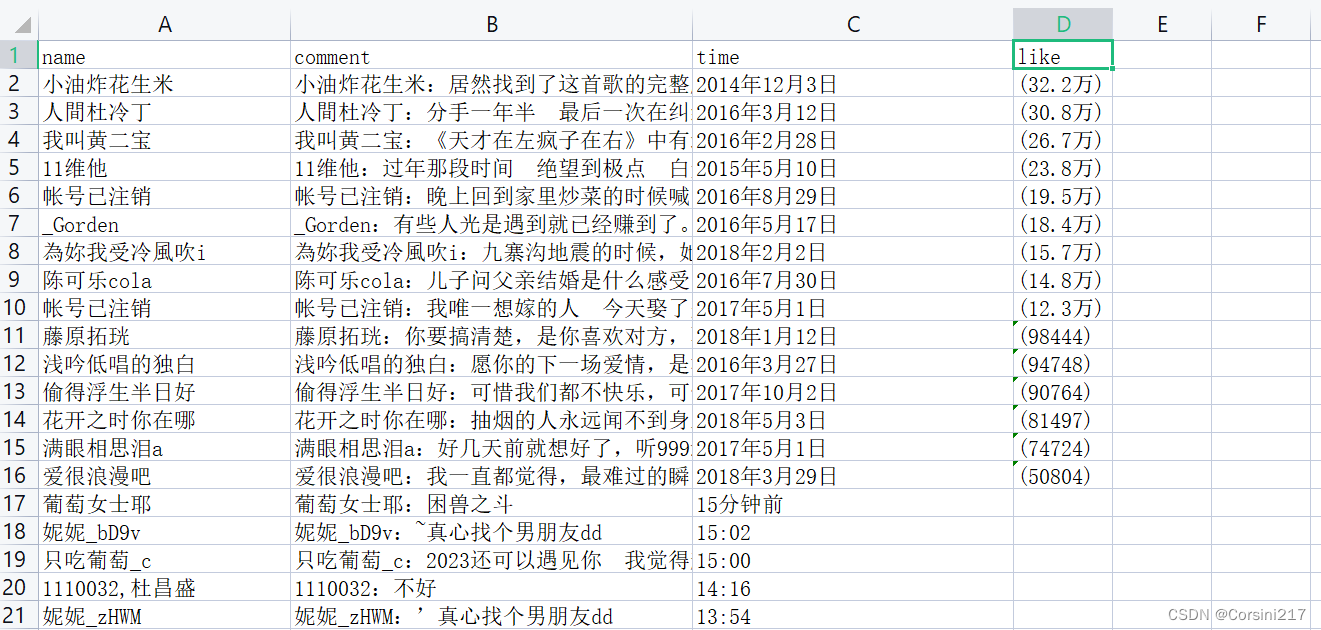
该数据有四个列,其中comment这一列的数据包括了用户的名字和评论内容,这里我们只要评论内容不要名字,因为前面已经有了,可以通过tableau prep进行数据的预处理(不知道tableau prep的同学可以看我的另外一篇文章是关于BOSS直聘的,里面有非常清楚的处理操作,这里就不一一操作了)。处理过后的数据如下:
读取数据
file_path后面放你数据的路径
file_path = r'E:/网易云数据评论/输出.xlsx'
if os.path.isfile(file_path):
df = pd.read_excel(file_path)
print(df.head()) #打印前五行数据
else:
print(f"File not found: {file_path}")
运行结果:

这里我们成功地将数据读取出来。
数据去重
我们知道,在网易云中,一首歌同一个用户可以评论多次,这里我只想要每一位用户第一次评论的内容,后面补充评论的就统统去掉。
#数据清洗 df是原始数据,df1是去重后的数据
#1.去除用户名重复的
df1 = df.drop_duplicates(subset=['name'])
用正则表达式和结巴分词对其内容进行清洗和分词
在有些评论里面有一些特殊的字符,这里我们需对其进行清洗和通过jieba进行分词
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
df1['cut'] = df1['comment'].apply(lambda x: str(x))
df1['cut'] = df1['cut'].apply(lambda x: re.sub(pattern, ' ', x))
df1['cut'] = df1['cut'].apply(lambda x: " ".join(jieba.lcut(x)))
print(df1['cut'])
代码解释:这段代码是在针对一个名为df1的数据框中的comment列,使用正则表达式和结巴分词对其内容进行清洗和分词。其中,正则表达式[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+用于匹配所有非中文字符、标点符号、空白符和数字。apply方法中的lambda函数则分别进行了替换、分词和拼接操作。最终,该代码将清洗好的文本保存在了一个名为cut的新列中,并打印出来。
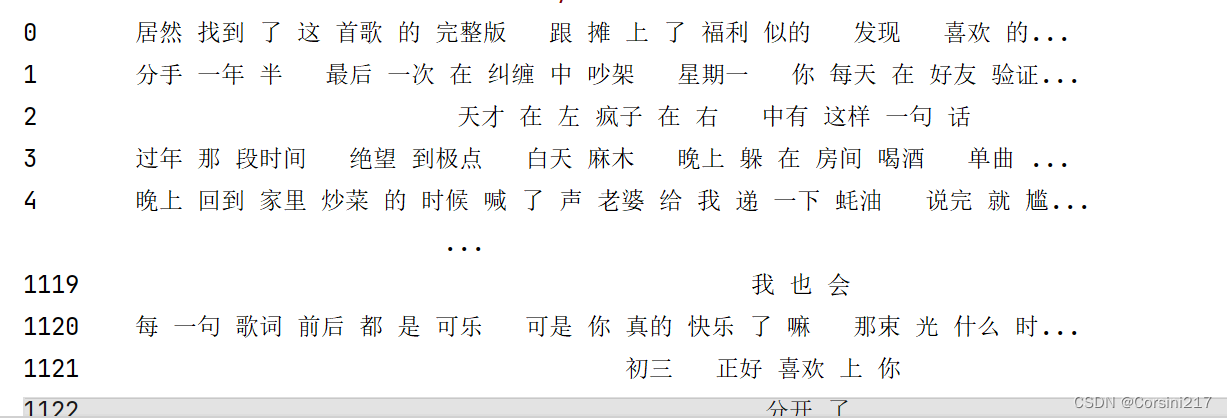
我们看看通过清洗和分词后的数据:
知识补充
文本转为向量
前面已经说了,LDA主题抽取是基于统计学来实现的,给评论内容的词进行标号,同时统计其所对应的词频,依次构造一个二维的词频矩阵。下面举个例子大家就明白了。
这里有两句话。

将两句话拆分成词(不考虑重复的),那就是

分别统计每个词在上面两句话中出现的词频,那么我们可以将这些数据制成表格

使用TF-IDF 构造词频矩阵
什么是TF-IDF,它是用来做什么的?
TF-IDF,全称为Term Frequency-Inverse Document Frequency(词频-逆文档频率),是一种用于信息检索与文本挖掘中的常用权重计算方式。
TF-IDF 的主要思想是通过计算一个单词在文本中的词频(TF)和在整个语料库中的逆文档频率(IDF),来确定一个单词在文本中的重要性。在某个文档中出现频率较高的词语,计算出来的TF-IDF值会高,并且在整个语料库中非常常见的词语,顺理成章的对应比较低的IDF值。这样,单词会被赋予一个反映其在文本中重要性和表达能力的权值。
TF-IDF值可以用于文本分类、聚类、查询相关度等场景中。在文本分类中,可以将每个文本的TF-IDF向量作为其特征输入,以进行文本分类的任务。
在实际应用中,我们可以使用sklearn库中的TfidfVectorizer等函数来实现对文本的TF-IDF向量化。
前面我们已经将comment里面的内容清洗和分词,并将清洗好后的文本保存在了df1中“cut”这一列里,下面我们将“cut”里的文本通过TF-IDF向量化。
# 1.构造 TF-IDF
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df1['cut'])
# 2.特征词列表
feature_names = tf_idf_vectorizer.get_feature_names_out()
# 3.将特征矩阵转换为 pandas DataFrame
matrix = tf_idf.toarray()
feature_names_df = pd.DataFrame(matrix,columns=feature_names)
print(feature_names_df)
下面是对上面三部分代码的解释:
- 使用了sklearn库中的TfidfVectorizer函数来创建一个tf-idf向量化器对象tf_idf_vectorizer。然后,该对象的fit_transform函数被用来将数据集df1中的文本内容作为输入,进一步生成tf-idf向量化后的特征矩阵tf_idf。在这个特征矩阵中,每个文本的tf-idf向量代表了该文本中每个单词的权重,这些权重是根据所有文本在训练过程中出现的单词计算得出的。这些权重通常表示单词在整个数据集中的重要性或者特殊性。
- get_feature_names()是TfidfVectorizer类中的一个方法,它返回由TfidfVectorizer对象中提取出的特征单词组成的列表,这些特征单词会被用来构建特征向量。特征向量是由训练集中的文档中的特征单词按照预定义的特征权重组成的向量。在使用TfidfVectorizer对文本进行向量化后,可以通过调用get_feature_names()来获取所有特征单词。
- 在这段代码中,toarray() 方法将 tf-idf 矩阵转换为一个 numpy 数组。然后,使用 numpy 数组来创建一个 pandas DataFrame,指定列名为特征单词列表(feature_names)。这样就可以得到一个以特征单词为列名,每行表示一个样本的 DataFrame,它的元素是该样本中该特征单词的 tf-idf 值。
打印结果如图:
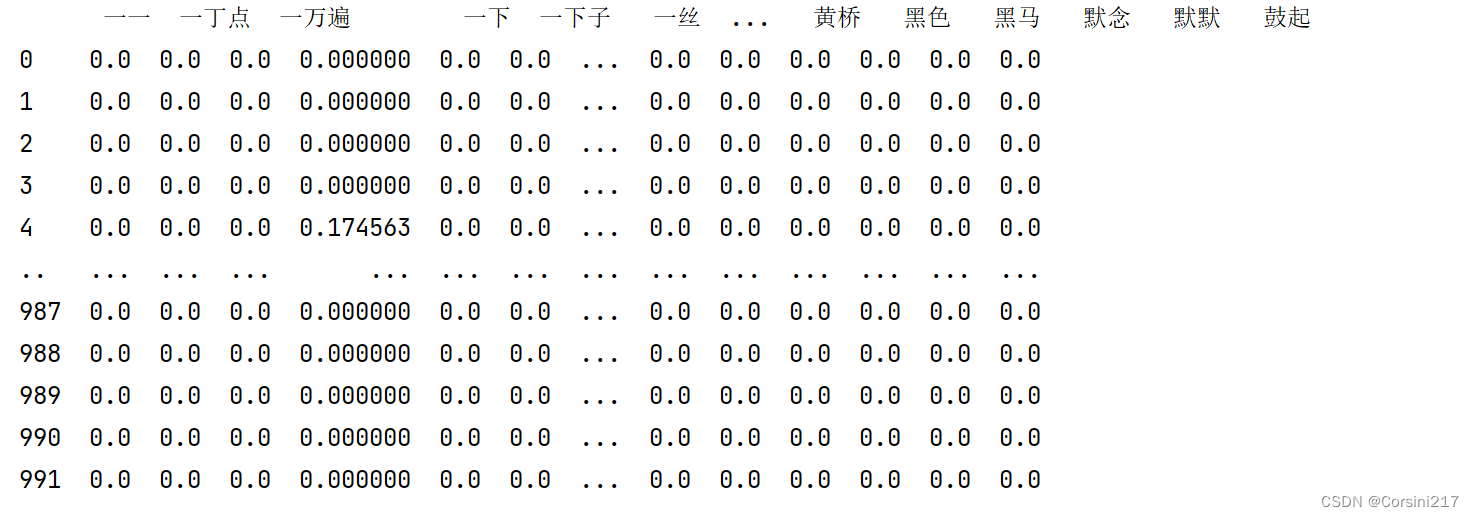
由于数据太长了,所以pycharm中只显示了前面和后面一小部分的内容,中间的省略掉了。
如果看不懂的话没关系,下面我再举一个小例子大家就明白了。
# 假设我们有一个文本列表
texts = ['天天 想着 玩', '天天 不想 玩']
# 实例化TfidfVectorizer对象
tfidf = TfidfVectorizer()
# 将文本列表转换为特征矩阵
features = tfidf.fit_transform(texts)
# 获取特征单词列表
feature_names = tfidf.get_feature_names_out()
# 将特征矩阵转换为 pandas DataFrame
matrix = features.toarray()
feature_names_df = pd.DataFrame(matrix, columns=feature_names)
# 打印 DataFrame
print(feature_names_df)
运行结果:
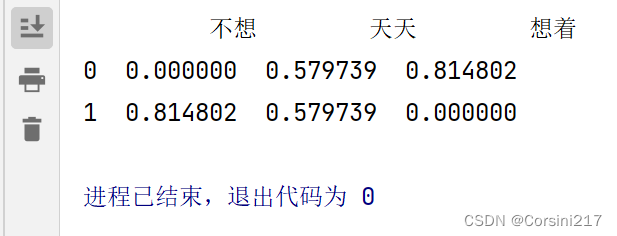
这里解释一下为什么没有“玩”,前面说了TF-IDF 针对的是“词”,所以单个的字不会计入计算中。
到了这里想必大家对文本转矩阵有了一定的了解。
对以上做个小结:
做到这一步我们就已经把每条评论中的特征词占整条评论的权重通过矩阵表现出来了,下面我们将该矩阵放到LDA模型中进行训练,然后得到每条评论中每个词的频次分配每个主题的概率权重,以进一步了解不同主题对于每条评论的重要程度。
将矩阵放入LDA模型进行训练
前面已经说了LDA模型是用来做什么的,这里我再简单地说一下它在本次项目中的作用:前面我们已经得到了每条评论中特征词的权重(矩阵),然后我们通过LDA模型将所有的特征词进行统计并把它们进行分类归为某一主题,然后输出每个主题对应的特征词概率分布信息,也就是每个主题分别由哪些单词组成相比其他主题更可能出现。
# 选定的主题数,也就是把所有特征词划分为5个主题
n_topics = 5
#定义LDA对象
lda = LatentDirichletAllocation(
n_components=n_topics, max_iter=50,
learning_method='online',
learning_offset=50.,
random_state=0)
# 核心,将TF-IDF 矩阵放入到LDA模型中
lda.fit(tf_idf)
代码解释:
在定义LDA对象代码中,我们使用了LatentDirichletAllocation类,并指定了模型参数:n_topics(主题数)、max_iter(最大迭代次数)、learning_method(求解模型时的采样方法)和 learning_offset(控制批量更新的速度和幅度)。我们还设置了一个随机数种子(random_state)以确保每次执行主题建模时输出结果一致。
那么,将矩阵放入到LDA模型中我们将得到什么呢?这里我们想要得到的东西有两个:
- 每一个主题的前n个主题词是什么。
- 每一个评论属于每一个主题的概率是多大。
为了更好描述这两个产出,我将定义两个函数来对其进行处理,使其变成 pandas 的 DataFrame,以便后续处理。
#第1部分
# 要输出的每个主题的前 n_top_words 个主题词数
n_top_words = 50
def top_words_data_frame(model: LatentDirichletAllocation,
tf_idf_vectorizer: TfidfVectorizer,
n_top_words: int) -> pd.DataFrame:
rows = []
feature_names = tf_idf_vectorizer.get_feature_names_out()
for topic in model.components_:
top_words = [feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]
rows.append(top_words)
columns = [f'topic {i + 1}' for i in range(n_top_words)]
df = pd.DataFrame(rows, columns=columns)
return df
#2
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:
matrix = model.transform(X)
columns = [f'P(topic {i + 1})' for i in range(len(model.components_))]
df = pd.DataFrame(matrix, columns=columns)
return df
代码解释:
第1部分:
这个函数接收以下参数:
model: 一个已经训练好的 LDA 模型对象,可以使用sklearn.decomposition.LatentDirichletAllocation训练得到;tf_idf_vectorizer: 一个已经训练好的文本向量化对象,可以使用sklearn.feature_extraction.text.TfidfVectorizer训练得到;n_top_words: 需要返回每个主题中前n_top_words个关键词。
该函数的主要实现步骤如下:
- 从
tf_idf_vectorizer中获取所有特征词汇列表feature_names。 - 遍历模型的每个主题,找到每个主题中权重最高的
n_top_words个特征词汇的下标,通过feature_names获取它们的原始词汇,并保存在一个列表top_words中。 - 将所有主题的前
n_top_words个单词保存在一个 Pandas 数据框中,并指定列名,返回该数据框。
需要注意的是,训练好的 LDA 模型和 TfidfVectorizer 向量化对象都需要作为参数传入,而且要确保它们是在同一个数据集上训练得到的,否则可能无法正确解释主题模型结果。
第2部分:
这个函数将一个包含文本数据的 numpy 数组 X 输入到一个已经训练好的 LDA 主题模型 model 中,然后返回一个数据框,其中每行是一个文本数据,每列是一个主题,其值表示该文本属于该主题的概率。
具体来说,这个函数接收以下参数:
model: 一个已经训练好的 LDA 模型对象,可以使用sklearn.decomposition.LatentDirichletAllocation训练得到;X: 一个包含文本数据的 numpy 数组,每行表示一个文本。
该函数的主要实现步骤如下:
- 使用
model.transform()函数将输入的文本数据X转换为一个主题-文本的矩阵matrix,其中每个元素表示该文本属于对应主题的概率。 - 生成一个包含每个主题名称的列名列表
columns,例如['P(topic 1)', 'P(topic 2)', ...]。 - 将
matrix转换成一个 pandas 数据框df,其中每列使用columns中的列名,每行表示对应的文本数据。 - 返回数据框
df。
需要注意的是,输入参数 X 需要与训练 LDA 模型时使用的数据集具有完全相同的特征数量和顺序,否则预测结果可能无法正确解释。此外,输出的每列值都是归一化后得到的概率值,所以可以按列求和,得到每行概率之和为 1 的校验结果。
将结果进行保存
# 要输出的每个主题的前 n_top_words 个主题词数
n_top_words = 50
# 计算 n_top_words 个主题词
top_words_df = top_words_data_frame(lda, tf_idf_vectorizer, n_top_words)
# 保存 n_top_words 个主题词到 csv 文件中
top_words_df.to_csv(top_words_csv_path, encoding='utf-8', index=None)
# 转 tf_idf 为数组,以便后面使用它来对文本主题概率分布进行计算
X = tf_idf.toarray()
# 计算完毕主题概率分布情况
predict_df = predict_to_data_frame(lda, X)
# 保存文本主题概率分布到 csv 文件中
predict_df.to_csv(predict_topic_csv_path, encoding='utf-8', index=None)
运行完以上全部代码我们会在py文件所在的文件夹得到两份数据,下面我们看看数据是怎样的:
1.一共有6行数据,第一行是表头,剩下的5行是5个主题对应的权重最高的前50个特征词。

2.每条评论在各个主题出现的概率,也就是对于每个文本,模型认为它可能含有的不同主题所占的比例。
作用:这个输出可以用来推断每个文本的主题类别,例如,如果某个文本中的主题概率分布中,主题 3 的比例较高,可以推断该文本与主题 3 相关较大。针对这些主题,可以进一步挖掘其背后的语义特征,以及与其他主题的共性和差异。
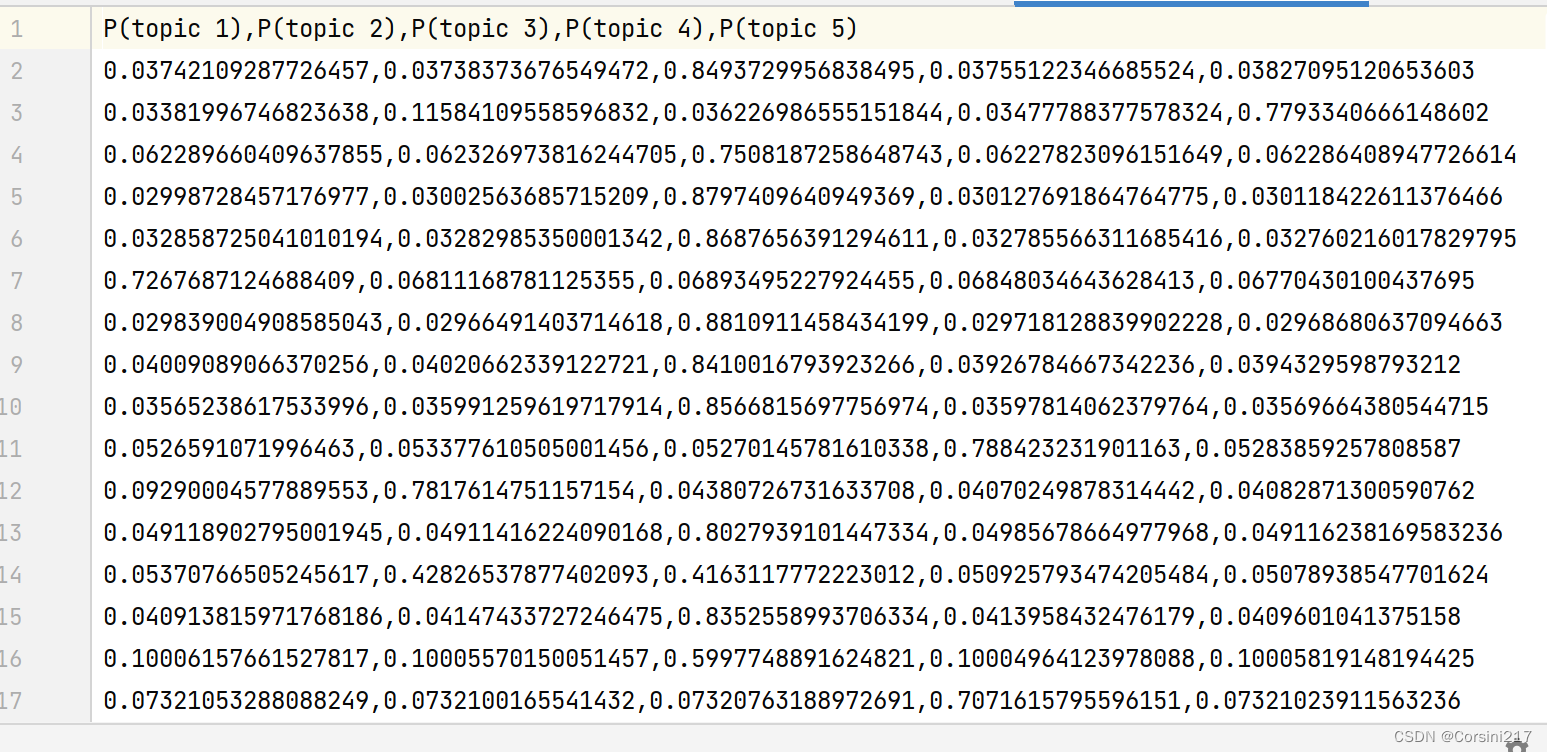
对评论进行情感分析及打分
因为这篇文章的重心是在于LDA主题模型,情感分析就简单点啦!
这里我通过两个库进行评论的情感分析及打分。

简单介绍一下这两个库:
- textblob:是一个 Python 自然语言处理库,它提供了一个简单的 API,使得对文本数据进行情感分析、翻译、词性标注等处理操作变得非常容易。
TextBlob库基于 NLTK(自然语言工具包)开发,它可以快速地进行情感分析,并且支持pipelines、面向对象的 API和词性标注等主要功能。 - snownlp:是一个基于 Python 的中文文本处理库,它包括了一些文本情感分析、文本分类、关键词提取、信息抽取等自然语言处理的功能。
代码如下:
#textblob
# 创建空列,用于存储情感得分
df1['sentiment'] = ''
for i, row in df1.iterrows():
text = row['cut'] # 获取文本数据
blob = TextBlob(text)
# 计算情感得分,并将其添加到 DataFrame 中
if blob.sentiment.polarity > 0:
df1.at[i, 'sentiment'] = 'positive' #积极
elif blob.sentiment.polarity < 0:
df1.at[i, 'sentiment'] = 'negative' #消极
else:
df1.at[i, 'sentiment'] = 'neutral' #中性
print(df1.head())
#Snownlp
df1['emotion_score'] = ''
for i, row in df1.iterrows():
text = row['cut'] # 获取文本数据
s = SnowNLP(text)
score = s.sentiments
# 将情感得分添加到 DataFrame 中
df1.at[i, 'emotion_score'] = score
# 查看 DataFrame
print(df1.head())
df1.to_excel('E:/网易云数据评论/最后完成的结果.xlsx', index=True)
上面的代码中,我都是将分好词后的数据作为输入的也就是“cut”这列。
让我们看看保存好的文件:
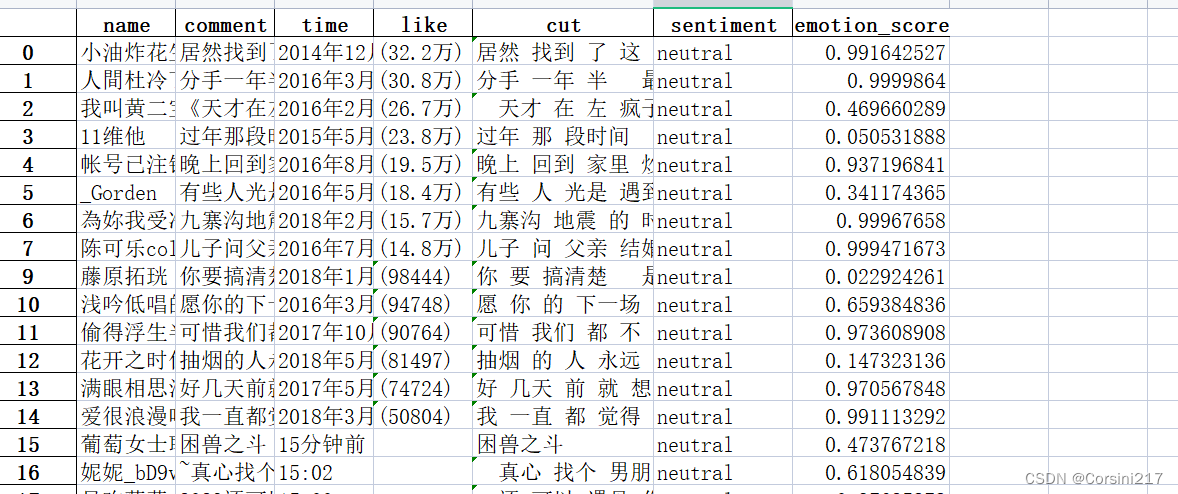
通过上面的图我们知道,textblob进行的情感分析和snownlp所打的分是不太匹配的,前面16行数据textblob对其都是“nautral”也就是中性情感,但snownlp的评分有的高达0.9,有点却低到0.02。
写在最后
其实LDA模型应用在文章,论文等等方面所得到的结果比较有用,我之所以用在了网易云评论这里是因为在项目的一开始我们小组就已经决定了的。但方法都是一样的,最后,如果你仔细阅读,那多多少少是会有收获的。最后祝大家天天进步!!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









