






mysql执行顺序,explain关键字
背景
由于查询SQL时间过长,导致接口请求超时,我们对执行的sql进行了对应的sql优化。这里总结复盘一下sql优化的过程以及对应的结果。
前置知识
这里前置知识主要分为两个部分,分别是: mysql的执行顺序和explain关键字解析。
mysql的执行顺序
mysql的执行顺序如下
- from
- on
- join
- where
- group by
- having + 聚合函数
- select
- distinct
- order by
- limit
基本数据:
Mysql的执行顺序是先去执行 from 然后根据 on关键字去筛选目标表,筛选出的结果在进行join 或者using,这样形成一个临时表。然后去使用 where 条件去筛选这个临时表。然后对这个临时表进行 group by 进行分组(如果有having 就去筛选)。执行到这里,所需要的数据基本就有了。
目标数据:
select来筛选我们需要的目标列,筛选完成之后,使用 distinct ,order by ,limit ,进行数据的筛选,我们所需要的数据即搞出来了。
分析代码
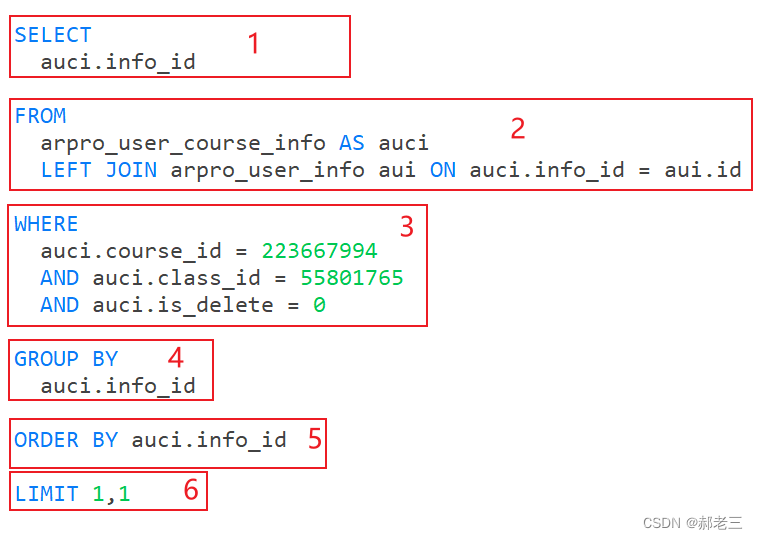
上面的查询一共分成了6个代码块。基本囊括了上文所说的执行顺序。在这个实例里,sql语句执行的顺序应该是
2–>3–>4–>1–>5–>6
清楚了执行顺序的作用
我们清楚了mysql的执行顺序由什么作用呢?对我们对mysql的使用有什么帮助呢?
-
筛选数据
能写到on里的条件不写到 where里,能写到where里的不写到having里。
where条件里,将排除信息多的条件写到前面 -
提升认识
利于我们理解sql语句,并对sql语句进行优化,提高我们对数据库的理解。利于以后编写复杂的sql语句。
explain关键字解析
概念
explain 英文含义是解释、说明的意思。在mysql里,一条查询语句需要经过MySql查询优化器的各种成本和规则,生成一个执行计划。而explain关键字就是来查询这个计划的。通过explain关键字,可以分析我们的查询语句的效率。
语法: explain select * from table
基本构成
| 列名 | 用途 | 构成 |
|---|---|---|
| id | SELECT查询语句都对应一个唯一id | id越大,越优先执行。相同由上向下执行。NULL最后执行 |
| select_type | SELECT对应的查询类型 | (SIMPLE:简单查询不包含子查询和UNION查询)、 (PRIMARY:复杂查询中最外层SELECT) 、(DERIVED:包含对于派生表的查询)、(UNION: 在 UNION 查询语句中的第二个和紧随其后的 SELECT)。 |
| table | 表名 | 值可能是表名、表的别名或者一个未查询产生临时表的标识符。table 列是 格式时,标识此查询依赖于 id = N的查询。先执行id = N的查询 |
| partitions | 匹配的分区信息 | |
| type | 单表的访问方法 | 从优到差 system > const > eq_ref > range > index > all |
| possible_keys | 可能用到的索引 | 与具体建立的索引有关 |
| key | 实际使用到的索引 | 与具体建立的索引有关,未使用的话是null |
| key_len | 实际使用到的索引长度 | – |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 | – |
| rows | 预估需要读取的记录条数 | – |
| filtered | 某个表经过条件过滤后剩余的记录条数百分比 | 对于单表来说意义不大,主要用于连接查询中。 |
| Extra | 额外的一些信息 | 有几十个,根据信息进行查询 |
重点
看到上面这么多的构成,信息,头都大了。我们还是列一下需要重点进行关注的信息
- id
id越大,优先级越高,Id相等,从上往下顺序执行。 - select_type
SIMPLE简单查询,PRIMARY复杂查询,DERIVED衍生查询(from子查询的临时表),派生表。 - type
system > const > eq_ref > range > index > all 阿里巴巴规约要求最差也要是range级别。
distinct和group by效率对比
结论:
- 有索引的情况下,group by和distinct 都能用索引,效率相同
- 无索引的时候,distinct 效率高于 group by,distinct 是根据信息不同进行直接进行去重,group by 的原理是对结果先进行 分组排序 ,然后返回每组中的第一条数据。
用法 - distinct 的用法 select distinct 列1 , 列2 from table
- group by 的用法 select 列1,列2 from table group by 列1 ,列2
优点,缺点
- 如果是单纯的去重操作的话,无论是否有索引,distinct 的效率都更加高,但是如果 查询的列和去重的列不对应的话,distinct就无法使用了。相较于group by 不够灵活。
- group by 的语义更加的明确,并且group by 可以根据分组的情况加上聚合函数,做一些其他的处理,功能更加丰富。但是有时候效率将低于distinct。、
优化案例
原sql语句
SELECT
aui.ding_phone,
aui.ding_name,
aui.chaoxing_name,
aui.chaoxing_phone
FROM
( SELECT info_id FROM arpro_user_course_info WHERE course_id = 223667994 AND class_id = 55801765 AND is_delete = 0 GROUP BY info_id ) auci
LEFT JOIN arpro_user_info aui ON auci.info_id = aui.id
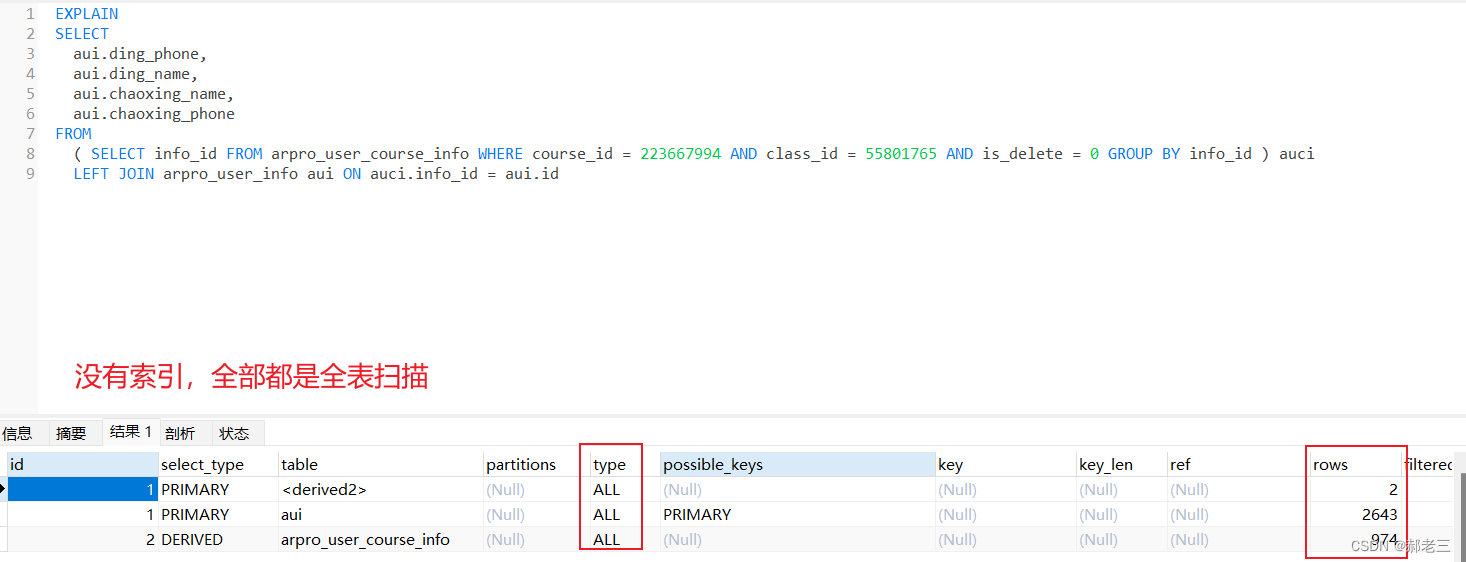
优化
1.arpro_user_course_info 表添加索引。

分析结果 对 arpro_user_course_info 的查询已经走了我们建立的索引了

2.group by 改为 distinct。
3.解决数据类型不一致导致主键索引失效问题

查看我们优化过后的sql不难发现,我们的 aui也就是 user_info 表 走的还是全表检索。但是实际上我们的sql语句中只用到了 user_info 表的 主键id字段,按道理将,这个查询应该走 一级索引 也就是主键索引。让我们来排查一下数据类型
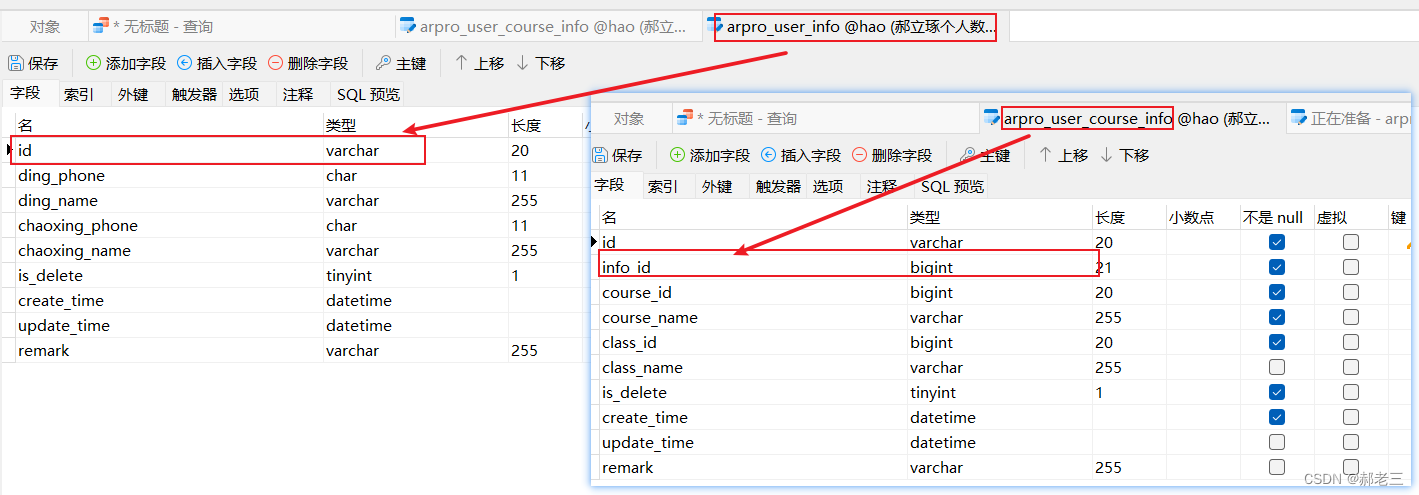
这里我们看到 user_info 表的主键为 varChar类型,而user_course_info 表的外键为 bigint类型,由于联查的时候,主外建不一致,导致的索引失效,从而导致索引失效,sql变慢。
阿里规约规定:

让我们将 user_info 表的字段修改为bigint,查看一下语句分析结果
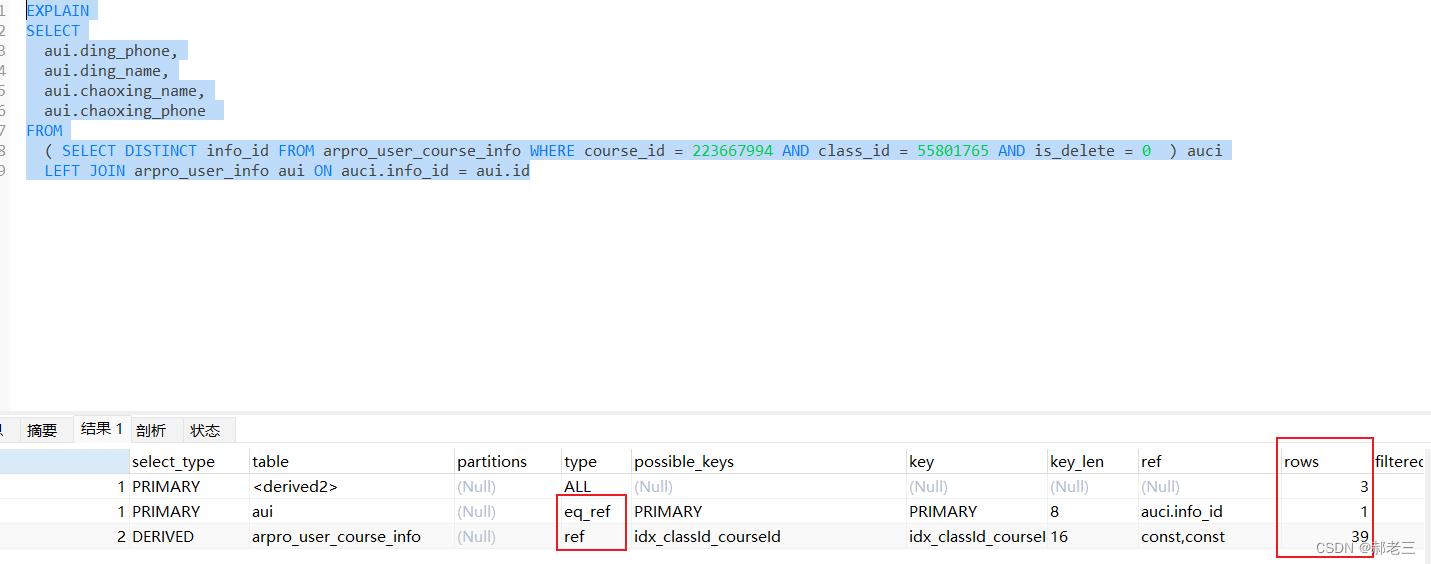
这时我们可以看到,两个表的查询均走了对应的索引。对应的sql语句就优化好了。
总结提升
本次主要讲解了,如何着手去分析sql语句,从哪些方面做sql优化。对以上知识清晰,才能写出高性能的sql语句



















 2786
2786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











