







Redis
重新理解一下rehash。
- dictht ht[2]:在字典dict的内部有两张哈希表,作用是一对滚动数组。
rehash就是让哈希表的负载因子保持在一个合理的范围之内,避免哈希表保存的键值对数量太多或者太少。dt[0]是旧表,dt[1]是新表,当哈希表的大小需要动态改变的时候,旧表的元素就往新表中迁移,新表变成旧表,从而达到资源的复用和效率的提升。
Rehash源码:
int dictRehash(dict *d, int n) {
// 只可以在 rehash 进行中时执行
if (!dictIsRehashing(d)) return 0;
// 进行 N 步迁移
// T = O(N)
while(n--) {
dictEntry *de, *nextde;
/* Check if we already rehashed the whole table... */
// 如果 0 号哈希表为空,那么表示 rehash 执行完毕
// T = O(1)
if (d->ht[0].used == 0) {
// 释放 0 号哈希表
zfree(d->ht[0].table);
// 将原来的 1 号哈希表设置为新的 0 号哈希表
d->ht[0] = d->ht[1];
// 重置旧的 1 号哈希表
_dictReset(&d->ht[1]);
// 关闭 rehash 标识
d->rehashidx = -1;
// 返回 0 ,向调用者表示 rehash 已经完成
return 0;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
// 确保 rehashidx 没有越界
assert(d->ht[0].size > (unsigned)d->rehashidx);
// 略过数组中为空的索引,找到下一个非空索引
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
// 指向该索引的链表表头节点
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
// 将链表中的所有节点迁移到新哈希表
// T = O(1)
while(de) {
unsigned int h;
// 保存下个节点的指针
nextde = de->next;
/* Get the index in the new hash table */
// 计算新哈希表的哈希值,以及节点插入的索引位置
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 插入节点到新哈希表
de->next = d->ht[1].table[h];//节点始终插在表头
d->ht[1].table[h] = de;
// 更新计数器
d->ht[0].used--;
d->ht[1].used++;
// 继续处理下个节点
de = nextde;
}
// 将刚迁移完的哈希表索引的指针设为空
d->ht[0].table[d->rehashidx] = NULL;
// 更新 rehash 索引
d->rehashidx++;
}
return 1;
}跳跃表
跳跃表的存在是为了更快的访问节点。结构图如下所示。
跳跃表节点数据结构
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
- 层
level数组大小代表节点的层数。level数组可以包含很多元素,每个元素都包含一个指向其他节点的指针,程序可以通过这些层来访问其他节点的速度。一般来说,层的数量越多,访问其他节点的速度就越快。level的大小是根据幂次定律(越大的数出现的概率越小)随机生成。为什么要随机生成呢?
参考:https://blog.csdn.net/qpzkobe/article/details/80056807。理想的跳跃表如下图所示。但是如果要插入或者删除一个元素,结构就会变化,那么要维持这个理想的跳跃表结构会很麻烦,所以不如每次插入元素的时候都通过概率计算出这个节点的层数。这里是随机生成一个介于1和32之间的值作为level数组的大小,作为层的“高度”。
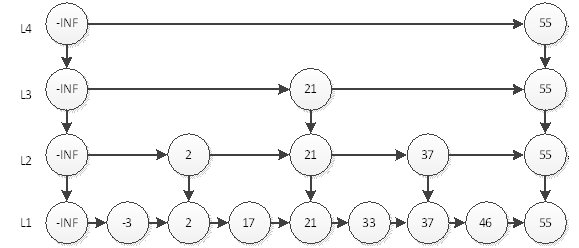
- 前进指针。指向表尾方向的下一个节点,可以跨越多个节点。
- 跨度。记录两个节点之间的距离。
- 后退指针。从表尾向表头方向访问节点,每次只能后退至前一个节点。
- 分值和成员。跳跃表中的节点按照分值从小到大排序,如果分值一样,按照成员对象的字典序从小到大排序,各个节点的成员对象必须是唯一的。
跳跃表数据结构
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;跳跃表API
创建跳跃表
/*
* 创建一个层数为 level 的跳跃表节点,
* 并将节点的成员对象设置为 obj ,分值设置为 score 。
*
* 返回值为新创建的跳跃表节点
*
* T = O(1)
*/
zskiplistNode *zslCreateNode(int level, double score, robj *obj) {
// 分配空间
zskiplistNode *zn = zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
// 设置属性
zn->score = score;
zn->obj = obj;
return zn;
}
/*
* 创建并返回一个新的跳跃表
*
* T = O(1)
*/
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
// 分配空间
zsl = zmalloc(sizeof(*zsl));
// 设置高度和起始层数
zsl->level = 1;
zsl->length = 0;
// 初始化表头节点
// T = O(1)
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
// 设置表尾
zsl->tail = NULL;
return zsl;
}释放跳跃表及节点
/*
* 释放给定的跳跃表节点
*
* T = O(1)
*/
void zslFreeNode(zskiplistNode *node) {
decrRefCount(node->obj);
zfree(node);
}
/*
* 释放给定跳跃表,以及表中的所有节点
*
* T = O(N)
*/
void zslFree(zskiplist *zsl) {
zskiplistNode *node = zsl->header->level[0].forward, *next;
// 释放表头
zfree(zsl->header);
// 释放表中所有节点
// T = O(N)
while(node) {
next = node->level[0].forward;
zslFreeNode(node);
node = next;
}
// 释放跳跃表结构
zfree(zsl);
}
生成节点层数随机函数
/* Returns a random level for the new skiplist node we are going to create.
*
* 返回一个随机值,用作新跳跃表节点的层数。
*
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned.
*
* 返回值介乎 1 和 ZSKIPLIST_MAXLEVEL 之间(包含 ZSKIPLIST_MAXLEVEL),
* 根据随机算法所使用的幂次定律,越大的值生成的几率越小。
*
* T = O(N)
*/
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}这里的random()不加参数会返回一个0到最大随机数的任意整数,这个数&0xFFFF实际上是高位清零,那么结果必为0到65535之间的一个数。即前半部分是产生一个0-65535的随机数。
后面是一个参数乘以65535。如果前一个数小于后面这个数,层数加一,即层数加一的概率为ZSKIPLIST_P。这里是模拟幂次定律,越大层数生成的概率越小。这里ZSKIPLIST_P设置的是0.25,但是为什么设为0.25也是一个问题。好像是比较随意设置的。查了好久也没查出来,看来不是啥重要的东西,不要在小问题钻牛角尖了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









