







整理自CSE 444 Database Internals, Spring 2019 的课程Lectures,课程地址:https://courses.cs.washington.edu/courses/cse444/19sp/
Lecture3 DBMS Architecture
What we already know…
Database = collection of related files
DBMS = program that manages the database
Data models: relational, semi-structured (XML), graph (RDF), key-value pairs
Relational model: defines only the logical model, and does not define a physical storage of the data
Relational Query Language:
- Set-at-a-time: instead of tuple-at-a-time
- Declarative: user says what they want and not how to get it
- Query optimizer: from what to how
How to Implement a Relational DBMS?

DBMS Architecture

Query Processor
Step 1: Parser
- Parses query into an internal format
- Performs various checks using catalog
Step 2: Query rewrite
- View rewriting, flattening, etc.
Rewritten Version of Our Query

Query Processor
Step 3: Optimizer
- Find an efficient query plan for executing the query
- A query plan

Step 4: Executor
- Actually executes the physical plan



Iterator Interface
Each operator implements OpIterator.java
open()
- Initializes operator state
- Sets parameters such as selection predicate
next()
- Operator invokes next() recursively on its inputs
- Performs processing and produces an output tuple
close()
- clean-up state
Operators also have reference to their child operator in the query plan


Storage Manager
Access Methods

Buffer Manager

Brings pages in from memory and caches them
Eviction policies
- Random page (ok for SimpleDB)
- Least-recently used
- The “clock” algorithm (see book)
Keeps track of which pages are dirty
- A dirty page has changes not reflected on disk
- Implementation: Each page includes a dirty bit
Access Methods
A DBMS stores data on disk by breaking it into pages
- A page is the size of a disk block.
- A page is the unit of disk IO
Buffer manager caches these pages in memory
Access methods do the following:
- They organize pages into collections called DB files
- They organize data inside pages
- They provide an API for operators to access data in these files
Query Execution In SimpleDB

Query Execution In SimpleDB

HeapFile In SimpleDB
Data is stored on disk in an OS file. HeapFile class knows how to “decode” its content
Control flow:
- SeqScan calls methods such as "iterate" on the HeapFile Access Method
- During the iteration, the HeapFile object needs to call the BufferManager.getPage() method to ensure that necessary pages get loaded into memory.
- The BufferManager will then call HeapFile .readPage()/writePage() page to actually read/write the page.
Lecture4 Data storage and (more) buffer management
DBMS Architecture

Today: Starting at the Bottom
Design Exercise
One design choice: One OS file for each relation
- This does not always have to be the case! (e.g., SQLite uses one file for whole database)
- DBMSs can also use disk drives directly
An OS file provides an API of the form
- Seek to some position (or “skip” over B bytes)
- Read/Write B bytes

First Principle: Work with Pages
Reading/writing to/from disk
- Seeking takes a long time!
- Reading sequentially is fast
Solution: Read/write pages of data
- Traditionally, a page corresponds to a disk block
To simplify buffer manager, want to cache a collection of same-sized objects
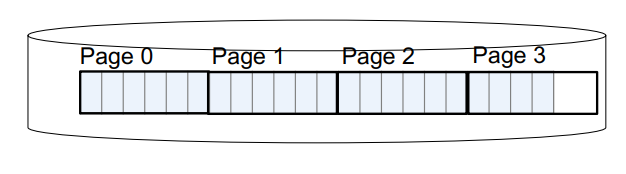
Continuing our Design
Key questions:
- How do we organize pages into a file?
- How do we organize data within a page?
First, how could we store some tuples on a page? Let’s first assume all tuples are of the same size:

Tweets(tid int, user char(10), time int, content char(140))
Page Formats
Issues to consider
- 1 page = 1 disk block = fixed size (e.g. 8KB)
- Records: – Fixed length and – Variable length
Record id = RID
- Typically RID = (PageID, SlotNumber)
Why do we need RID’s in a relational DBMS ? See future discussion on indexes and transactions
Think how you would store tuples on a page
- Fixed length tuples
- Variable length tuples
Page Format Approach 1
Fixed-length records: packed representation
Divide page into slots. Each slot can hold one tuple
Record ID (RID) for each tuple is (PageID,SlotNb)


Page Format Approach 2

Record Formats
Fixed-length records => Each field has a fixed length(i.e., it has the same length in all the records)

Variable length records

Continuing our Design
Now, how should we group pages into files?
Heap File Implementation 1

Heap File Implementation 2

Heap File Implementation 3

Modifications: Insertion
File is unsorted (= heap file)
- add it wherever there is space (easy )
- add more pages if out of space
File is sorted
- Is there space on the right page ?Yes: we are lucky, store it there
- Is there space in a neighboring page ?Look 1-2 pages to the left/right, shift records
- If anything else fails, create overflow page
Overflow Pages

Modifications: Deletions
Free space by shifting records within page
- Be careful with slots
- RIDs for remaining tuples must NOT change
May be able to eliminate an overflow page
Modifications: Updates
- If new record is shorter than previous, easy
- If it is longer, need to shift records :May have to create overflow pages
Continuing our Design
We know how to store tuples on disk in a heap file
How do these files interact with rest of engine?
- Let’s look back at lecture 3
How Components Fit Together

Heap File Access Method API
Create or destroy a file
Insert a record
Delete a record with a given rid (rid)
- rid: unique tuple identifier (more later)
Get a record with a given rid
- Not necessary for sequential scan operator
- But used with indexes (more next lecture)
Scan all records in the file
Query Execution In SimpleDB

Pushing Updates to Disk

Alternate Storage Manager Design: Column Store

Conclusion
- Row-store storage managers are most commonly used today for OLTP systems
- They offer high-performance for transactions
- But column-stores win for analytical workloads
- They are widely used in OLAP















 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









