







1、基础知识
字符(Character):是文字和符号的总称。例如'A'、'B'、'汉'、'$'等。
字符集(Charset):是一个系统支持的所有抽象字符的集合。
字符编码(Character Encoding):是一套法则,描述字符集与数字系统之间建立对应关系。给定一系列字符,对每个字符赋予一个数值,用数值来代表对应的字符,这一数值就是字符的编码(Encoding)。例如,我们给字符'A'赋予数值0,给字符’B'赋予数值1,则0就是字符'A'的编码。
字符序(Collation):是指在同一字符集内字符之间的比较规则;确定字符序后,才能在一个字符集上定义什么是等价的字符,以及字符之间的大小关系;每个字符序唯一对应一种字符集,但一个字符集可以对应多种字符序。
mysql字符序的命名规则:字符集名字_语言_后缀,
几种常见后缀:_ci(表示大小写不敏感)、_cs(表示大小写敏感)、_bin(表示按编码值比较)
例如:在字符序“utf8_general_ci”下,字符“a”和“A”是等价的;
2、常用字符集和字符编码
2.1.ASCII、Latin-1
ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符;但是7位编码的字符集只能支持128个字符。
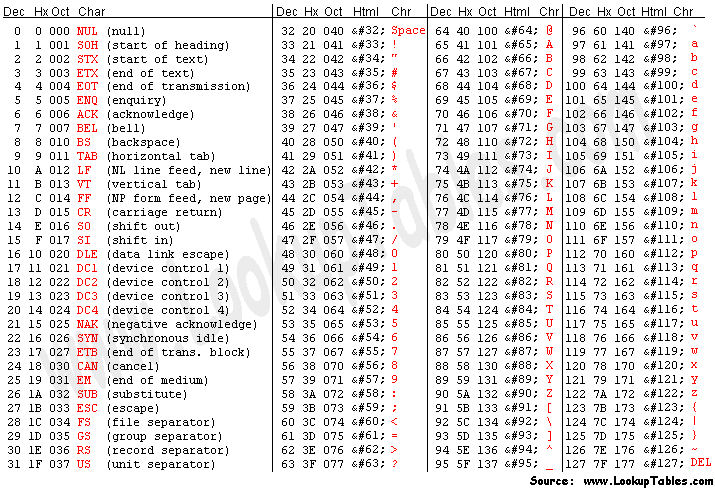
ISO-8859-1又称Latin-1:是一个8位单字节字符集,它把ASCII的最高位也利用起来,并兼容了ASCII,新增的理论空间是128,但它并没有完全用完。

2.2.GB2312、GBK
GB2312字符集:中国国家标准简体中文字符集,包括基本汉字,缺少罕用字。
GBK字符集:GB2312字符集的扩展,支持中国国内少数民族的文字,汉字收录范围包含繁体汉字以及日韩汉字。
GBK编码:采用多字节编码。
2.3.Unicode
Unicode字符集:世界上所有的符号纳入其中,每一个符号都给予一个独一无二的编码,以满足跨语言、跨平台进行文本转换、处理的要求。
Unicode编码:计算机一般使用 4个字节(32 位)(两个字节不够用时)来存放一个序号,该序号为每个字符在 UNICODE 字符集中的序号。
2.4.UTF
UTF:是Unicode 的实现(或存储)方式,称为Unicode转换格式。Unicode是字符集,UTF-32/ UTF-16/ UTF-8是三种字符编码方案。
UTF-8编码:是一种针对Unicode的可变长度字符编码,也是一种前缀码。
Utf-8 中文三个字节,英文一个字节
Unicode 中文两个字节,英文两个字(不够用时4字节)
gb2312,gbk 中文两个字节,英文一个字节
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









