







一、Xpath表达式:
XPath(全称:XML Path Language)即 XML 路径语言,它是一门在 XML 文档中查找信息的语言,最初被用来搜寻 XML 文档,同时它也适用于搜索 HTML 文档。因此,在爬虫过程中可以使用 XPath 来提取相应的数据。
Xpath节点:有父、子、同代、先辈、后代节点
<?xml version="1.0" encoding="utf-8"?>
<shop>
<book>
<title lang="zh-CN">java</title>
<name>Java编程思想</name>
<year>2011</year>
<address>www.baidu.com</address>
</book>
</shop>说明:
title name year address 都是 book 的子节点 book 是 title name year address 父节点 title name year address 属于同代节点 title 元素的先辈节点是 book shop shop 的后代节点是 book title name year address
二、Xpath基本语法
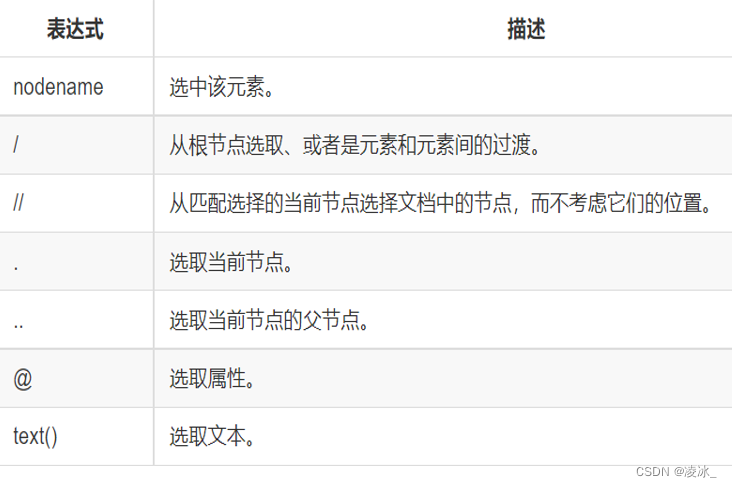
1) 基本语法
2) xpath通配符
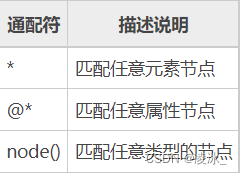
| xpath('/div/*') | 选取div下的所有子节点 |
| xpath('/div[@*]') | 选取所有带属性的div节点 |
3) 多路径匹配
xpath表达式1 | xpath表达式2 | xpath表达式3
| xpath('//div|//table') | 选取所有的div和table节点 |
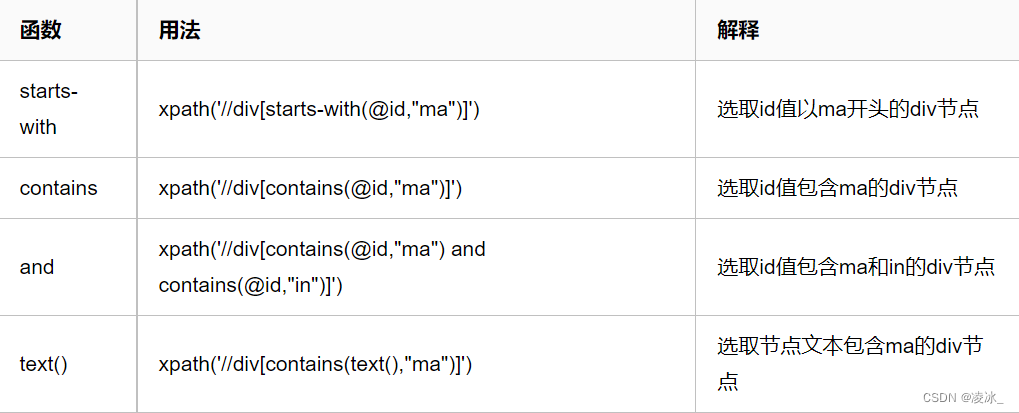
4)功能函数
三、lxml库
lxml 是 Python 的第三方解析库,完全使用 Python 语言编写,它对 Xpath 表达式提供了良好的支持,因此能够了高效地解析 HTML/XML 文档。本节讲解如何通过 lxml 库解析 HTML 文档。
3.1 安装lxml库
pip3 install lxml
3.2 lxml使用流程
1) 导入模块
from lxml import etree
2)创建解析对象
parse_html = etree.HTML(html)
3) 调用xpath表达式
r_list = parse_html.xpath('xpath表达式')
4) lxml库数据提取
print(r_list)
四、实战案例
#豆瓣书店
import requests
from lxml import etree
if __name__ == '__main__':
url='https://market.douban.com/book/?utm_campaign=book_nav_freyr&utm_source=douban&utm_medium=pc_web'
headers_={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
res=requests.get(url,headers_)
# print(res.text)
html=etree.HTML(res.text)
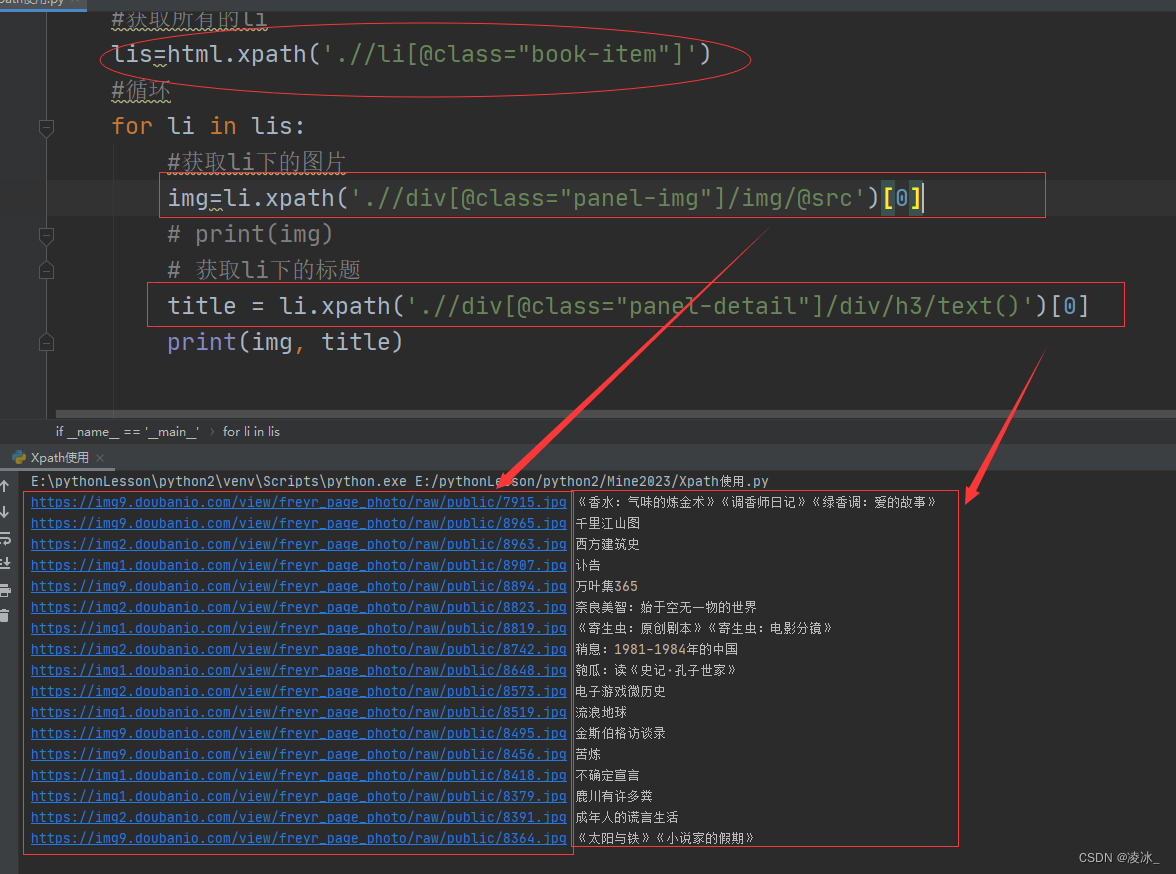
#获取所有的li
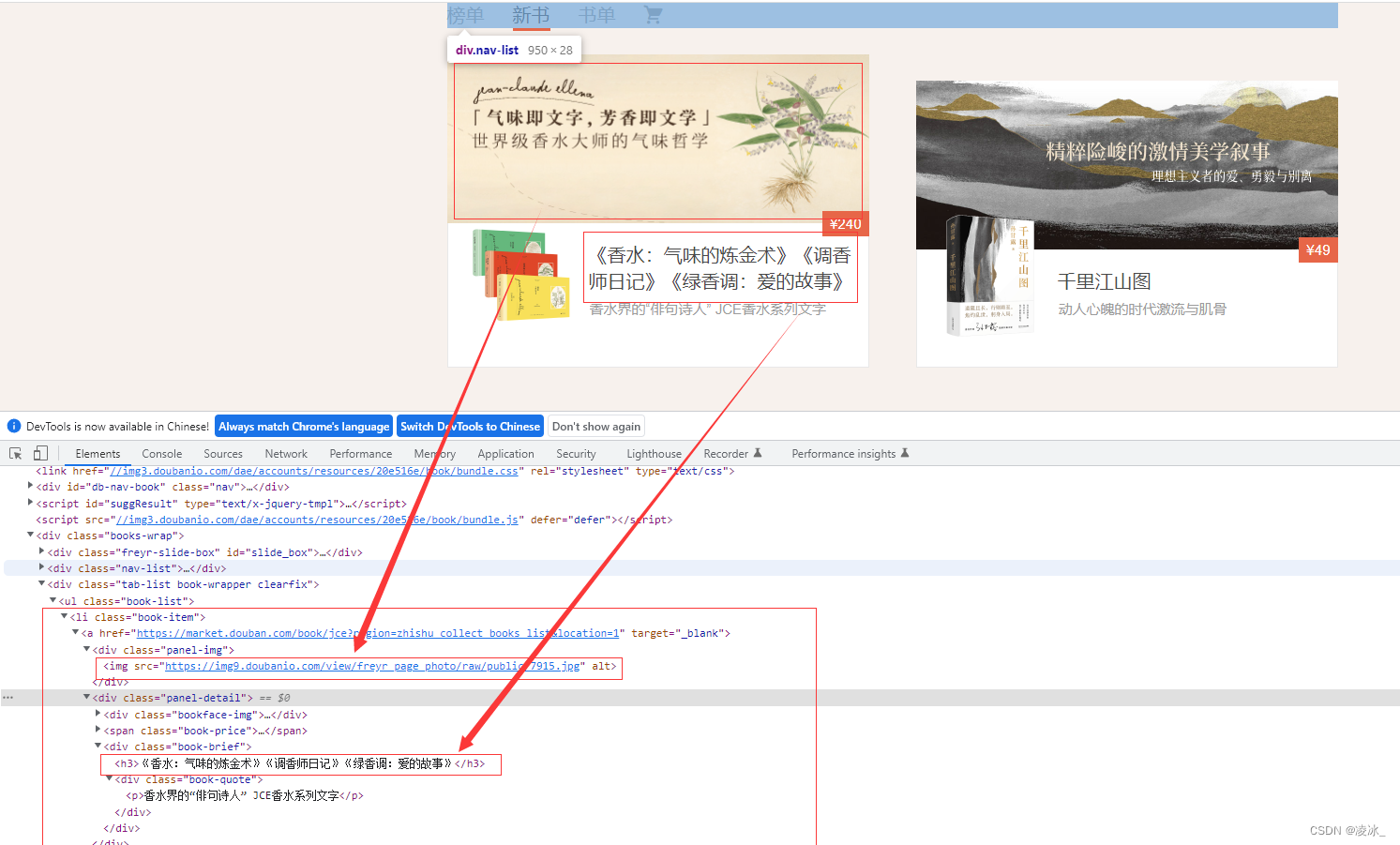
lis=html.xpath('.//li[@class="book-item"]')
#循环
for li in lis:
#获取li下的图片
img=li.xpath('.//div[@class="panel-img"]/img/@src')[0]
# print(img)
# 获取li下的标题
title = li.xpath('.//div[@class="panel-detail"]/div/h3/text()')[0]
print(img, title)















 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









