







2014年底验证码识别称为一个热门的话题,各种12306抢票软件层出不穷,百度,搜狗,360等公司推出了火车票抢票软件。在给人们带来便利的同时,当然给黄牛有了可乘之机。下面介绍几种我们常见的验证码。
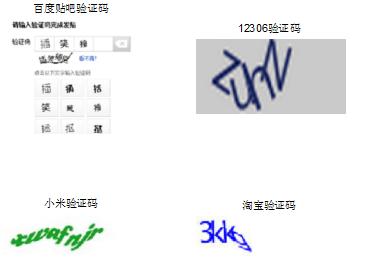
从验证码识别角度来看(除了百度贴吧验证码没有研究过),小米的验证码是最好识别的。12306和淘宝验证码的差不多,都出现了粘连字符,在图像上做粘连字符切割是一个难点。
下面就以淘宝验证码识别做一个算法的综述
一、数据库的建立
1、字符切割(图像部分)
二、字符识别(算法识别部分)
三、Matlab GUI的制作和MFC demo
一、数据库的建立
图像和机器学习的算法研究中,建立一个自己需求的数据库是最耗时耗力。如果要去购买一个数据库也要花费很大的财力。下面给出淘宝验证码数据库建立的过程。
在资源里有一个产生淘宝验证码的小程序,这个程序是直接从淘宝网在线截取的,需要联网才能使用。可以得到一系列的验证码,如下图所示。

当然得到的验证码是无标签的,因为这种验证码识别是不能用无监督学习的,只能有监督学习才能进行识别,所以必须要进行打码,就是为验证码贴上标签,这就避免了人为贴标签,人为贴标签非常耗时。如下所示。
w7zc YRZY 3KKG ppvt auku 8qaq
mpcf shcu rdcy fzpx EKW2 FTJE
wfpe 8FH8 PWRB dkp5 4rqc zccq
这个是不分大小写的,当然增加了识别的难度。淘宝这套验证码没有出现0,O,i,1,l,因为这些人可能都会分错,故这个验证码识别是一个31分类的问题。这套验证码的难点在于,字母会出现粗细,粘连交叉,部分大小写这些难题,而且类别太多,这就为验证码识别的正确与否增大了难度(4个都识别正确才算正确)。
1、字符切割(图像部分)
字符分割是验证码识别中最难的部分。特别是那些粘连特别严重的验证码往往会出现错误,这就是切割不好。下面分步骤说明验证码的切割。
1.1字符的定位
下面先看一张切割的过程验证码

I.字符定位切割 II.二值化处理 III.字符切割
首先是定位字符在整张图片中所处的位置,然后对字符进行切割,分块,得到子训练图像和识别图像。得到子图像当然是贴上标签的。下面是这些图像的类别
2,3,4,5,6,7,8,9,Aa,Bb,Cc,Dd,Ee,Ff,Gg,Hh,Jj,Kk,Mm,Nn,Pp,Qq,Rr,Ss,Tt,Uu,Vv,Ww,Xx,Yy,Zz.
下面给出训练图像的例子。

跟
MNIST
一样,需要生成带有标签的batch。
一共在网上抓取了25000张验证码,这样一共生成了10w张子块,差不多一类3000张,其实对于这套验证码是远远不够的,由于标记好的图片需要打码。这套验证码的图片类型非常丰富,有细,有粗,倾斜,粘连等等,不像
MNIST
那么规范,那么需要的样本就要更多了。另外一个原因就是我做的分割是不好的,在短时间内还没有想到好的图像分割算法,(现在在尝试
ing
)。
一共生成了10个小batch,采用随机批量学习,这样不容易造成局部最优,和过拟合的问题,实验结果证实是正确的。
下面是图像处理部分的程序
main.m
I = imread('21.jpg');
I(I>=125)=125;
figure
subplot(3,4,[1,2]);
imshow(I);
title('原始验证码','FontSize',8);
gray = rgb2gray(I);
% obj=imresize(obj,[60,80]);
I1 = double(gray)/256;
obj = imcomplement(I1);
obj= im2bw(obj, graythresh(obj));
[ix1,iy1]=xfenge(obj);
[jx1,jy1]=yfenge(obj);
subplot(3,4,[3,4]);
imshow(I);
hold on
x=jx1:jy1;
y=(ix1-1)*ones(jy1-jx1+1,1);
plot(x,y,'k-','linewidth',1.4);
hold on
x=ix1-1:iy1+1;
y=jx1*ones(iy1-ix1+3,1);
plot(y,x,'k-','linewidth',1.4);
hold on
x=ix1-1:iy1+1;
y=jy1*ones(iy1-ix1+3,1);
plot(y,x,'k-','linewidth',1.4);
hold on
x=jx1:jy1;
y=(iy1+1)*ones(jy1-jx1+1,1);
plot(x,y,'k-','linewidth',1.4)
title('定位后的图像','FontSize',8);
subplot(3,4,[5,6])
obj=I(ix1:iy1,jx1:jy1,:);
imshow(obj);
title('切割后的图像','FontSize',8);
gray=rgb2gray(obj);
bw=im2bw(gray,0.4);
subplot(3,4,[7,8]);
imshow(bw);
title('二值化之后的验证码','FontSize',8);
bw=imresize(bw,[32,128]);
subplot(3,4,9);
patch1=bw(:,1:32);
imshow(patch1);
title('patch1','FontSize',8);
subplot(3,4,10);
patch2=bw(:,33:64);
imshow(patch2);
title('patch2','FontSize',8);
subplot(3,4,11);
patch3=bw(:,65:96);
imshow(patch3);
title('patch3','FontSize',8);
subplot(3,4,12);
patch4=bw(:,97:128);
imshow(patch4);
title('patch4','FontSize',8);
function [ix,iy]=xfenge(goal1)
[m,n]=size(goal1);
ix(m)=0;
xx=0;j=1;
for x=1:m
for y=1:n
if goal1(x,y)==1;
xx=1;
end
end
if xx==1
ix(j)=x;
j=j+1;
end
end
ix=ix(1);
iy(m)=0;
xx=0;j=1;
for x=m:-1:1
for y=n:-1:1
if goal1(x,y)==1;
xx=1;
end
end
if xx==1
iy(j)=x;
j=j+1;
end
end
iy=iy(1);function [jx,jy]=yfenge(goal1)
[m,n]=size(goal1);
jx(m)=0;
xx=0;j=1;
for y=1:n
for x=1:m
if goal1(x,y)==1;
xx=1;
end
end
if xx==1
jx(j)=y;
j=j+1;
end
end
jx=jx(1);
jy(m)=0;
xx=0;j=1;
for y=n:-1:1
for x=m:-1:1
if goal1(x,y)==1;
xx=1;
end
end
if xx==1
jy(j)=y;
j=j+1;
end
end
jy=jy(1);
二、字符识别(算法识别部分)
由于切割后的子块是二值化之后,每个batch是稀疏矩阵,这样用deep learning里面的sae算法是最好的,速度也是最快的。下面是整个网络的结构

输入层是1024个神经元,隐含层1为700个神经元,需要经过sae确定参数网络前馈参数,隐含层2为400个神经元需要sae确定前馈参数,输出层为31个神经元,连接一个softmax分类,然后整个网络再进行微调。
注意:一定不要全批量训练,虽然速度快,但是会产生局部最优,过拟合的问题,除此之外,内存太小根本跑不了。也要一个一个的输入,会非常慢。
PS:需要数据集可以发emali:349342215@qq.com。子程序见资源
<span style="font-family:Times New Roman;">clear all
clc
load('final_total_data.mat');
inputSize = 32 *32;
numClasses = 31; % Number of classes
numLabels =31;
hiddenSize=700;
hiddenSize1=400;
sparsityParam = 0.1;
lambda = 3e-3;
beta = 3;
lambda = 1e-4;
%% ======================================================================
theta = initializeParameters(hiddenSize, inputSize);
opttheta = theta;
%-------------------------------------------------------------------
addpath minFunc/
options.Method = 'lbfgs';
options.maxIter = 1;
options.display = 'on';
for i=1:400
fprintf('第一层,第');
fprintf(num2str(i));
fprintf('次迭代');
for j=1:20
sub_data=data(:,(j-1)*5000+1:j*5000);
[opttheta, loss] = minFunc( @(p) sparseAutoencoderCost(p, ...
inputSize, hiddenSize, ...
lambda, sparsityParam, ...
beta, sub_data), ...
theta, options);
theta=opttheta;
end
end
trainFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ...
data);
%% ==================================================================
theta1 = initializeParameters(hiddenSize1, hiddenSize);
opttheta1 = theta1;
addpath minFunc/
options.Method = 'lbfgs';
options.maxIter = 1;
options.display = 'on';
for i=1:400
fprintf('第二层,第');
fprintf(num2str(i));
fprintf('次迭代');
fprintf('\n');
for j=1:5
trainFeaturesk=trainFeatures(:,(j-1)*20000+1:j*20000);
[opttheta1, loss] = minFunc( @(p) sparseAutoencoderCost(p, ...
hiddenSize, hiddenSize1, ...
lambda, sparsityParam, ...
beta, trainFeaturesk), ...
theta1, options);
theta1=opttheta1;
end
end
trainFeatures1 = feedForwardAutoencoder(opttheta1, hiddenSize1, hiddenSize, ...
trainFeatures);
%% ================================================
%STEP 3: 训练Softmax分类器
fprintf('softmax分类器训练');
fprintf('\n');
saeSoftmaxTheta = 0.005 * randn(hiddenSize1 * numClasses, 1);
softmaxLambda = 1e-4;
softoptions = struct;
softoptions.maxIter = 400;
softmaxModel = softmaxTrain(hiddenSize1,numClasses,softmaxLambda,...
trainFeatures1,label,softoptions);
theta_new = softmaxModel.optTheta(:);
%% ============================================================
stack = cell(2,1);
stack{1}.w = reshape(opttheta(1:hiddenSize * inputSize), hiddenSize, inputSize);
stack{1}.b =opttheta(2*hiddenSize*inputSize+1:2*hiddenSize*inputSize+hiddenSize);
stack{2}.w = reshape(opttheta1(1:hiddenSize1 * hiddenSize), hiddenSize1, hiddenSize);
stack{2}.b =opttheta1(2*hiddenSize1*hiddenSize+1:2*hiddenSize*hiddenSize1+hiddenSize1);
[stackparams, netconfig] = stack2params(stack);
stackedAETheta = [theta_new;stackparams];
addpath minFunc/;
options = struct;
options.Method = 'lbfgs';
options.maxIter = 1;
options.display = 'on';
for i=1:1000
fprintf('全局微调,第');
fprintf(num2str(i));
fprintf('次迭代');
fprintf('\n');
for j=1:20
sub_data=data(:,(j-1)*5000+1:j*5000);
sub_label=label((j-1)*5000+1:j*5000);
[stackedAEOptTheta,cost] = minFunc(@(p)stackedAECost(p,inputSize,hiddenSize1,numClasses, netconfig,lambda, sub_data, sub_label),stackedAETheta,options);
stackedAETheta=stackedAEOptTheta;
end
end
%% 测试
[pred] = stackedAEPredict(stackedAETheta, inputSize, hiddenSize1, ...
numClasses, netconfig,data_new(:,100001:end));
acc1 = mean(label(100001:end) == pred(:));
fprintf('Before Finetuning Test Accuracy: %0.3f%%\n', acc1 * 100);
[pred] = stackedAEPredict(stackedAEOptTheta, inputSize, hiddenSize1, ...
numClasses, netconfig,data(:,100001:end));
acc = mean(label(100001:end) == pred(:));
fprintf('Before Finetuning Test Accuracy: %0.3f%%\n', acc * 100);
save('stackedAEOptTheta.mat','stackedAEOptTheta');</span>
三、Matlab GUI的制作和MFC demo
MATLAB GUI需要stackAEPredict、xfenge、yfenge函数,和参数stackedAEOptTheta.mat,netconfig
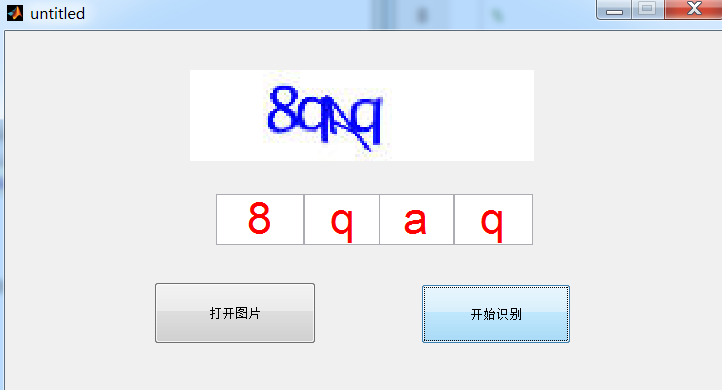
程序见资源
MFC demo
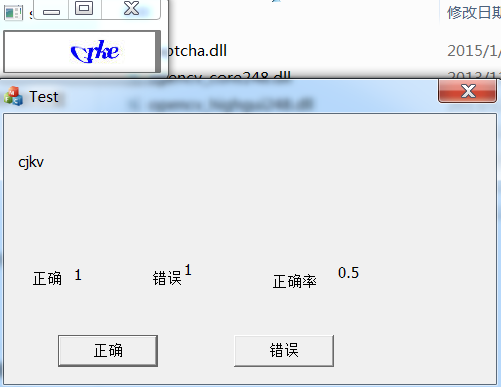
见资源
最终识别率能达到50%。

怀柔滑雪场















 1836
1836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









