







上一文对消费者组的一些概念,基本原理进行了简单描述,本文继续来聊聊消费者组中另外一个比较重要的内容:偏移量的存储。
【消费者偏移量的提交】
1. 消息消费的整体流程介绍
消费者在成功加入消费者组,并得到分配的分区信息后,对分配的分区依次向服务端发送请求获取上一次提交的偏移信息,并在内存中记录获取到的偏移量信息;
随后向服务端发送fetch(消息)请求,在该请求中就包含了内存中记录的偏移量信息,即从指定位置进行消息的消费。
服务端根据请求信息从log文件中读取文件,并给予响应。
客户端收到消息后,在内存中更新消费的偏移量信息,并由使用者手动或自动向服务端提交消费的偏移量信息。
2. 偏移量的提交流程
消费者的偏移量是由消费者自己来进行提交的,当前提交的方式有两种,自动提交或手动提交。
1)自动提交
当配置项"enable.auto.commit"设置为true后,消费者开启自动提交偏移的模式。自动提交本质上是消费者内部的轮询线程定时、异步对内存中记录的偏移量信息进行提交。
定时的时间间隔是由配置项"auto.commit.interval.ms"的值来决定的。
2)手动提交
当配置项"enable.auto.commit"设置为false后,也就禁用了自动提交偏移量的功能。此时使用者在处理消费的消息的同时,需要调用"commitSync"来手动提交消费偏移量信息。当然,从函数的字面意思也可以看出,手动提交请求动作是同步完成的。
【偏移量在服务端的存储】
kafka服务端对于消费者偏移量提交请求的处理,最终是将其存储在名为"__consumer_offsets"的topic中(其处理流程本质上是复用了向该topic生成一条消息的流程)。该topic默认有50个分区,不同消费者组的偏移量信息存储在不同的分区中,具体按照如下公式计算出存储的分区号:
Math.abs(groupId.hashCode) % groupMetadataTopicPartitionCount
// groupId.hashCode 为消费者组名称的哈希值
// groupMetadataTopicPartitionCount 为__consumer_offsets的分区数也就是说,一条偏移量提交的请求,以一个消息记录的形式在topic中存储。该消息记录分为key,value两部分,在key中记录了偏移量对应的消费者组名称、消费的topic名称以及分区编号;而在value中则记录了具体的偏移位置,元数据,以及提交时间戳和过期时间戳。
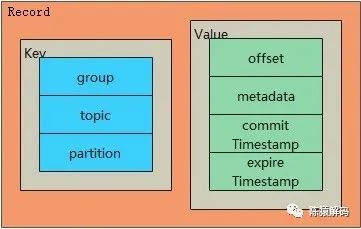
来看个实际实例:在名为hncscwc的topic的第3个分区上,有2条消息,名为spurs的消费者组在该topic上完成消费并提交了偏移量后的情况:
首先,可以通过命令,查看该消费者的偏移量情况:
sh kafka-consumer-groups.sh --bootstrap-server 192.168.42.198:9092 --describe --group spurs
Consumer group 'spurs' has no active members.
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
hncscwc 3 2 2 0 - - -其次,根据上面的计算公式,可以知道消费者组的偏移量存储分区为43。
scala> Math.abs("spurs".hashCode) % 50
res1: Int = 43最后,直接查看"__consumer-offsets-43"下的log文件的内容

需要注意的是:kafka在运行过程中仅在内存中记录了消费者组的相关信息(包括当前成员信息、偏移量信息等)。那么当删除了__consumer_offset对应的消息记录或者消息超过存储的有效期被自动删除后,对应的消费者组信息也随之消失了。
【偏移量失效的处理策略】
1. 消费者偏移量 out of range的场景
根据前面的介绍可以知道,生产消费的消息与消费者偏移量是分别存储在两个topic中的,通常来说,消费者在加入消费者组后,会从服务端获取对应分区的消费偏移量,这个偏移量一定是在正常生产消息的偏移量范围之内的。然而,在一些特定场景下,也会出现消费者偏移量不在生产的消息的偏移量范围之内的情况。下面就分别举例说明下:
1)消费的偏移量小于实际消息的偏移量
当使用者对topic配置了消息预留期限,或者称之为生命周期(retention),随着时间的推移,消息被删除(也可能是手动删除了老的消息),就可能出现实际消费的偏移量,小于已存储最小消息的偏移量的情况。
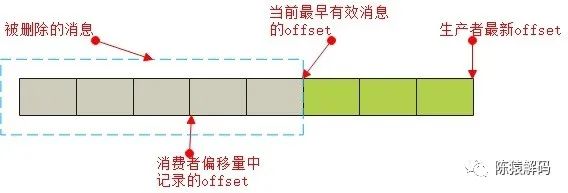
2)消费的偏移量大于实际消息的偏移量
一种可能出现该情况的场景是:生产者往topic发送消息的同时,消费者也在进行消费,并且最新消息均消费后进行了offset的提交,服务端在对消费者偏移量的记录完成刷盘动作后,生产消费的topic分区leader节点出现掉电异常,导致实际消息并未写入磁盘,从而出现这种情况。该场景比较难出现,但我们在实际环境中确实遇到过。
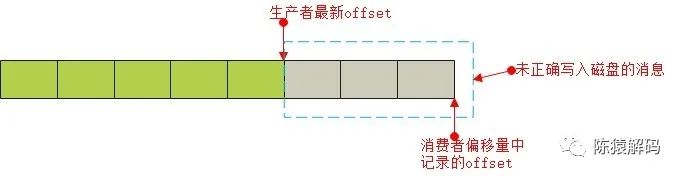
2. 消费者的处理策略
不管是上面那种情况,消费者在消费过程中,都会出现"out of range"的异常。在出现该异常后,由配置项"AUTO_OFFSET_RESET_CONFIG"来决定处理策略。该配置项可选的值包括:
none
即不做任何处理,kafka客户端直接将异常抛出,调用者可以捕获该异常来决定后续处理策略。
earliest
将消费者的偏移量重置为最早(有效)的消息的偏移位置,从头开始消费。这可能会引起消息的重复消费。
latest
将消费者的偏移量重置为最新的消息的偏移位置,从最新的位置开始消费。这可能会引起部分消息未进行消费出现消息"丢失"的情况。
关键的代码逻辑如下所示:
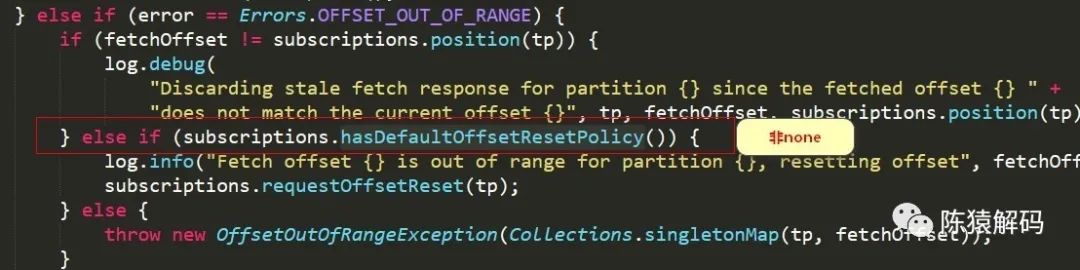
另外,在flink的kafka-connector和spark streaming中,该配置项的默认值不同,使用时需要注意。
【小结】
本文主要介绍了kafka消费者组中消费者偏移量的相关内容,并通过一些实际例子对原理分析进行论证,感兴趣的小伙伴们也可以对其中的内容自行测试分析。
好了,这就是本文的全部内容,如果觉得本文对您有帮助,请点赞+转发,如果觉得有不正确的地方,也可以拍砖指点,最后,欢迎加我微信交流~















 4715
4715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









