










题目:http://codeforces.com/problemset/problem/696/B
题意:
一个树,dfs遍历子树的顺序是随机的。所对应的子树的dfs序也会不同。输出每个节点的dfs序的期望
分析:
分析一颗子树:
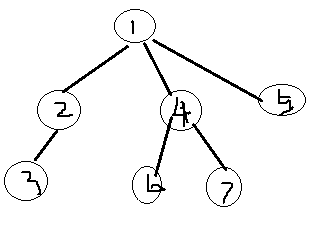
当前已知节点1的期望为1.0 ->anw[1]=1.0
需要通过节点1递推出节点2、4、5的期望值
1的儿子分别是2、4、5,那么dfs序所有可能的排列是6种:
1:1-2-4-5 (2、4、5节点的儿子没有写出)
2:1-2-5-4
3:1-4-2-5
4:1-4-5-2
5:1-5-2-4
6:1-5-4-2
计算节点2的期望值得时候,当节点2的前面已经排列了num个点,那么节点2的dfs序就要增加num
所以anw[2]的计算分为两部分,第一部分是:anw[2]=anw[1]+1 (节点1通过1步直接到达儿子2、4、5)
第二部分是:当节点1到达节点2的时候贡献是0,种类分别对应(1、2)
当先到达节点4后到节点2的时候贡献(size(4)+size(4)+szie(5)),种类分别对应(3、4)
当先到达节点5后到节点2的时候贡献(size(5)+size(5)+size(4)),种类分别对应(5、6)
而所有的排列对于的概率都是1/6,所以第二部分的贡献就是(0+size(4)*3+size(5)*3)/6 = (size(4)+size(5))/2
仔细推理几颗子树之后:发现anw[v]=anw[u]+1.0+(sz[u]-sz[v]-1)/2.0。
anw[u]+1.0对应第一部分 (sz[u]-sz[v]-1)/2.0 表示的是当前能排在节点v前面的u的儿子的总数 * 0.5
对比1-6的6种排列,任意儿子a、b ,满足a在b前面的概率是0.5
以上分析copy自:http://blog.csdn.net/libin66/article/details/51918509
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5 + 9;
vector<int>son[N];
double dp[N];
int sz[N];
void dfs (int u) {
sz[u] = 1;
for (int i = 0; i < son[u].size(); i++) {
int v = son[u][i];
dfs (v);
sz[u] += sz[v];
}
}
void dfs1 (int u, int fa) {
if (u != 1) dp[u] = dp[fa] + (sz[fa] - sz[u] - 1) * 0.5 + 1;
for (int i = 0; i < son[u].size(); i++)
dfs1 (son[u][i], u);
}
int main() {
int n, x;
scanf ("%d", &n);
for (int i = 2; i <= n; i++) {
scanf ("%d", &x);
son[x].push_back (i);
}
dp[1] = 1;
dfs (1);
dfs1 (1, 0);
for (int i = 1; i <= n; i++) printf ("%.10lf ", dp[i]);
return 0;
}
/*
Input
7
1 2 1 1 4 4
Output
1.0 4.0 5.0 3.5 4.5 5.0 5.0
*/
因为(1 ≤ pi < i)所以还可以这样写:
#include <cstdio>
#define rep(i,a,n) for (int i=a;i<n;i++)
#define per(i,a,n) for (int i=n-1;i>=a;i--)
const int N=101000;
int n,p[N],sz[N];
double dp[N];
int main() {
scanf("%d",&n);
rep(i,2,n+1) scanf("%d",p+i);
rep(i,1,n+1) sz[i]=1;
per(i,2,n+1) sz[p[i]]+=sz[i];
dp[1]=1;
rep(i,2,n+1) dp[i]=dp[p[i]]+0.5*(1+sz[p[i]]-sz[i]);
rep(i,1,n+1) printf("%.10f ",dp[i]);
return 0;
}














 3054
3054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









