







【引言】
最近遇到了一个和kafka相关的问题,具体是在spark任务在一定并行度的情况下, 偶现个别executor因kafka消息发送超时导致失败的情况。正所谓磨刀不误砍柴工,为了能较好的定位问题,因此先对kafka客户端消息发送相关逻辑的代码进行了走读,本文就是对相关原理的一些总结。
【相关概念(数据结构)】
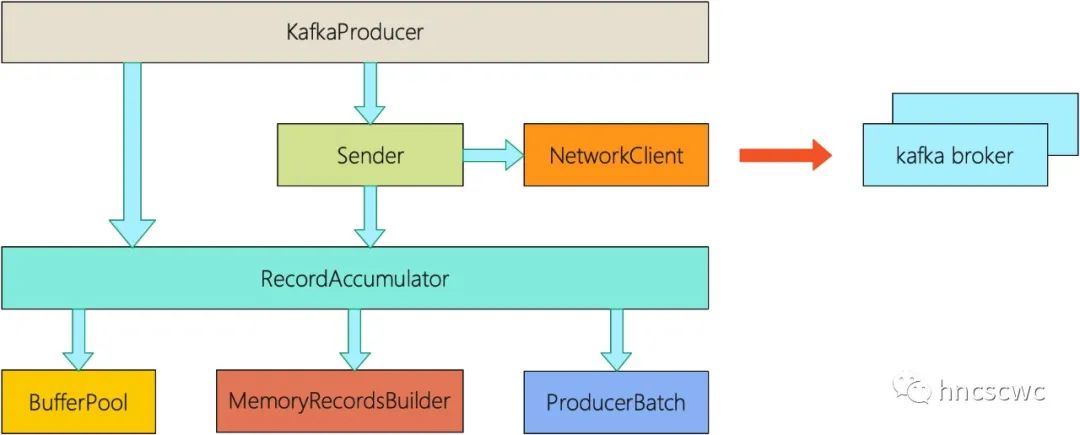
在客户端里,一些重要的概念或对应的数据结构包括:
1. ProducerRecord
生产者发送的每条消息,都对应一个ProduceRecord类实例对象,记录了包括消息的key,value,时间戳,header,topic,partition信息。
2. ProducerBatch
客户端发送消息时,并不是调用send接口发送一条消息,就实际将该消息通过网络发送出去,而是攒够一批进行发送。在具体实现中,ProducerBatch就对应这个批的概念。ProducerBatch本质上是一批消息的集合,也就是上面ProduceRecord中的key、value、header经过序列化后的字节数据存储在ProducerBatch中。
3. RecordAccumlator
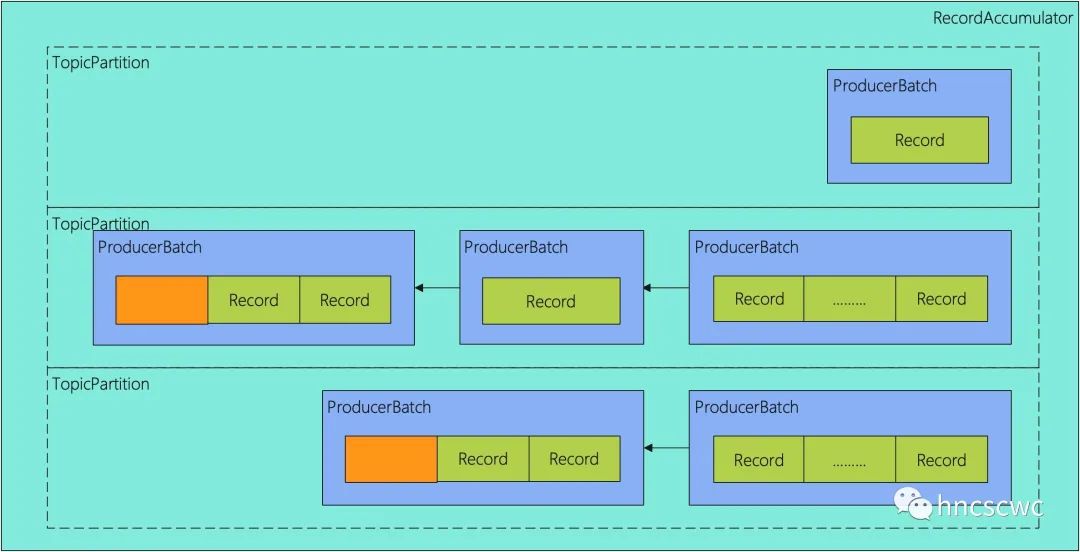
RecordAccumlator是上面ProducerBatch的集合。由于消息只能发往topic的某一个分区,发往同一个topic的一个或多个消息组成ProducerBatch,多个ProducerBatch组成一个链表,在RecordAccumlator内部,则以topic的分区为key,ProducerBatch链表为value,缓存所有待发送的消息。
一个简单的示例如下图所示:
4. BufferPool
一块大的内存池,存储消息记录序列化后的字节数据,即ProducerBatch中用于存放具体消息内容的内存就是从BufferPool中申请的。
在BufferPool内部,分为两种类型的内存,一种是固定大小的内存,这些内存先从系统申请,使用完(消息发送完毕并确认收到)后,回收后放到内存池中,以便后续使用;另一种是不固定大小的内存,通常是大于一个批大小的内存,这些内存也是直接从系统申请,但使用完成后,不会放到内存池,而是等触发垃圾回收时,被系统回收掉。
5. Sender
专门的消息发送线程,定时从RecordAccumlator取出一批消息并发送给服务端。
6. KafkaNetwork
负责与所有broker通信,包括与broker建立连接,协议上的交互(将消息按指定协议格式发送,定时更新元数据等等),以及处理broker的响应消息。
如果从全局的视角来看,kafka客户端的架构可能是这样的一个分层:
【消息发送流程】
从上面的介绍中,以及可以猜出大概的消息处理流程。简单概括客户端消息发送的逻辑就是:业务线程(调用producer.send()的线程)将消息序列化,并存放到ProducerBatch中,然后按需唤醒sender发送线程;发送线程从RecordAccumlator挑选出待发送的ProducerBatch列表,并按照指定协议格式构造请求,然后发送给topic分区leader对应的broker,接着接收服务端的响应,并进行处理以及回调通知。
展开来说的话,流程如下图所示: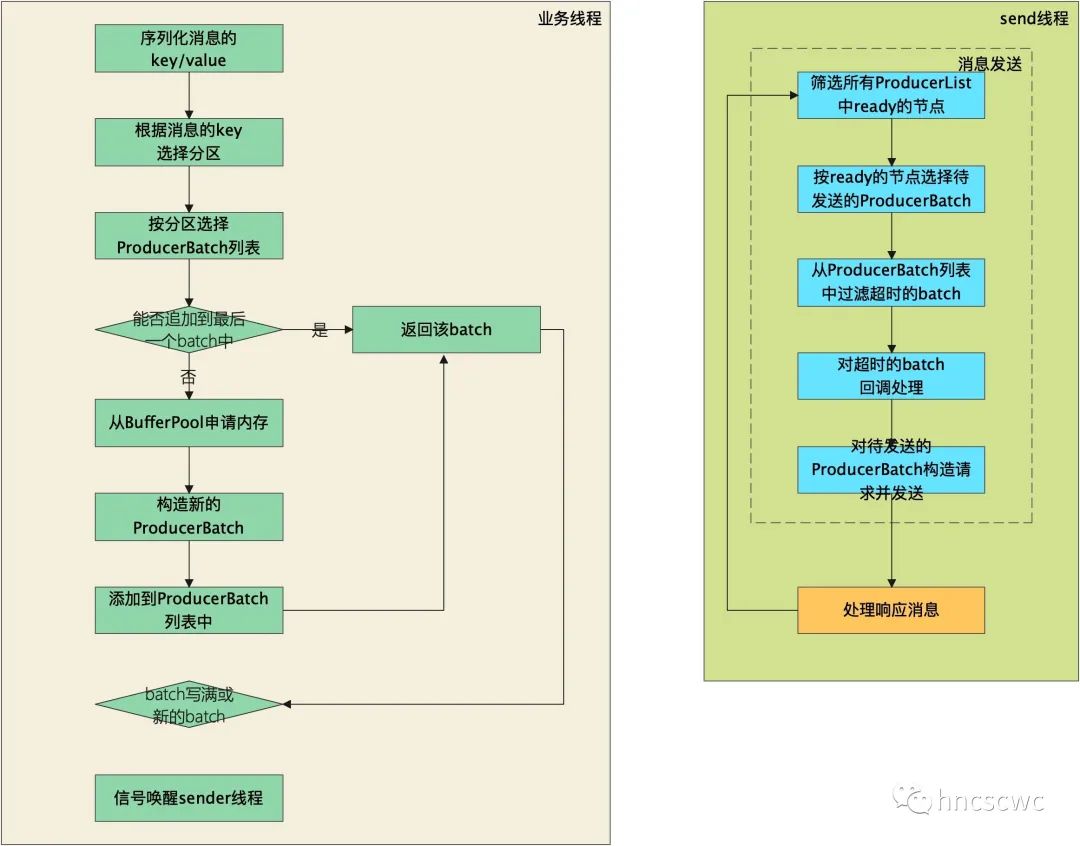
还是分为两部分,在业务线程中:
-
调用send接口后,接口内部会对消息(ProduceRecord)中key、value进行序列化,然后根据key选择一个对应的分区,默认情况下是轮询选择。
-
然后根据选定好的分区,找到对应的ProducerBatch列表,并尝试追加写入到最后一个batch中,如果能成功追加,则直接返回该batch
-
如果不能成功追加,则从BufferPool中申请一块内存,如果消息的大小超过一个batch指定的大小,则按实际消息大小来申请,如果不足一个batch的大小,则按一个batch大小来申请
-
申请到内存后,构造一个ProducerBatch,并将消息添加到其中,随后将该batch添加到对应的ProducerBatch列表尾部(以保证同一分区消息的顺序),最后返回该batch
-
外层对batch进行判断,即该batch是否写满或是否为新创建的batch,如果是则唤醒发送线程进行工作,如果不是就等待发送线程定时发送(这就好比很多旅游景点中接驳车的逻辑一样,客流高峰期,满了就走,平峰期准点才走)
在发送线程中:
-
在发送时,先对所有ProducerBatch列表中的batch进行筛选,过滤掉没有leader的分区,然后汇总分区leader的broker节点集合(首次与任一broker连接后,会自动获取服务的元数据信息,这就包括每个topic的每个分区,其leader所在的节点,因此可以根据分区筛选出对应需要发送的broker集合)
-
然后判断这些broker节点是否准备好,例如连接是否建立,是否还可以继续向其发送消息(可能之前持续发送了很多消息导致tcp窗口满了)等,对于未准备好的节点先从集合中移除
-
根据已经准备好的broker节点,挑选对应分区中ProducerBatch链表头的batch,并从链表中移除,作为本次真正待发送的批数据
-
接着过滤ProducerBatch中超时的batch,直接对这些batch进行回调通知。
-
然后才是将调用KafkaNetwork的接口,将批消息按指定协议封装发送。
-
最后通过IO事件回调,处理服务端的响应(包括消息的应答并逐层回调处理,可能的连接断开等等)
【有关的配置】
一些常用的,并且和上面流程或概念有关的参数包括:
1. buffer.memory
bufferPool的总大小,默认大小为32MB,每次分配后可用空间减少,当使用完回收后,可用空间又对应增加。如果单次申请的内存大于这个值,会直接抛异常;而如果BufferPool中剩余可用空间的值不满足条件时,则会阻塞线程,直到已有消息发送完成被释放后,会通知该线程解除阻塞,重新分配。
2. batch.size
一个ProducerBatch的消息,也是BufferPool中内存池里每个内存块的大小。默认大小为16KB。如果单条消息的大小大于这个值,则按实际大小从BufferPool中申请;如果单条消息的值小于这个值,则以该值为单位从BufferPool中申请。另外,当有新的消息写入时,如果一个ProducerBatch还未写满,并且剩余空间足够存储该消息,那么则会追加写到该ProducerBatch中。这也就意味着,一个ProducerBatch里包含一条大于该值的消息,或包含多条小于该值的消息。
3. request.timeout.ms
ProducerBatch的超时时间。每次往ProducerBatch追加写时,会更新追加时间,如果ProducerBatch的最后更新时间距离当前时间超过了发送超时时间,那么则认为是发送超时。并提示“ xxx ms has passed since last append”。
4. linger.ms
前面消息发送流程里提到了,单条消息并不是立即发送的,而是攒够一批发送,那么如果后续一直没有消息了,那是不是也就一直不发送了呢?显然不是这样,一个ProducerBatch最长等待时间就是由linger.ms来决定的,sender线程在从ProducerBatch的表头取出ProducerBatch时,会根据当前时间与ProducerBatch的最近一次发送时间(如果没有发送则是ProducerBatch的创建时间)进行比较,如果小于linger.ms指定的时间,则不进入本次真正待发送的列表中,同时计算出剩余时间,这其实就是后续poll轮询与broker的连接,等待IO事件的时间。
另外,如果当前时间减去ProducerBatch的创建时间,大于发送超时时间与linger.ms时间之和,那么也会导致ProducerBatch的发送超时。
【总结】
总结一下,通过本文的介绍,应该对kafka客户端内部的整体设计、消息存储发送流程有了个简单的认识,遇到一些报错时,也能从流程上进行初步的分析定位,至于深层次的问题,那就还需要再对源码深入分析,而本文开头提到的问题,由于问题未复现,这里也就没有近一步分析说明,后续再结合问题对内部原理展开说明。
好了,这就是本文的全部内容,如果觉得本文对您有帮助,不要吝啬点赞在看转发,也欢迎加我微信交流~














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









