









本文档主要针对Redis的代理程序TwemProxy的使用进行调研和总结,共分为以下几个部分:
1、TwemProxy简介;该部分主要介绍TwemProxy是什么,能干哪些事情,有什么主要特点;
2、TwemProxy的集群部署;该部分主要介绍TwemProxy的集群部署方式;
3、TwemProxy的功能及性能分析;该部分主要介绍TwemProxy集群架构时的功能和性能情况。
4、TwemProxy的安装与使用说明,该部分主要介绍TwemProxy的下载、编译,安装运行方法,以及其配置文件中各参数的详细介绍。
5、TwemProxy与朋友圈设计,该部分主要说明使用TwemProxy来参与搭建朋友圈功能时存在的问题以及可能的解决办法。
一、TwemProxy简介
Twemproxy也叫nutcraker,是twtter开源的一个redis和memcache代理服务器程序。redis作为一个高效的缓存服务器,非常具有应用价值。但在用户数据量增大时,需要运行多个redis实例,此时将迫切需要一种工具统一管理多个redis实例,避免在每个客户端管理所有连接带来的不方便和不易维护,Twemproxy即为此目标而生。
Redis本身也有一个集群功能成为Redis Cluster,但它试图在数据存储系统上支持分片,这种方法增加了redis的复杂性,使用起来也不方便;TwemProxy采用中间层代理的方式,在不改动服务器端程序的情况下,使得集群管理更简单、轻量和有效。
Twemproxy 通过引入一个代理层,将其后端的多台 Redis实例进行统一管理与分配,使应用程序只需要在 Twemproxy 上进行操作,而不用关心后面具体有多少个真实的 Redis实例。Twemproxy有以下几个特点:
l 单线程工作,用C语言开发;
l 直接支持大部分的redis指令,redis客户端可以像访问正常redis实例一样访问TwemProxy。
l 支持失败节点自动删除;可以设置重新连接该节点的时间,还可以设置连接多少次之后删除该节点
l 支持设置HashTag;通过HashTag可以自己设定将同一类型的key映射到同一个实例上去。
l 减少与redis的直接连接数,保持与redis的长连接,可设置代理与后台每个redis连接的数目
l 自带一致性hash算法,能够将数据自动分片到后端多个redis实例上;支持多种hash算法,可以设置后端实例的权重,目前redis支持的hash算法有:one_at_a_time、md5、crc16、crc32、fnv1_64、fnv1a_64、fnv1_32、fnv1a_32、hsieh、murmur、jenkins。
l 支持redis pipelining request,将多个连接请求,组成reids pipelining统一向redis请求。
l 支持状态监控;可设置状态监控ip和端口,访问ip和端口可以得到一个json格式的状态信息串;可设置监控信息刷新间隔时间。
l 高效;对连接的管理采用epoll机制,内部数据传输采用“Zero Copy”技术,以提高运行效率,TwemProxy是目前效率最高的代理程序,与直接访问redis项目其效率损失只有10%左右。
TwemProxy之所以受到使用者的欢迎,很大程度上得益于其轻量级、快捷以及便于使用的特点,用户可以像访问redis客户端一样访问TwemProxy。但是在使用时需要注意以下两点:
l 不支持针对多个值的操作,比如取sets的子交并补等。TwemProxy所支持的redis指令在其文件:twemproxy/blob/master/notes/redis.md
中有详细说明。
l 不支持Redis的事务操作。
二、TwemProxy的集群部署
本节内容主要根据文档[4]整理而成。
在Redis的应用过程中,随着用户数据的增加,Redis的容量和并发能力都会受到很大调整,TwemProxy的出现不仅可扩充redis的容量,而且可以扩充其并发支撑能力。
1、扩充Redis容量
在使用TwemProxy构建redis集群时,可以通过增加redis实例数来扩大redis的容量。在redis的实际部署过程中,根据实际需要的redis的内存量,来规划twemproxy群集中redis的实例数量,然后,通过twemproxy提供该群集的统一的访问入口,这样即有效的扩充了redis server的内存总量,又避免了单个redis server内存过大导致的问题,如下图2.1的方式即可通过TwemProxy来扩充redis的容量。
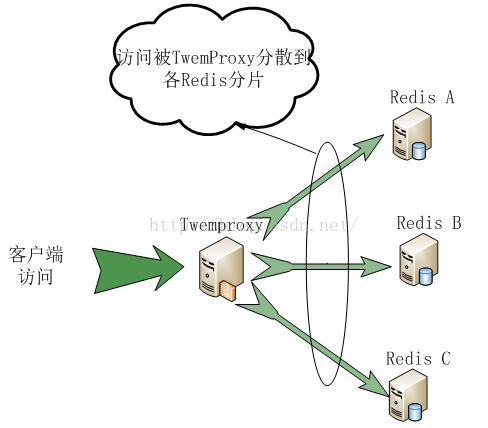
图2.1、使用TwemProxy扩充Redis的内存容量
2、扩充并发能力
由于TwemProxy是单进程的代理程序,在并发量大时,其并发支撑能力也会受到很大挑战,在部署TwemProxy+Redis集群架构时,可以通过增加TwemProxy的数量来增加系统的并发访问能力,同时还可以避免TwemProxy的单点失效的问题,在这种部署情况下,客户端可以通过Jedis直接连接多个TwemProxy。如下图2.2所示:
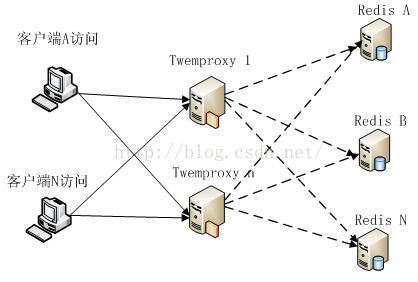
图2.2、使用TwemProxy扩充Redis的并发能力
在部署TwemProxy + Redis集群时可以参考TwemProxy的官方建议,见文档[5],另外文档[4]中对部署TwemProxy时的一些参数配置也有建议。
三、TwemProxy的功能及性能测试
由于时间有限,并未对TwemProxy的性能进测试,但是文档《Redis存储分片之代理服务Twemproxy测试.pdf》(见附件[7])中对TwemProxy的性能测试有较详细的记载,可作为参考。该文档对TwemProxy + Redis组合的集群的功能和性能方面都有描述,本节也将主要介绍这种集群方式的功能与性能测试情况。
该文档所描述的测试过程中,使用Redis BenchMark模拟客户端进行测试,测试的架构如下图3.1所示:
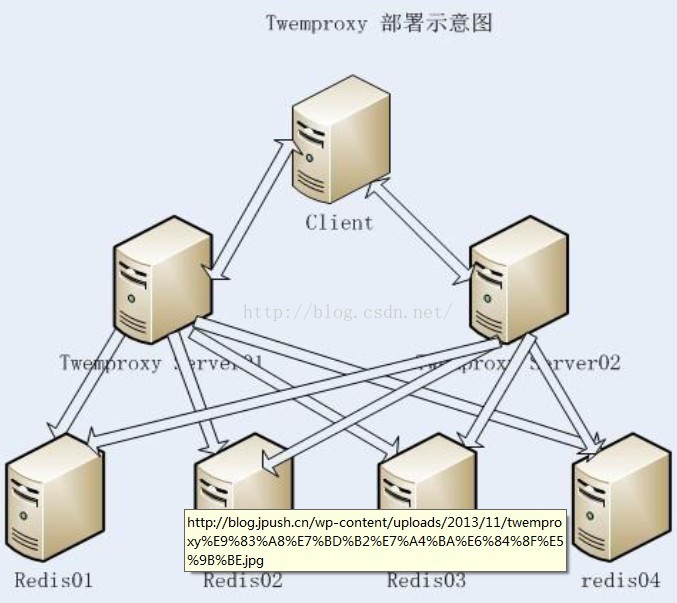
3.1、Redis并发测试架构图
1、功能测试方面
通过该文档中的测试数据可以看到以下几点:
1)前端使用Twemproxy做代理,后端的Redis 数据能基本上根key来进行比较均衡的分布。
2)后端一台Redis挂掉后,Twemproxy能够自动摘除。恢复后,Twemproxy 能够自动识别、 恢复并重新加入到Redis组中重新使用。
3) Redis挂掉后,后端数据是否丢失依据Redis本身的策略配置,与TwemProxy基本无关;
4) 如果要新增一台Redis,TwemProxy需要重启才能生效;并且数据不会自动重新Reblance,需要人工单独写脚本来实现。
5) 如同时部署多个TwemProxy,配置文件一致(测试配置为distribution:ketama,modula),则可以从任意一个读取,都可以正确读取key对应的值。
6)如果新增Redis实例节点,则增加后数据分布计算域原来的redis分布无关,现有数据如果需要分布均匀的话,需要人工单独处理。
7)如果TwemProxy的后端节点数量发生变化,TwemProxy相同算法的前提下,原来的数据必须重新处理分布,否则会存在找不到key值的情况。
针对上述结果中后端Redis实例增加引起TwemProxy数据无法重新分布的问题,可以采用预分片技术来解决,Redis的预分片技术可以参考文档[8]。针对Redis实例节点可能失效的问题,采用Redis的Master-Slave的主从备份模式可以缓解。
2、性能测试方面
在性能方面:
1)单个TwemProxy;无论一个TwemProxy后面挂多少个Redis实例,其性能最多也只能达到单台Redis的性能。
2)多台TwemProxy;测试时配置一样,客户端分别连接多台TwemProxy可在一定条件下提高性能,根据Server的数量,提高比例在110%~150%之间;
四、TwemProxy的安装与使用说明
1、下载地址:
http://code.google.com/p/twemproxy/downloads/list
2、编译和安装:
TwemProxy的编译和安装非常简单,只需以下三条命令即可完成:
./configure
make
make install
详细安装和配置方法可参考网站[1]中所示。运行命令如下所示:
./src/nutcracker conf/nutcracker.yml
在该命令中使用当前目录下conf目录中的配置文件nutcracker.yml,另外,该命令运行的nutcracker位于当前目录下的src目录中。
3、配置文件说明
TwemProxy的配置文件为:conf/nutcracker.yml,所有TwemProxy运行中所需参数都在此文件中进行配置。详细的配置信息说明如下:
(1)listen
twemproxy监听的端口。可以以ip:port或name:port的形式来书写。
(2)hash
可以选择的key值的hash算法: one_at_a_time、md5、crc16、crc32 、crc32a 、fnv1_64、fnv1a_64、fnv1_32、fnv1a_32、hsieh、murmur、jenkins ,如果没选择,默认是fnv1a_64。
(3)hash_tag
hash_tag允许根据key的一个部分来计算key的hash值。hash_tag由两个字符组成,一个是hash_tag的开始,另外一个是hash_tag的结束,在hash_tag的开始和结束之间,是将用于计算key的hash值的部分,计算的结果会用于选择服务器。 例如:如果hash_tag被定义为”{}”,那么key值为"user:{user1}:ids"和"user:{user1}:tweets"的hash值都是基于”user1”,最终会被映射到相同的服务器。而"user:user1:ids"将会使用整个key来计算hash,可能会被映射到不同的服务器。
(4) distribution
存在ketama、modula和random3种可选的配置。其含义如下:
ketama一致性hash算法,会根据服务器构造出一个hash ring,并为ring上的节点分配hash范围。ketama的优势在于单个节点添加、删除之后,会最大程度上保持整个群集中缓存的key值可以被重用。
modula非常简单,就是根据key值的hash值取模,根据取模的结果选择对应的服务器。
random是无论key值的hash是什么,都随机的选择一个服务器作为key值操作的目标。
(5)timeout
单位是毫秒,是连接到server的超时值。默认是永久等待。
(6)backlog
监听TCP 的backlog(连接等待队列)的长度,默认是512。
(7)preconnect
是一个boolean值,指示twemproxy是否应该预连接pool中的server。默认是false。
(8)redis
是一个boolean值,用来识别到服务器的通讯协议是redis还是memcached。默认是false。
(9)server_connections
每个server可以被打开的连接数。默认,每个服务器开一个连接。
(10)auto_eject_hosts
是一个boolean值,用于控制twemproxy是否应该根据server的连接状态重建群集。这个连接状态是由server_failure_limit阀值来控制。 默认是false。
(11)server_retry_timeout
单位是毫秒,控制服务器连接的时间间隔,在auto_eject_host被设置为true的时候产生作用。默认是30000 毫秒。
(12)server_failure_limit
控制连接服务器的次数,在auto_eject_host被设置为true的时候产生作用。默认是2。
(13)servers
一个pool中的服务器的地址、端口和权重的列表,包括一个可选的服务器的名字,如果提供服务器的名字,将会使用它决定server的次序,从而提供对应的一致性hash的hash ring。否则,将使用server被定义的次序。
示例:
例如:有个配置文件为:
alpha:
listen: 192.168.4.221:22121
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 1
servers:
- 192.168.4.223:6379:1 server223
- 192.168.4.222:6379:1 server222
则表示当前的TwemProxy在192.168.4.221机子上使用22121端口监听客户端的连接,该TwemProxy共管理了2个redis实例:server223和server222,客户端通过直接访问TwemProxy的22121端口,而无法接触到具体的redis实例:server222和server223。
附件:
[1] TwemProxy下载地址:https://github.com/twitter/twemproxy
[2] Redis作者antirez 对于TwemProxy的博客介绍:http://antirez.com/news/44
[3] Redis集群及周边:
http://wenku.baidu.com/link?url=tivPIPAejWWXjmYMDG3vqDVoy7AqVmQKk0q82EZJN26P8gC6w4TO7t9Uz4oiRAQpjQUef9Wde2GKHcdNZT6MgiIAbi63VpBCaDuCMTQGK2O
[4] 基于TwemProxy的Redis集群方案:
[5] Twemproxy部署建议:
https://github.com/cloudaice/twemproxy/blob/master/notes/recommendation.md















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









