




代码:
#保存excel
my.to_excel('df.xlsx',
#设置Excel1的工作表名
sheet_name='表1'
)
异常:
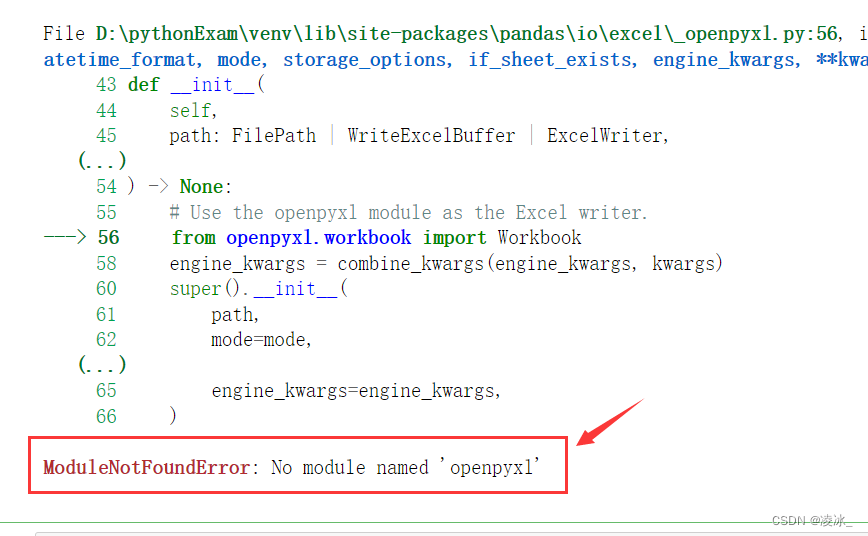
原因:没有导入这个库openpyxl
解决:
1) 使用 pip list 查看
2) 如果没有,则安装 pip install openpyxl
3) 再导入 import openpyxl
 在尝试使用`my.to_excel()`保存Excel文件时遇到了错误,因为缺少了openpyxl库。要解决这个问题,首先需要使用`piplist`检查openpyxl是否已安装。如果未安装,应通过`pipinstallopenpyxl`进行安装。安装完成后,导入openpyxl库以继续操作。
在尝试使用`my.to_excel()`保存Excel文件时遇到了错误,因为缺少了openpyxl库。要解决这个问题,首先需要使用`piplist`检查openpyxl是否已安装。如果未安装,应通过`pipinstallopenpyxl`进行安装。安装完成后,导入openpyxl库以继续操作。
#保存excel
my.to_excel('df.xlsx',
#设置Excel1的工作表名
sheet_name='表1'
)
1) 使用 pip list 查看
2) 如果没有,则安装 pip install openpyxl
3) 再导入 import openpyxl
 3081
7804
3081
7804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























