







 随着集成电路技术的发展,片上系统SoC设计转向以通信为中心,片上网络(NoC)作为新型互连架构,解决了传统总线结构在扩展性、带宽、功耗等方面的问题。NoC通过采用数据路由和分组交换技术,实现了片上多核处理器间的高效通信。
随着集成电路技术的发展,片上系统SoC设计转向以通信为中心,片上网络(NoC)作为新型互连架构,解决了传统总线结构在扩展性、带宽、功耗等方面的问题。NoC通过采用数据路由和分组交换技术,实现了片上多核处理器间的高效通信。
转载地址:http://www.eefocus.com/srnoc/blog/15-09/319333_0b2d8.html
在过去的几十年里,集成电路制造工艺技术、封装与测试技术、设计方法学和EDA 工具等微电子相关技术始终保持着快速的发展。根据国际半导体技术发展路线图(International Technology Roadmap for Semiconductors, ITRS)预测,到2024年IC 制造技术将达到8.9 nm,每平方毫米集成的晶体管数目将达到90 亿个。但是,全局互连线的性能提升程度明显低于晶体管性能提升程度。受到亚阈值漏电流功耗、动态功耗、器件可靠性以及全局互连线等影响,通过提升单个处理器核的性能来提升系统整体性能已变得非常难以实现,同时芯片设计的难度和复杂度也在进一步增加。片上系统(System on Chip, SoC)具有集成度高、功耗低、成本低、体积小等优点,已经成为超大规模集成电路系统设计的主流方向。随着片上系统SoC 的应用需求越来越丰富、越来越复杂,片上多核MPSoC (MultiprocessorSystem on Chip, MPSoC) 已经成为发展的必然趋势,同时MPSoC 上集成的IP 核数量也将会按照摩尔定律继续发展。目前,MPSoC 已经逐渐应用于网络通信、多媒体等嵌入式电子设备中。半导体工艺技术的快速发展为集成电路设计提供了很大的发展空间,同时也带来了一系列新的问题和挑战,如芯片的性能、功耗、可靠性、可扩展性等等。
随着系统性能需求越来越高,处理器核之间的互连架构必须能够提供具有较低延迟和高吞吐率的服务,并且具有良好的可扩展性。传统的基于总线的集中式互连架构已经难以满足现今系统的性能需求,而基于报文交换的片上网络(Network on Chip, NoC)逐渐成为片上多核间通讯的首选互连架构。在NoC 中,路由节点之间通过局部互连线相连接,每一个路由节点通过网络接口NI 与一个本地IP 核相连接,源路由节点和目的路由节点之间的数据通讯需要经过多个跳步来实现。因此,NoC 技术的出现使得片上系统SoC 的设计也将从以计算为中心逐渐过渡到以通讯为中心。
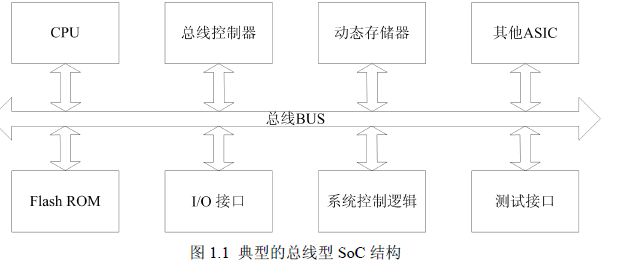
传统的SoC 系统采用总线互连结构,如图1.1 所示。虽然人们已经提出了很多改进的总线结构,例如将共享总线改进为桥接多总线结构、层次化总线结构等更复杂的结构。但是当进入MPSoC 时代,单芯片上集成的处理器核数越来越多时,总线结构在通讯性能、功耗、全局时钟同步、信号完整性以及信号可靠性等方面面临着巨大的挑战,这些复杂的改进型总线结构仍无法解决片上多核间通信所面临的问题。因此,MPSoC 上多核间的通讯问题已经成为制约系统性能提升的主要瓶颈。
NoC 的概念是由Agarwal(1999 年)、Guerrier 和Greiner(2000 年)、Dally 和Towles(2001 年)、Benini 和Micheli(2002 年)、Jantsch 和Tenhunen(2003 年)等人逐步提出的。目前,NoC 的研究仍处于初级阶段,但随着半导体工艺技术的进步和芯片集成度的提高,NoC 的设计已成为现实,并展现出非常广阔的前景[2]。目前,对于NoC 还没有一个统一的定义,大多数NoC 研究者认为NoC 是SoC 系统的通讯子集,并且应该引入互联网络技术来解决片上多核的通讯问题。
随着单芯片上集成的处理器核数越来越多,片上互连架构经历了从专用互连线,Bus,Crossbar到NoC。NoC 借鉴了分布式计算系统的通讯方式,采用数据路由和分组交换技术替代传统的总线结构,从体系结构上解决了SoC 总线结构由于地址空间有限导致的可扩展性差,分时通讯引起的通讯效率低下,以及全局时钟同步引起的功耗和面积等问题。与传统的总线互连技术相比,片上网络具有如下优点:
第一,网络带宽。总线结构互连多个IP 核,共享一条数据总线,其缺点是同一时间只能有一对IP 进行通信。随着系统规模的逐渐增大,总线结构的通信效率必然成为限制系统性能提升的瓶颈。片上网络具有非常丰富的信道资源,为系统提供了一个网络化的通信平台。网络中的多个节点可以同时利用网络中的不同物理链路进行信息交换,支持多个IP 核并发地进行数据通信。随着网络规模的增大,网络上的信道资源也相应增多。因此,NoC 技术相对于Bus 互连技术具有较高的带宽,以及更高的通信效率。当并发进行数据通信时网络会产生竞争,即会存在请求同一条物理链路的节点对。NoC 的路由节点通过分时复用物理链路来解决竞争,与Bus 结构相比,NoC 能够降低竞争发生的概率。
第二,可扩展性和设计成本。总线结构需要针对不同的系统需求单独进行设计,当系统功能扩展时,需要对现有的设计方案重新设计,从而严重影响设计的周期和资本投入。NoC 中每个路由节点和本地IP 核通过网络接口(NetworkInterface, NI)相连,当系统需要升级扩展新功能时,只需要将新增加的处理器核通过网络接口NI 接入到网络中的路由节点即可,无需重新设计网络。因此,片上网络具有良好的可扩展性。片上网络作为一个独立的片上互连结构,能够满足不同系统的应用需求,当网络中节点数量增加时,仅需要按照相应的拓扑结构规则继续增大网络的规模即可,缩短了产品的设计周期,节约了设计成本。
第三,功耗。随着SoC 规模的不断增大,总线上每次信息交互都需要驱动全局互连线,因此总线结构所消耗的功耗将显著增加,并且随着集成电路工艺的不断发展,想要保证全局时钟同步也将变得难以实现。而在NoC 中,信息交互消耗的功耗与进行通讯的路由节点之间的距离密切相关,距离较近的两个节点进行通讯时消耗的功耗就比较低。
第四,信号完整性和信号延迟。随着集成电路特征尺寸的不断减小,电路规模的不断增大,互连线的宽度和间距也在不断地减小,线间耦合电容相应增大,长的全局并行总线会引起较大的串扰噪声,从而影响信号的完整性以及信号传输的正确性。同时,互连线上的延迟将成为影响信号延迟的主要因素,总线结构全局互连线上的延迟将大于一个时钟周期,从而使得时钟的偏移很难管理。
第五,全局同步。总线结构采用全局同步时钟,随着芯片集成度的提高,芯片的工作频率也在不断提高,在芯片内会形成很庞大的时钟树,因此很难实现片上各个模块的全局同步时钟。采用时钟树(Clock Tree)优化的方法可以改善由时钟翻转引起的时钟偏差和时钟抖动,但同步时钟网络所产生的动态功耗甚至可达总功耗的40%以上。为了提高系统的时钟频率,只能对全局互连线采用分布式流水线结构,或者采用全局异步局部同步(Global Asynchronous Local Synchronous,GALS)的时钟策略。

















 3281
3281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









