







说明:程序使用http://s.tool.chinaz.com/same此网站查询的结果,使用python简单的实现抓取结果
先随便查询一个结果,抓包分析,如图:
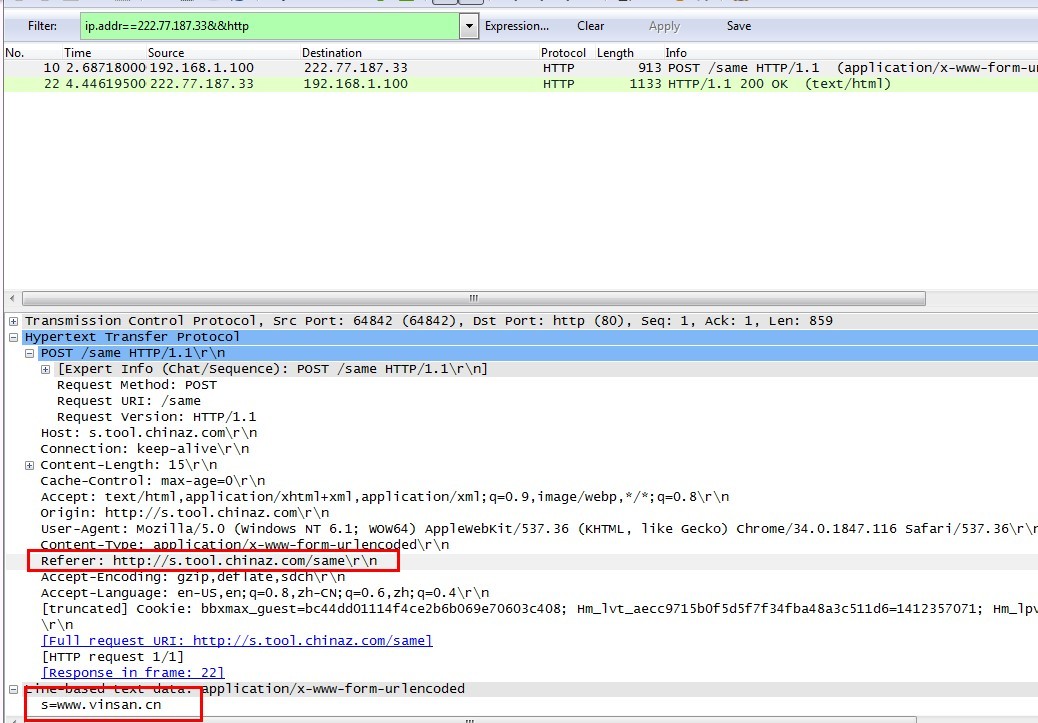
使用python模仿post表单,使用正则表达式匹配结果
代码如下:
# -*- coding: utf-8 -*-
import urllib
import urllib2
import re
import sys
#get url in the same ip
def get_url(url):
#set header info
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36',
'Referer': 'http://s.tool.chinaz.com/same'
}
postdata = urllib.urlencode({'s':url})
req = urllib2.Request('http://s.tool.chinaz.com/same',postdata,headers)
try:
result = urllib2.urlopen(req)
except:
print 'Failed to open url,you can try again...'
return
fweb = result.read()
#.</span> <a href='http://www.31hzp.com'
pattern = re.compile(r'</span> <a href=\'(.+?)\'')
match = pattern.findall(fweb)
filename = str(url).replace(':', '').replace('\\', '')
fp = open(filename+'.txt','w')
if match:
for m in match:
fp.write(m)
fp.write('\n')
print m
else:
print 'find nothing...'
fp.close()
#usage
def usage(name):
#www.31jmw.com
print '%s www.xxx.com'%name
sys.exit(1)
#entry point
if __name__ == '__main__':
if len(sys.argv) != 2:
usage(sys.argv[0])
print 'start...'
url = "".join(sys.argv[1]) #取出列表中的字符串
#print url
get_url(url)
print 'end...'测试结果如下:
F:\mycode\python\pytest\src>ipsamescan.py www.31jmw.com
start...
http://www.31hzp.com
http://100ec.cn
http://ec100.cn
http://toocle.cn
http://www.31jmw.com
http://www.31expo.com
http://www.toocle.cn
http://561288.com
http://www.toocle.com.cn
http://www.31metals.com
http://31expo.com
http://www.100ec.cn
end...















 5032
5032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









