







雪崩问题
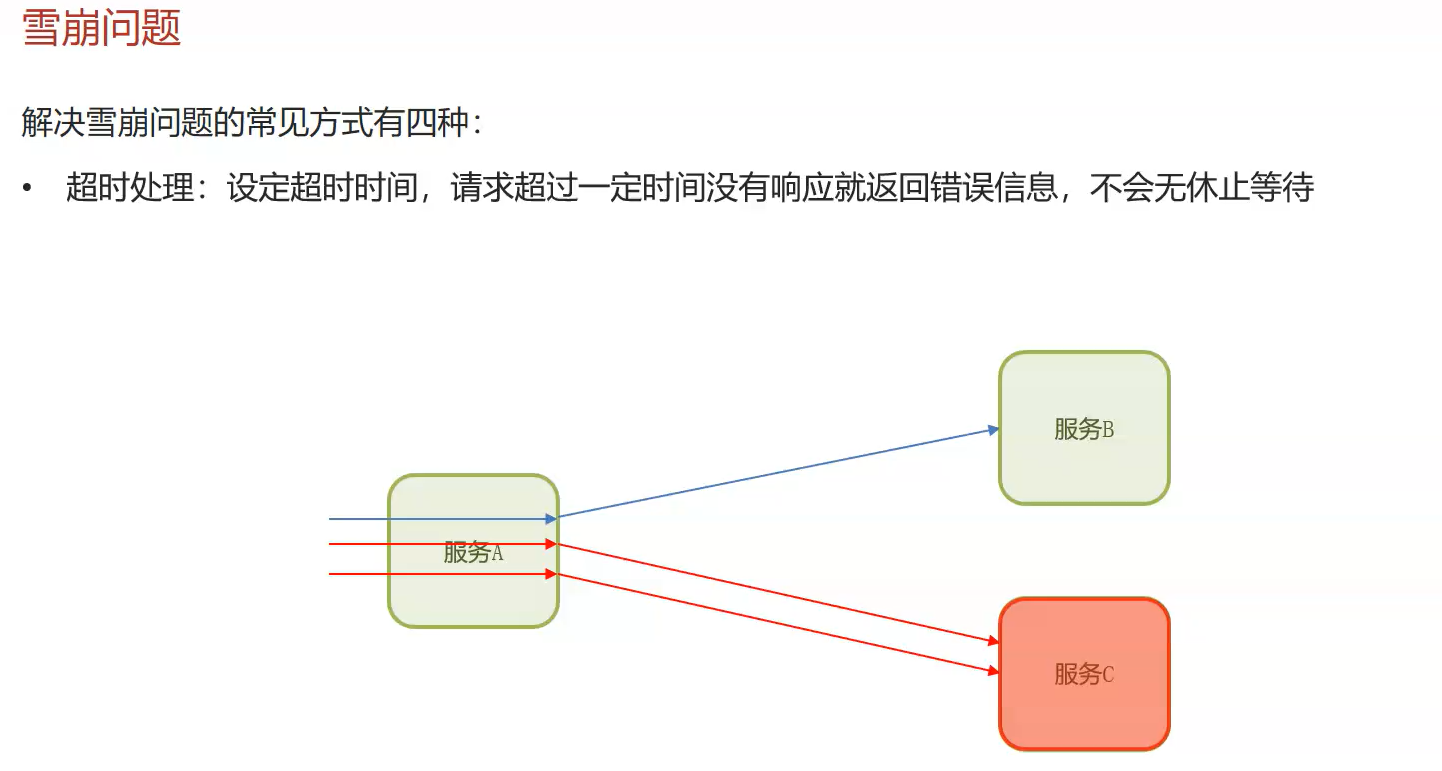
第一种超时处理:
设设置1s,如果c有1s没反应那么A就直接反应服务器异常,那么就不会让A一直等结果,这样就避免了牵连A错误
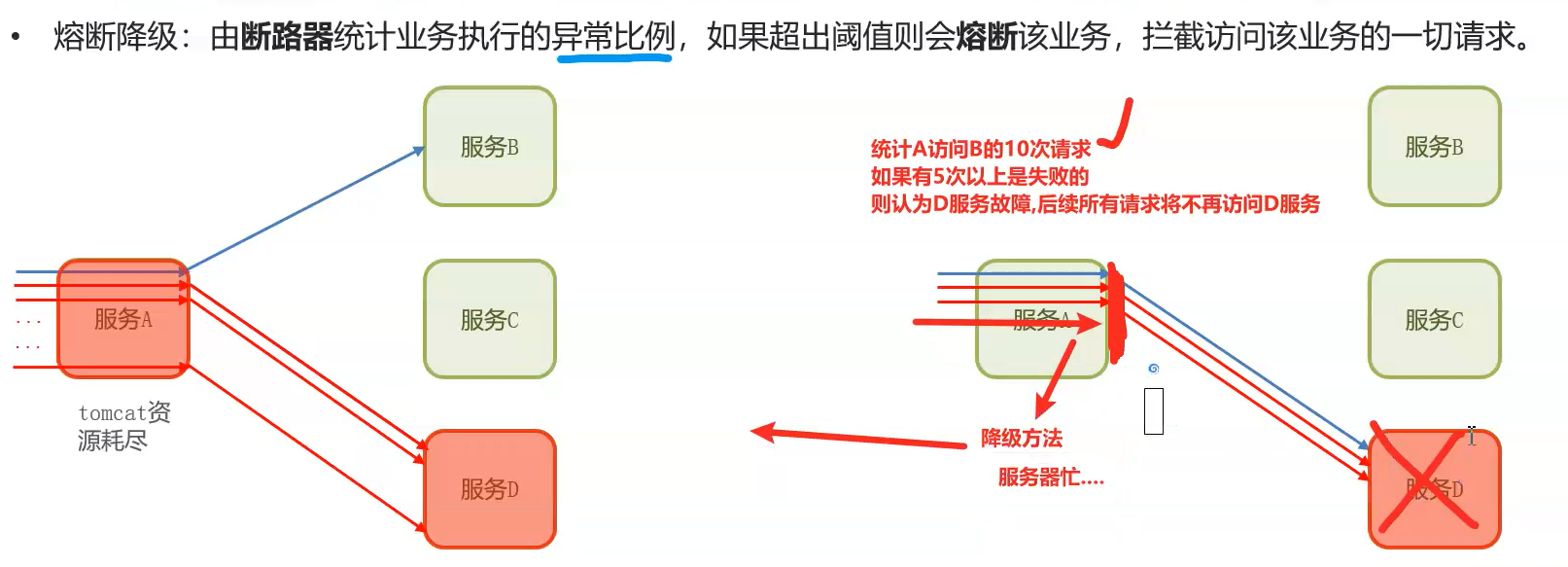
2熔断降级:
如果到达了这个阈值那么就会调用降级方法,这个降级方法自己写一个返回的数值例如:服务器忙。。。 阈值自己定义。 然后我们可以自己设置时间,熔断以后再隔一段时间就会去访问,当发现可以用了那么就解除熔断,这时候就继续使用
3舱壁模式:

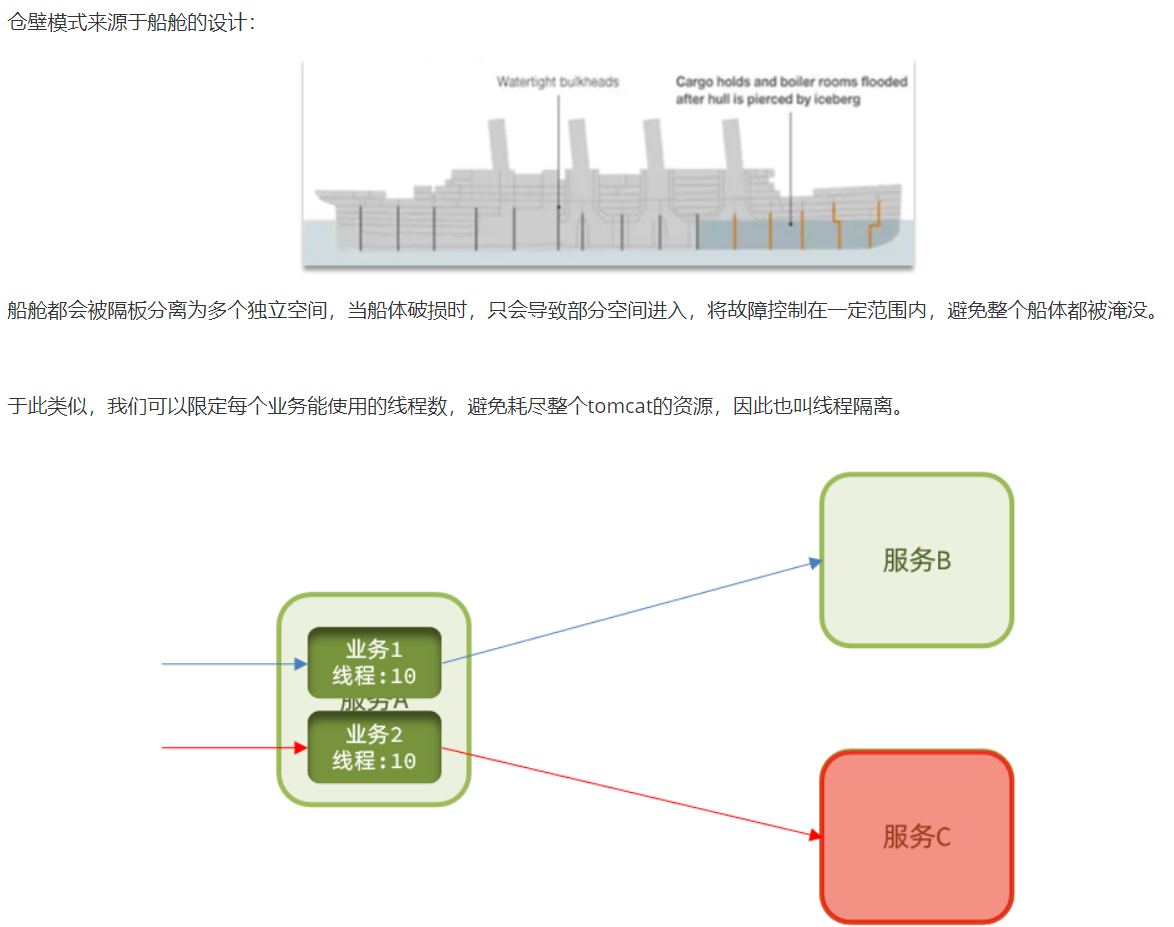
一个tomcat两个服务,每个服务单独一个线程,当服务C出错了也只是他单独那个线程出了问题不会影响业务1的线程
4流量控制:
使用sentinel,请求过来以后设置一次请求几个,避免一次性多个照成把服务器冲垮

线程池隔离和信号量隔离:
线程池隔离:就是一个业务分配一定的线程池,但是要维护线程池,所以会增加服务的开销
信号量隔离:设置一个计数,比如我们设置一个计数器,我们设计计数器最大为10也就是最多允许是个访问同时进行,当进来一个线程那么这个技术就加一,当累计加到10以后那么就不允许后面再尽量访问
熔断:如果到达了这个阈值那么就会调用降级方法,这个降级方法自己写一个返回的数值例如:服务器忙。。。 阈值自己定义。 然后我们可以自己设置时间,熔断以后再隔一段时间就会去访问,当发现可以用了那么就解除熔断。sentinel是基于失败比例和慢调用比例。Hystrix是基于失败比例
我们这使用的保护技术是sentinel
Sentinel
Sentinel是阿里巴巴开源的一款微服务流量控制组件。官网地址:home
Sentinel 具有以下特征:
•丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
•完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
•广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
•完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等
阿里的Sentinel和网飞的Hystrix(豪猪)之间的对比
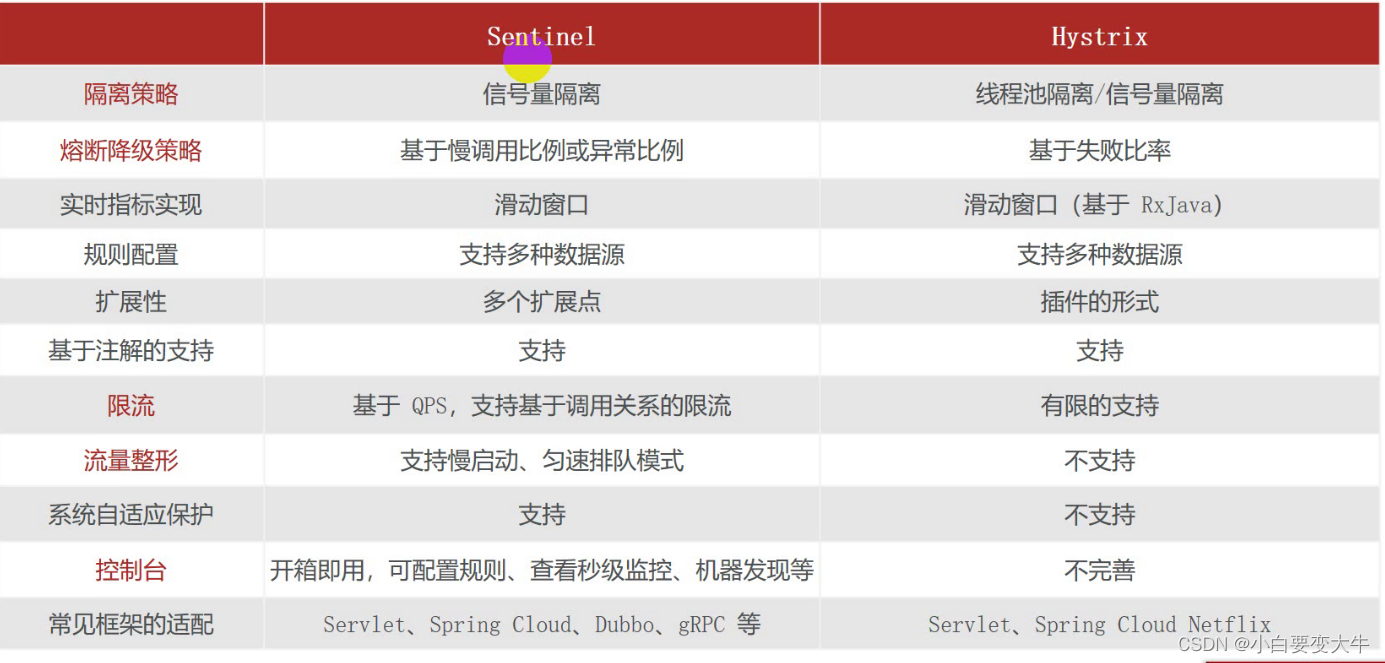
Sentinel和Hystrix名词解释
1:隔离策略,我们在上边也说过信号隔离和线程池隔离,也就是 信号隔离是计数,通过计数器的方式计数,控制一次只能访问多少个,而线程池隔离是将访问不同的业务通过线程池分开,这样即使一个服务下游出现了问题那么也不会因此来导致当前这个服务背拖垮
2:熔断降级:这里面阿里的sentinel有一个慢调用和异常比例:
慢调用就是如果我们的当前这个服务访问下游,我们设置的时间就是1s,如果这个请求时间超过我们设置的时间了,那么就认为下游服务出现了问题
异常比例和失败比例:其实两个差不多,就是当我们访问10次,我们的程序失败或者异常有五次,那么就是二分之一不成功,这时候我们设置加入有二分之一的失败比例或者异常比例,就认为下游服务器有问题。
3:限流:其中先解释一下QPS:
QPS:也就是每秒的查询效率,1s可以处理多少个请求就是QPS,比如1s处理的数据为1w,那么QPS就是1w
RT:也就是说单个请求请求时间是多少,那么请求时间就是RT,比如一个请求用了1s,那么RT就是1S
所以这个基于qps进行限流,也就是说根据我们每秒的处理数据的量进行限流
4:流量整形: 支持慢启动,也就是sentinel接收来自其他服务的请求会有序将这些请求往下放行。
sentinel的快速使用步骤
第一步:sentinel前边也说了就是开箱即用,我们将压缩包解压以后是一个jar包,直接在cmd里面输入Java -jar sentinel-dashboard.jar 即可使用,但是他默认是8080端口,如果我们想要切换端口可以在运行时这样输入: java -Dserver.port=自己想要的端口号 -jar sentinel-dashboard.jar
启动完以后直接就可以使用http://localhost:8080使用了,账号密码默认是sentinel
第二步: 然后比如我们的一台应用名称为orderservice的服务想要被sentinel的话,那么肯定也是需要加入依赖和配置的,如下:
依赖:
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>yml配置文件中配置:
spring:
cloud:
sentinel:
#下边8080是我们sentinel的端口号,这里是请求来了以后统统交给sentinel进行传播
transport:
dashboard: localhost:8080 这样以后我们的再次访问这个orderservice服务器的时候,我们的sentinel都会监控到,sentinel就相当于是程序的外壳,当访问请求过来以后肯定先经过sentinel这个外壳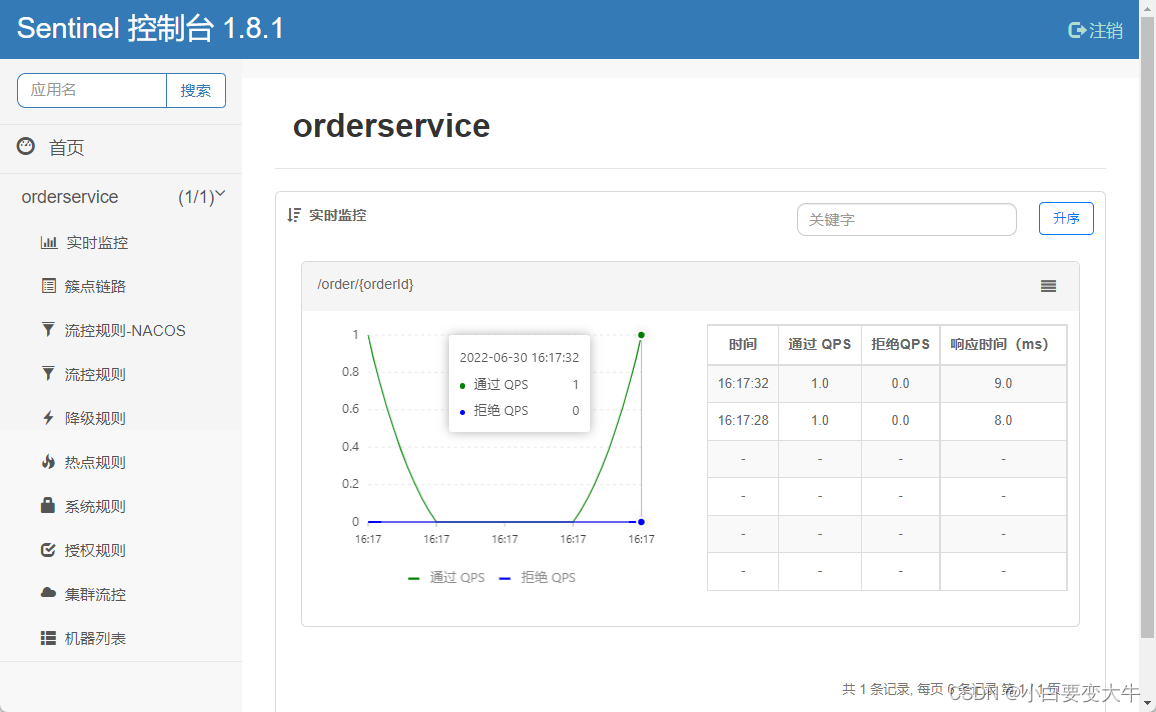
sentinel的可视化界面使用
簇点电路:
当请求进入微服务时,首先会访问DispatcherServlet,然后进入Controller、Service、Mapper,这样的一个调用链就叫做簇点链路。簇点链路中被监控的每一个接口就是一个资源。
默认情况下sentinel会监控SpringMVC的每一个端点(Endpoint,也就是controller中的方法),因此SpringMVC的每一个端点(Endpoint)就是调用链路中的一个资源
簇点电路其实也就是我们应用程序中可以被访问的接口,个人理解就是controller中的接口。,controller中有多少个可被访问的路径那么就有多少个簇点电路。如图: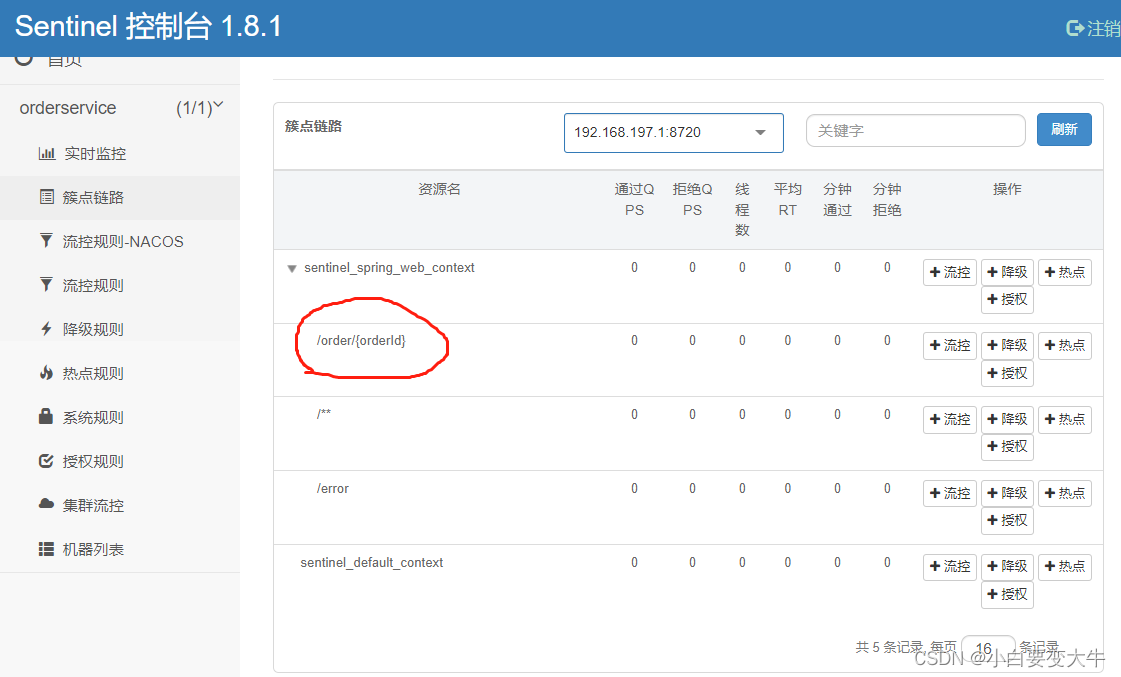
流量控制:
雪崩问题虽然有四种方案,但是限流是避免服务因突发的流量而发生故障,是对微服务雪崩问题的预防。我们先学习这种模式。
使用步骤:
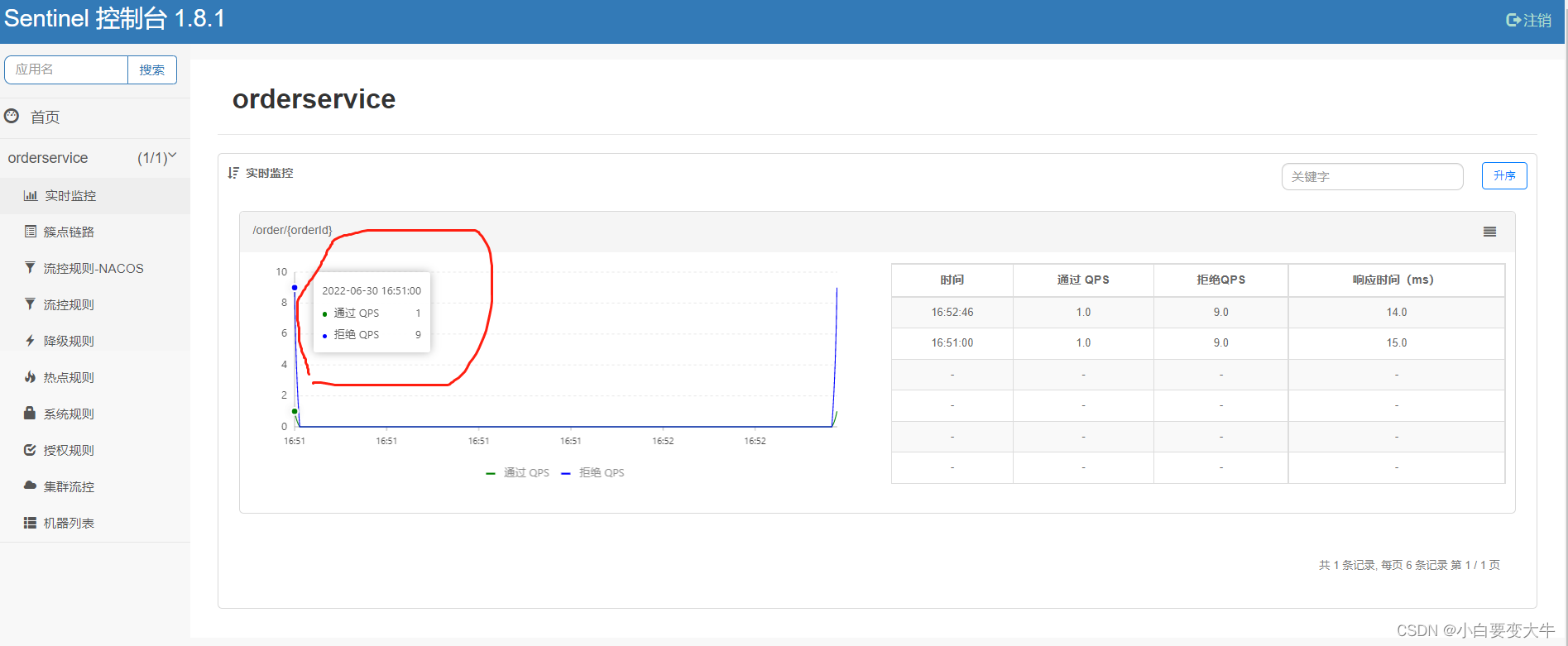
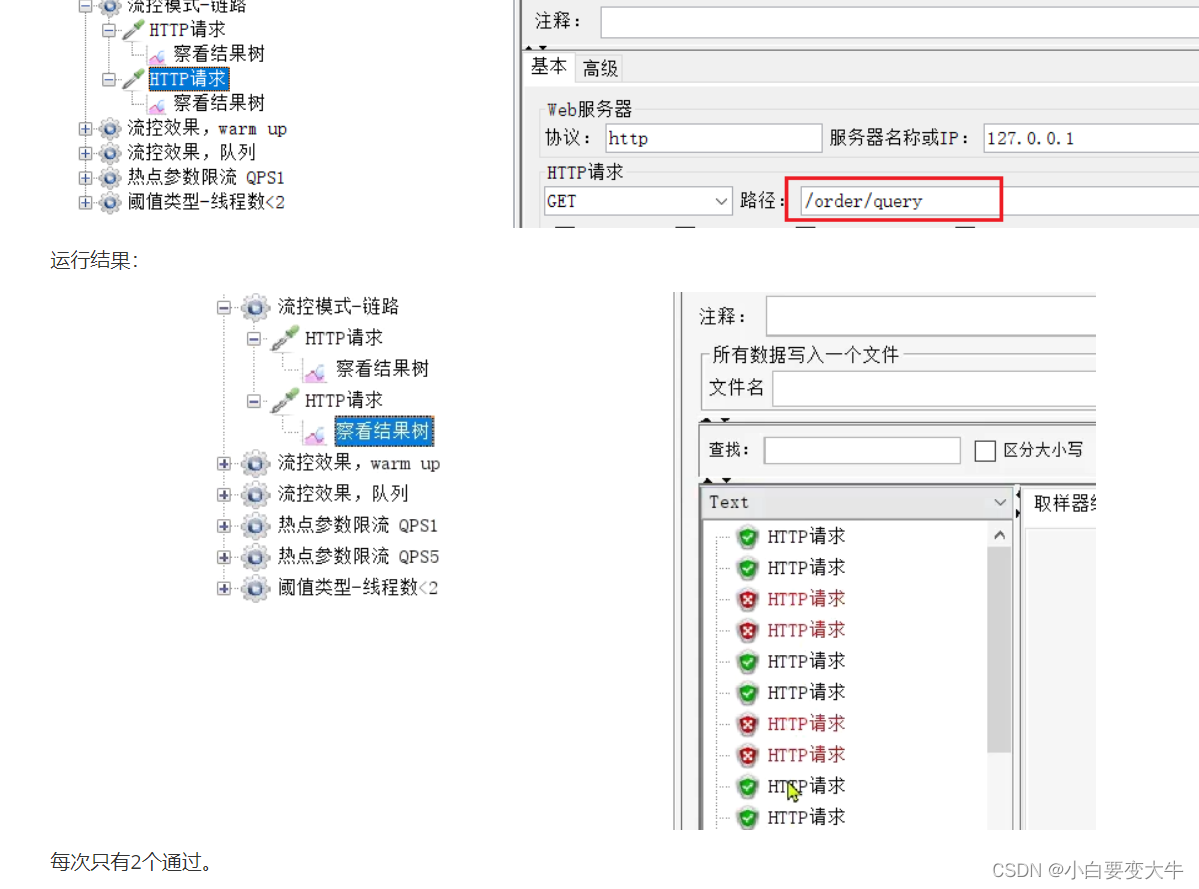
在我们的簇点链路中,将/order/{orderId}进行流量控制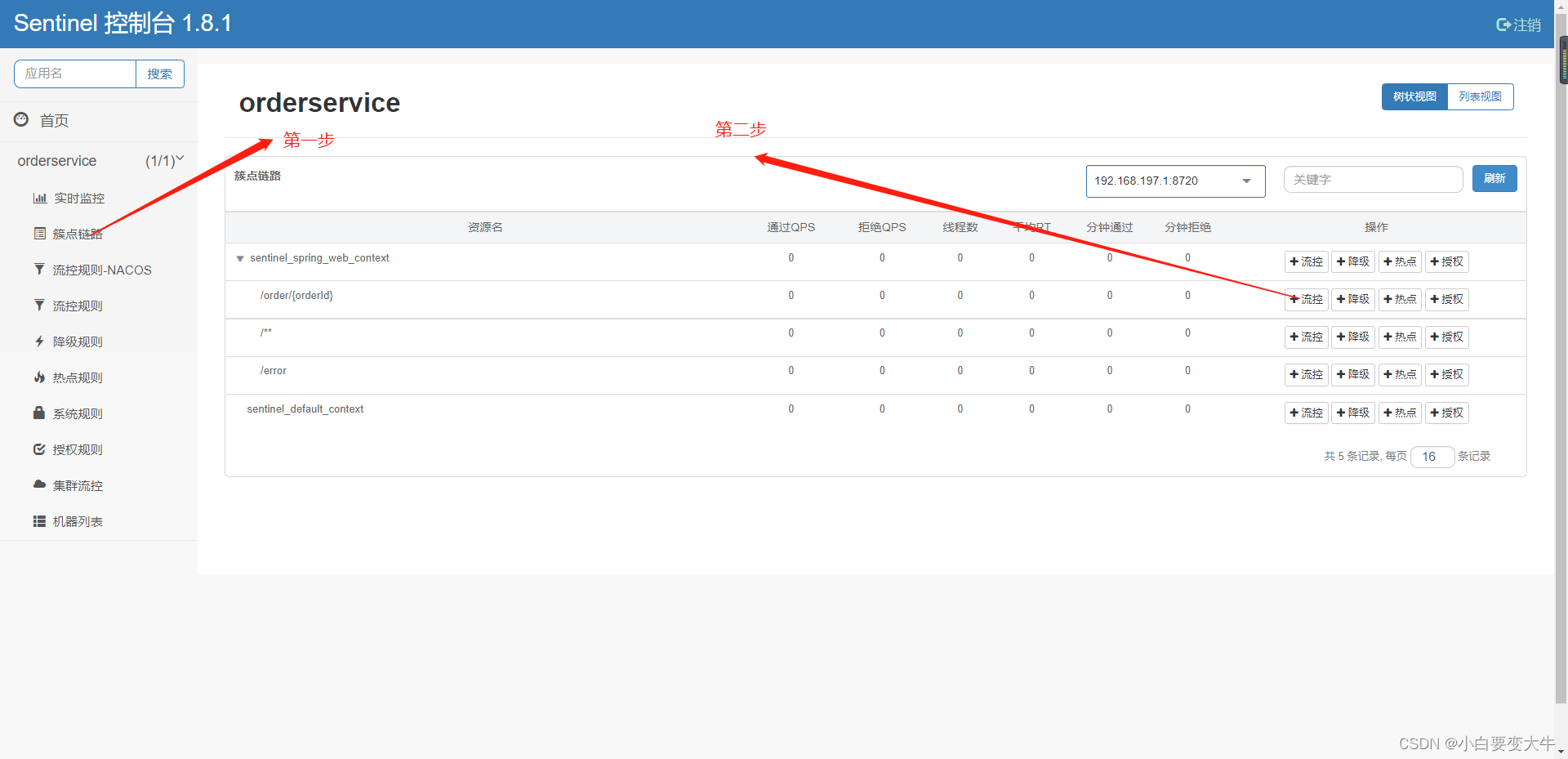
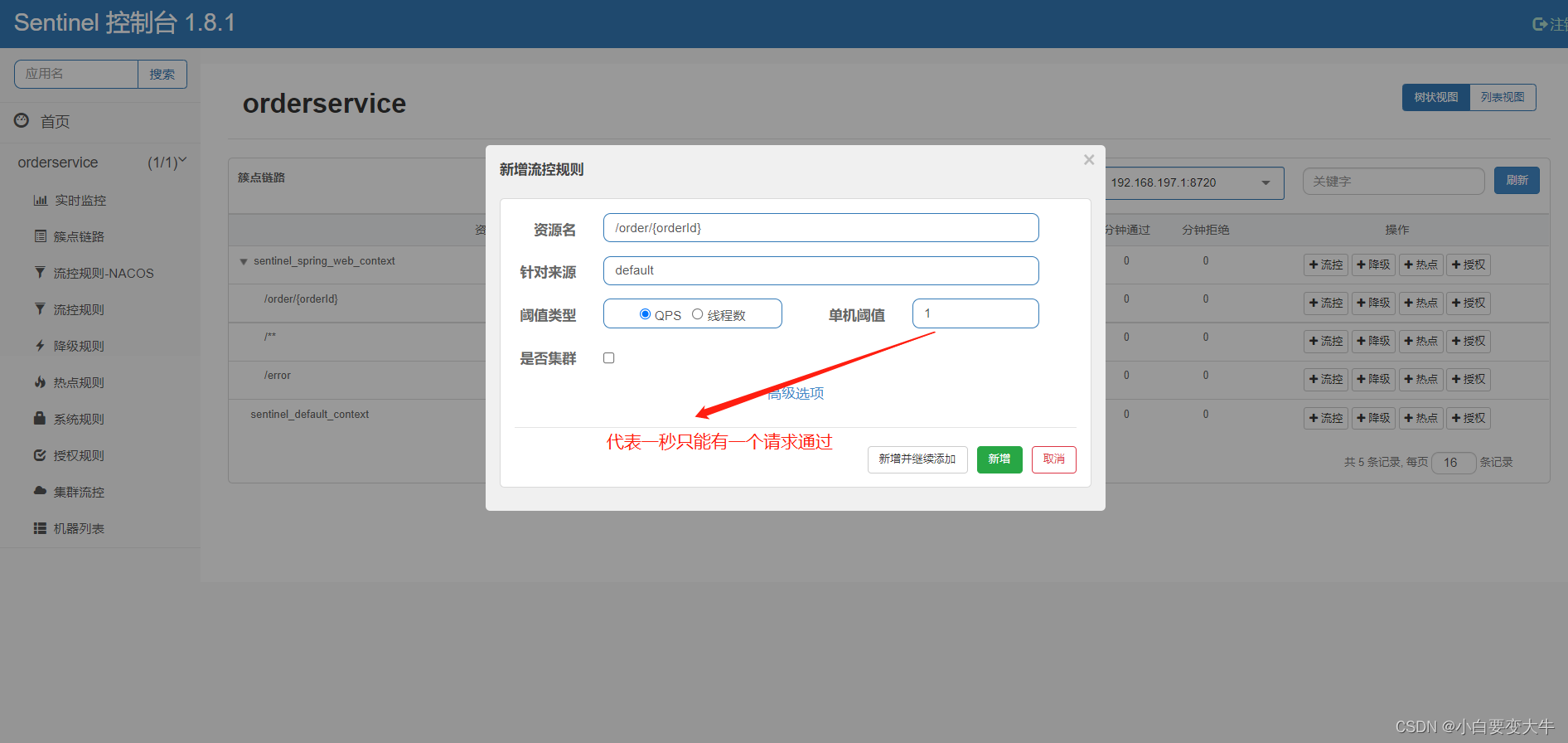
点击确认以后就自动跳到流控规则,这样我们再去访问这个接口的时候,那么就只能一秒请求一次,如果我们一秒有是个请求过来那么将会拦截九个;
记下来使用jmeter去测试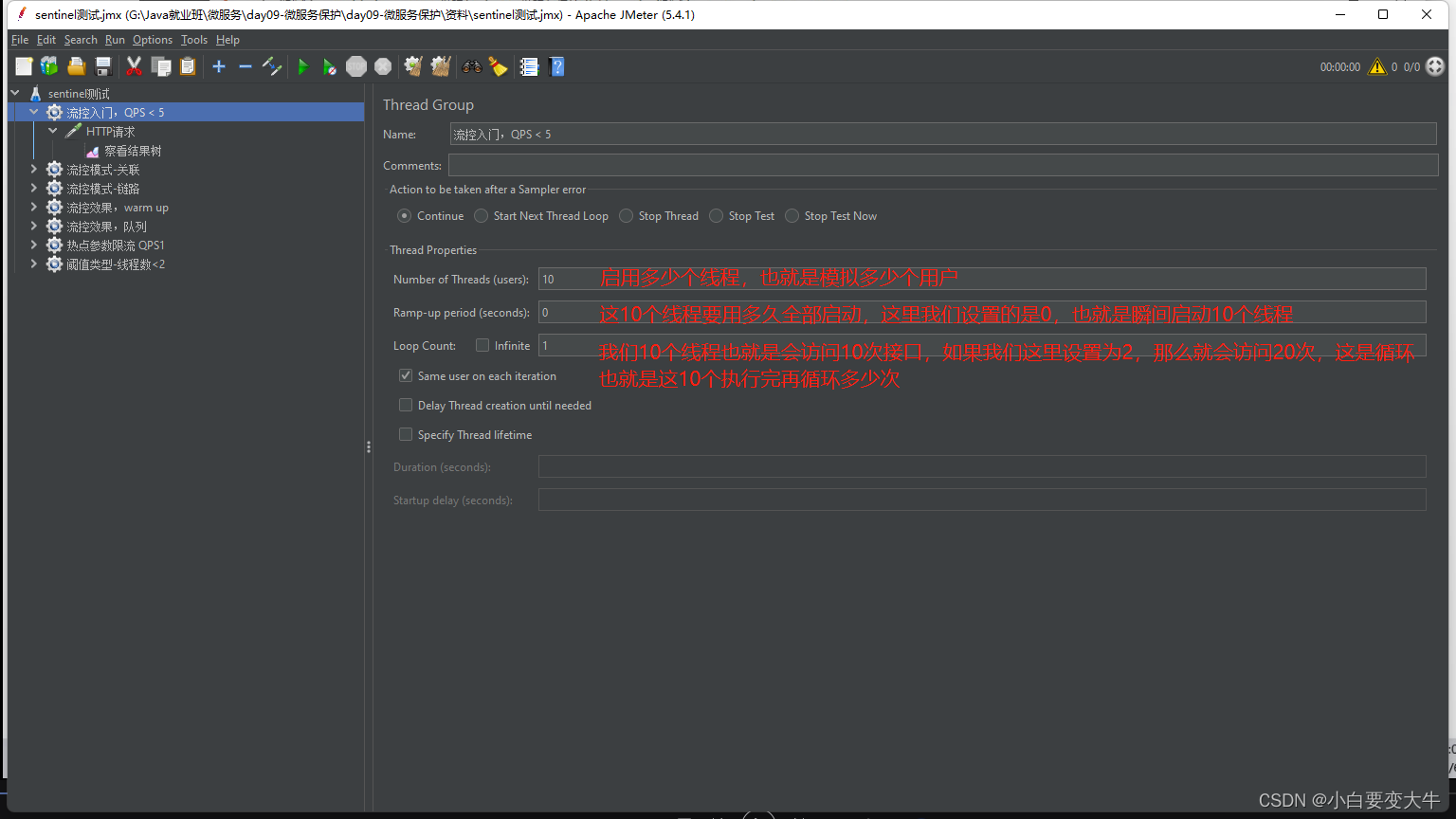
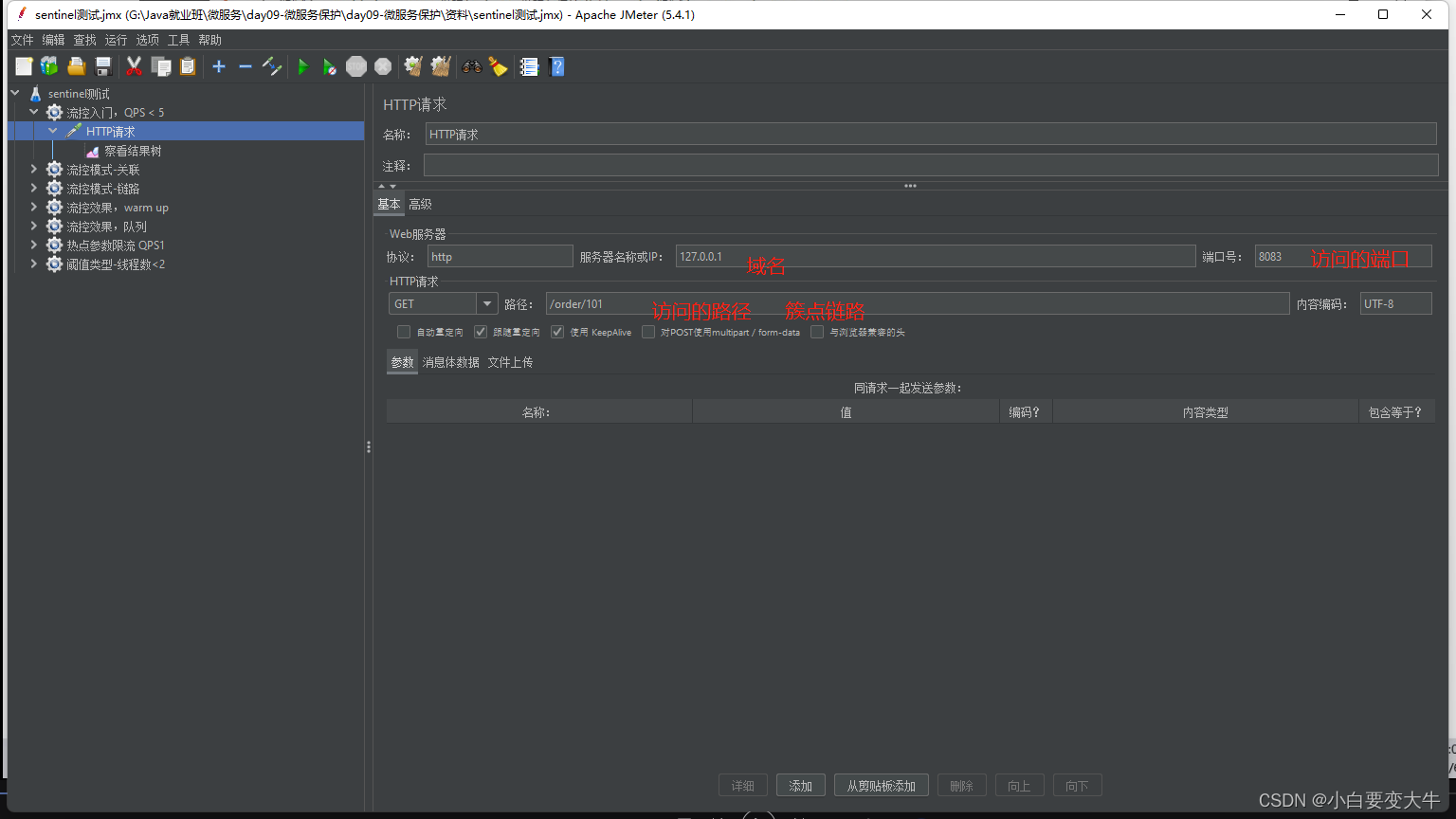
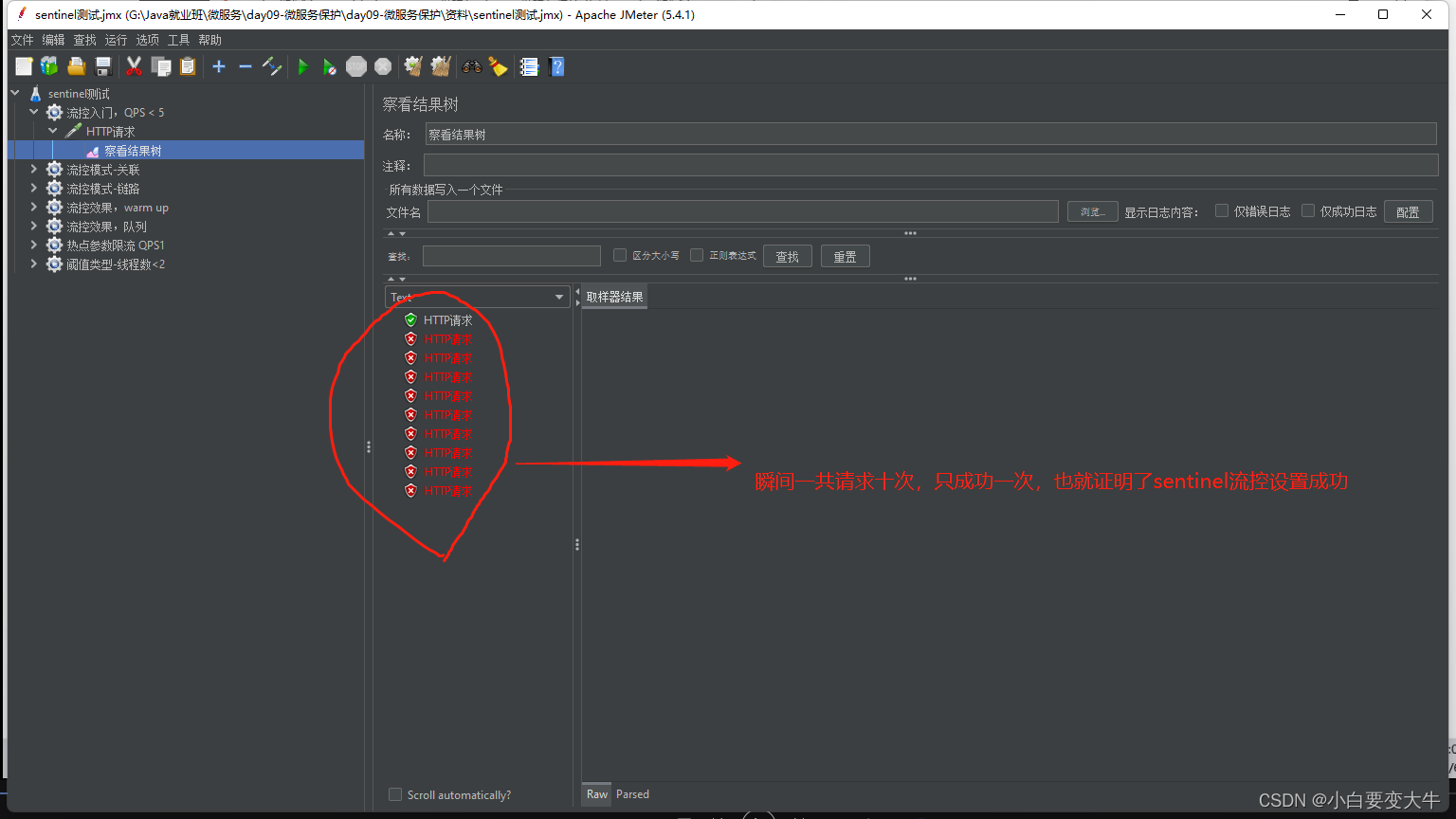
sentinel可视化界面变化:
三种流控模式
直接: 当前资源请求数量达到阈值时,对当前资源做限流,默认也就是直接模式,上边也案例就是直接模式
关联: 统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
链路: 多条链路访问同一个资源,同一个资源达到阈值时,我们可以对其中的某条链路做限流
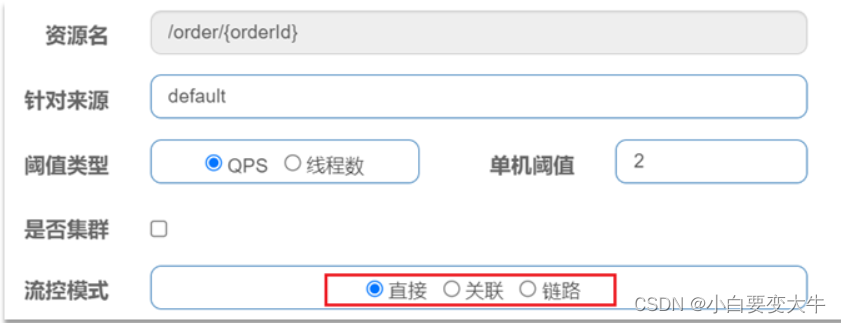
在添加限流规则时,点击高级选项,可以选择三种流控模式:
直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
关联: 统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流,当我们的订单和支付业务两个,加入订单的阈值为5触发,那么同时来了好多线程时,触发了阈值那么订单业务就会被限流。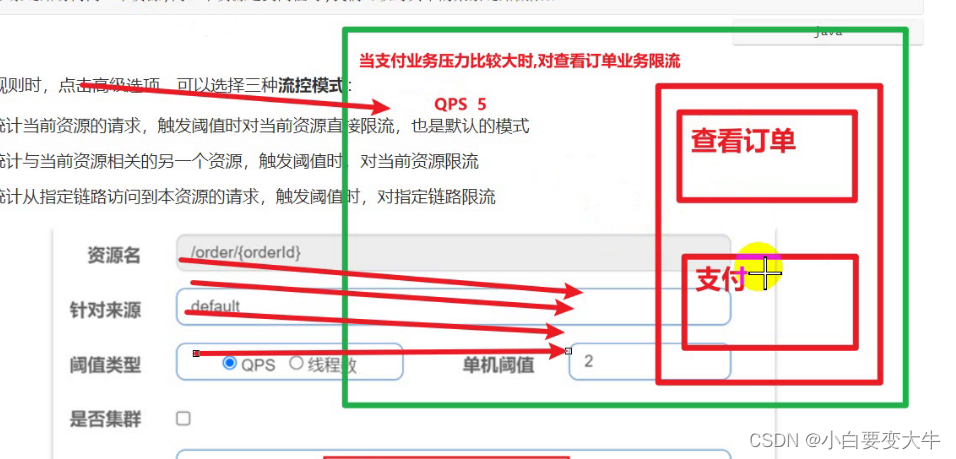
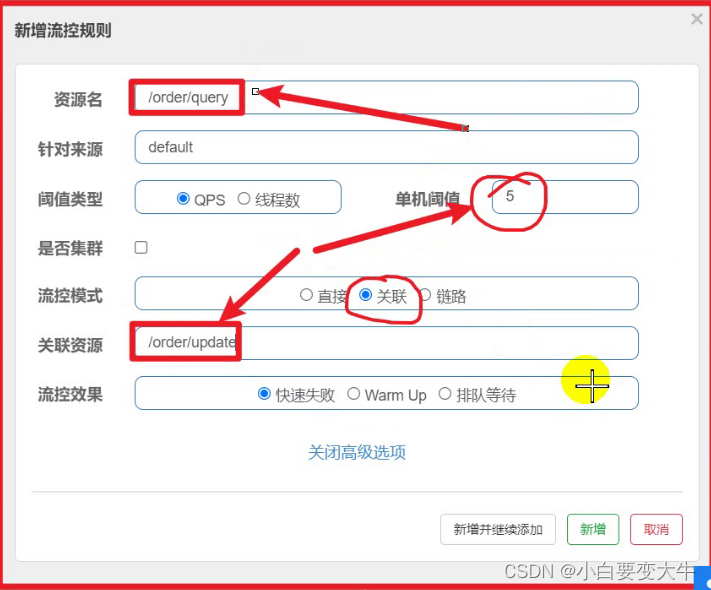
当update线程同时多余5个,就会给query限流
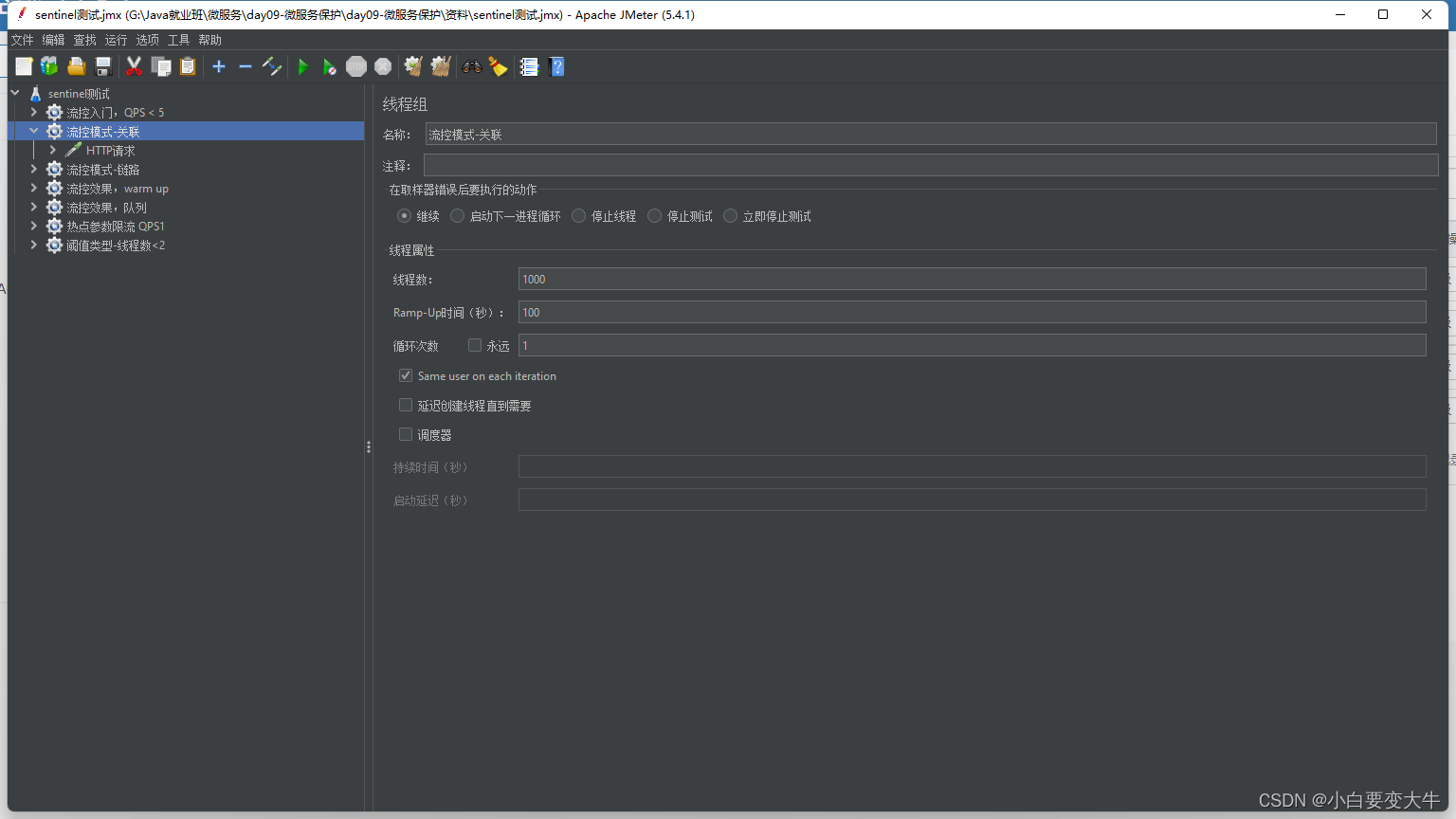
现在请求 update 1000次用100s运行完,那么这是update每s就会出现阈值,这是就会限流query,当我们在请求update的时候再去访问query试一下
结果:
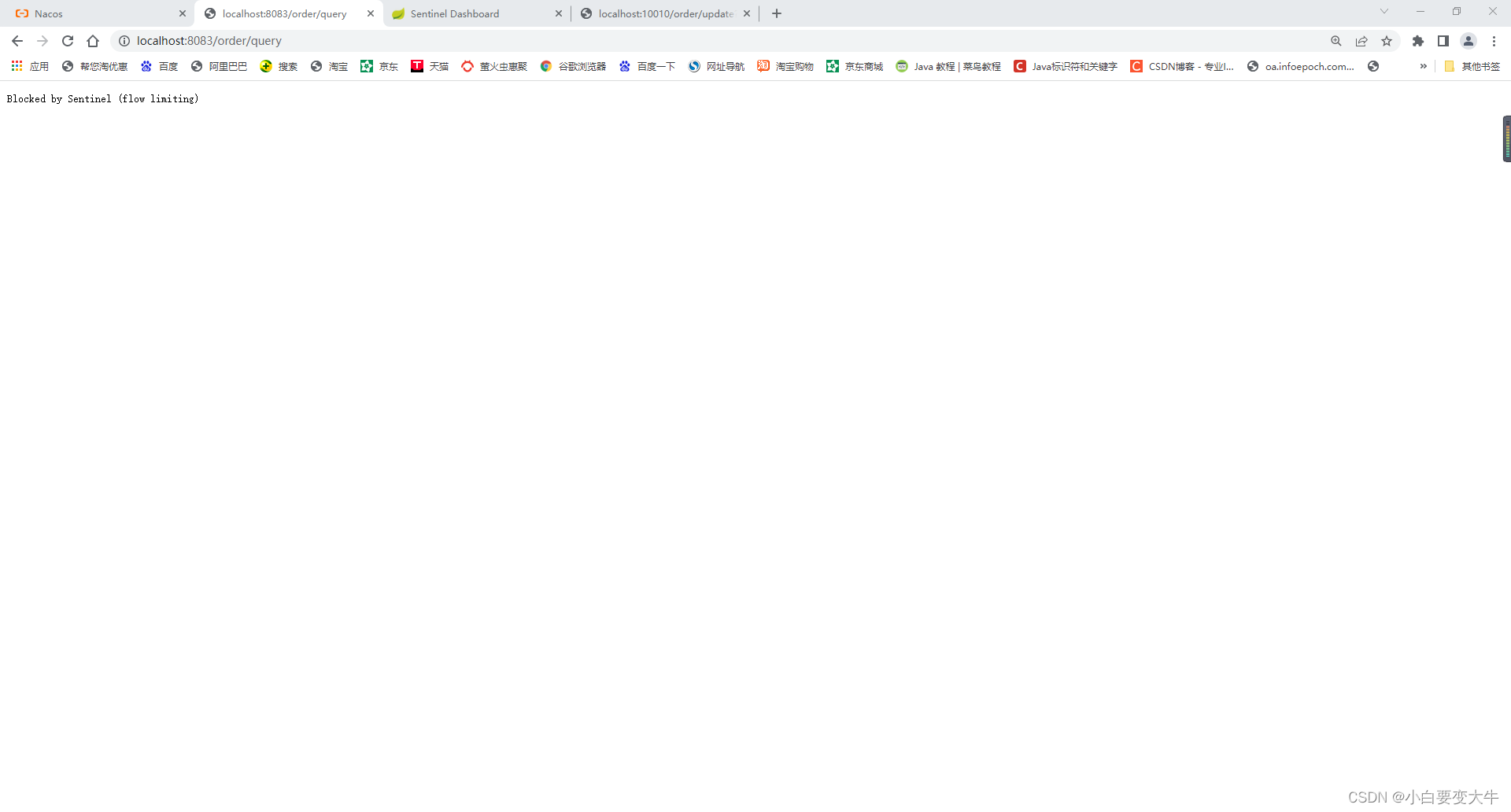
这就是说明query别限流了,访问不成功
链路模式
只针对从指定链路访问到本资源的请求做统计,判断是否超过阈值。
我们的controller 层中有两个接口
orderService.queryGoods();中的代码如下
/**
* Sentinel只能对资源进行流控
* 当前方法是一个普通发放,并非是sentinel资源
* 将方法设置为sentinel的资源
* sentinel资源:
* 1可以被外界访问的路径也就是controller的接口
* 2给方法中添加@SentinelResource("goods")注解,这里的内容随便写,意思就是我们的这个资源的名称,在sentinel的可视化界面就可以看到
*/
@SentinelResource("goods")
public void queryGoods(){
System.err.println("查询商品");
}有查询订单和创建订单业务,两者都需要查询商品。针对从查询订单进入到查询商品的请求统计,并设置限流。
这样我们再次去看链路时界面是这样的:
这样时看着不太容易看出来goods和query和save的关系,我们可以在配置文件中添加这样一个配置
spring:
cloud:
sentinel:
web-context-unify: false # 关闭context整合
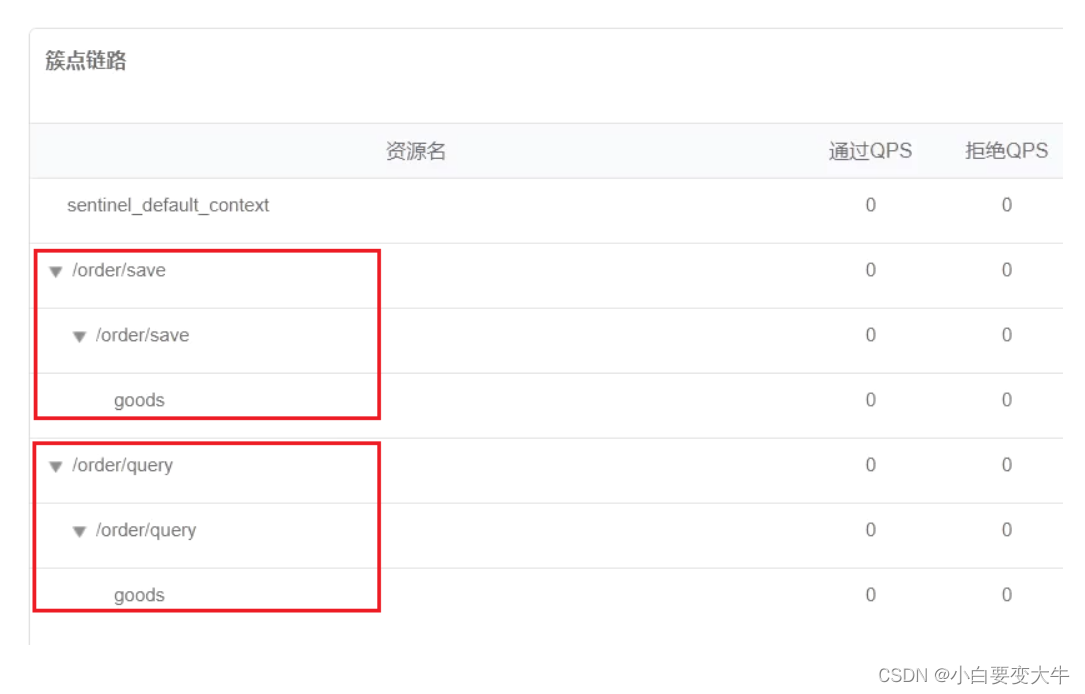
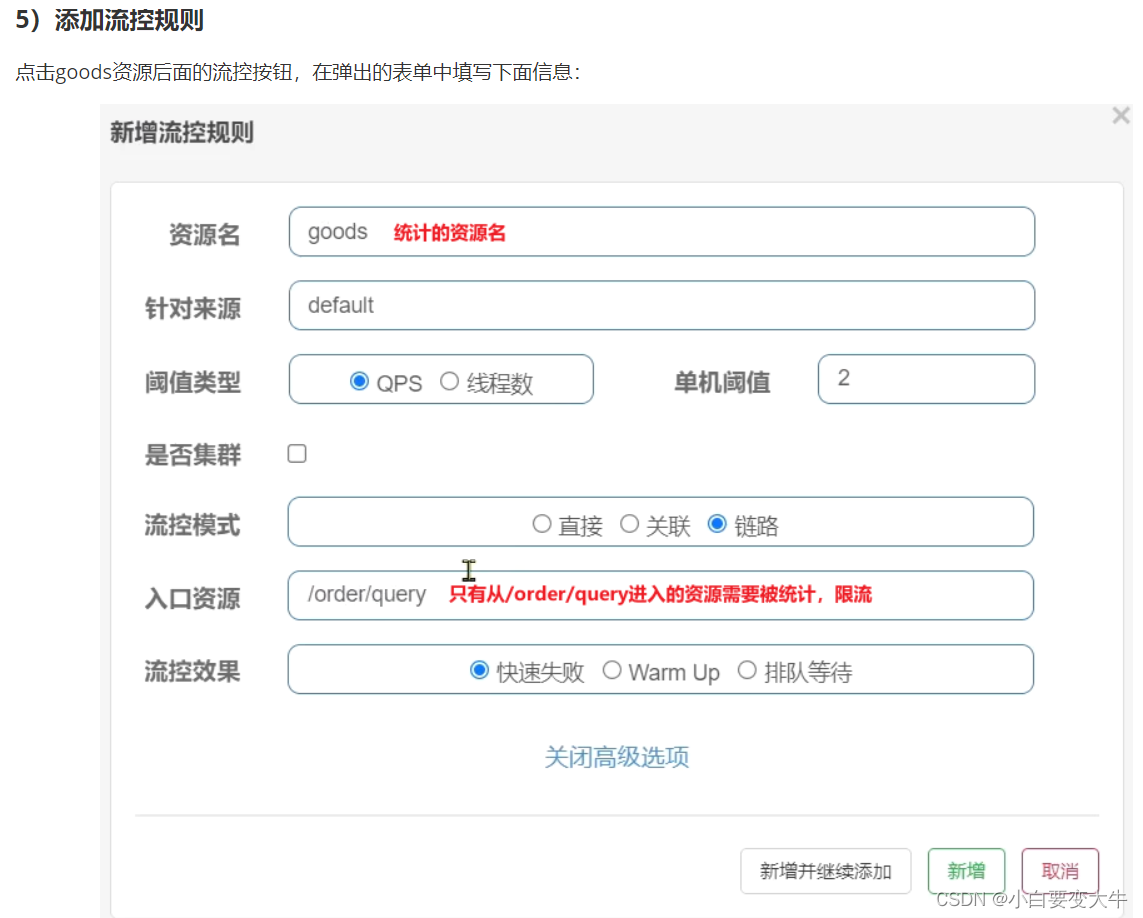
这样也就是说只要是query访问进来请求goods这个资源,那么就会被限流,1s只能处理2个请求
排队等待
当请求超过QPS阈值时,快速失败和warm up 会拒绝新的请求并抛出异常。
而排队等待则是让所有请求进入一个队列中,然后按照阈值允许的时间间隔依次执行。后来的请求必须等待前面执行完成,如果请求预期的等待时间超出最大时长,则会被拒绝。
工作原理
例如:QPS = 5,意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待时长超过2000ms的请求会被拒绝并抛出异常。
那什么叫做预期等待时长呢?
比如现在一下子来了12 个请求,因为每200ms执行一个请求,那么:
第6个请求的预期等待时长 = 200 * (6 - 1) = 1000ms
第12个请求的预期等待时长 = 200 * (12-1) = 2200ms
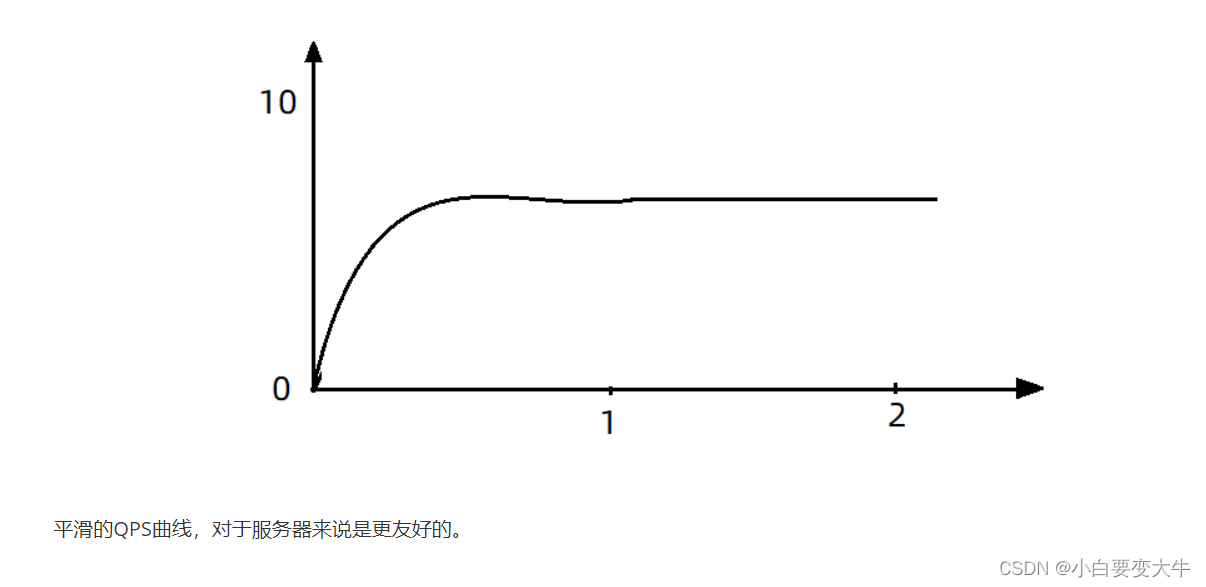
现在,第1秒同时接收到10个请求,但第2秒只有1个请求,此时QPS的曲线这样的:

如果使用队列模式做流控,所有进入的请求都要排队,以固定的200ms的间隔执行,QPS会变的很平滑:
解释:也就是说我们阈值如果是5的话,那么就是一秒处理的请求为5个,这样我们每个请求就需要200ms, 如果同时来了10个请求,那么就需要2000ms,这时候我们后面第是个请求就需要等到1000ms,因为设置了1s只能处理五个,这时候就可以设置一个等待时间,如果后面的请求需要等待时间超过我们设置的这个请求时间那么就直接拒绝请求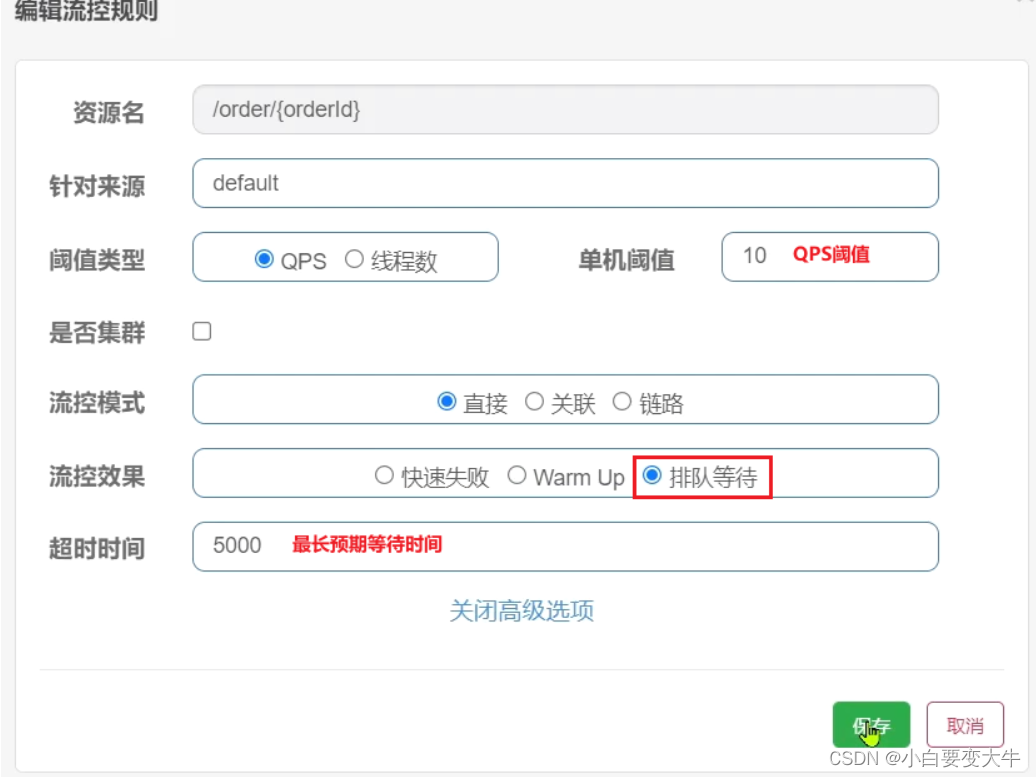
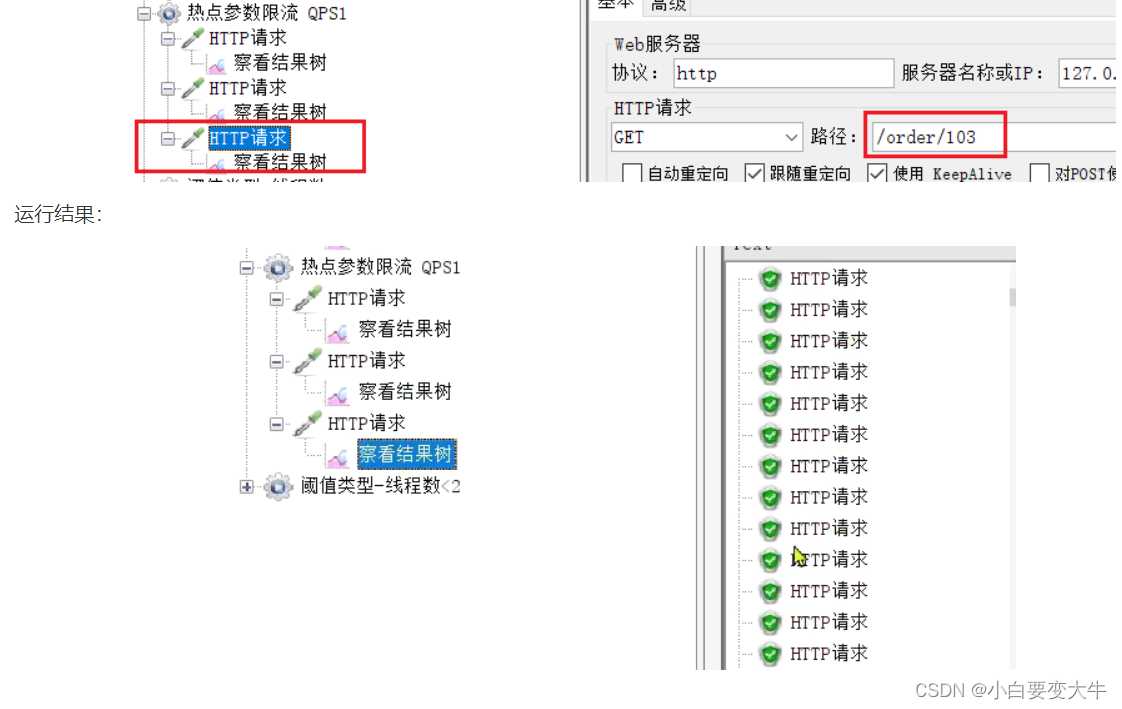
热点参数限流
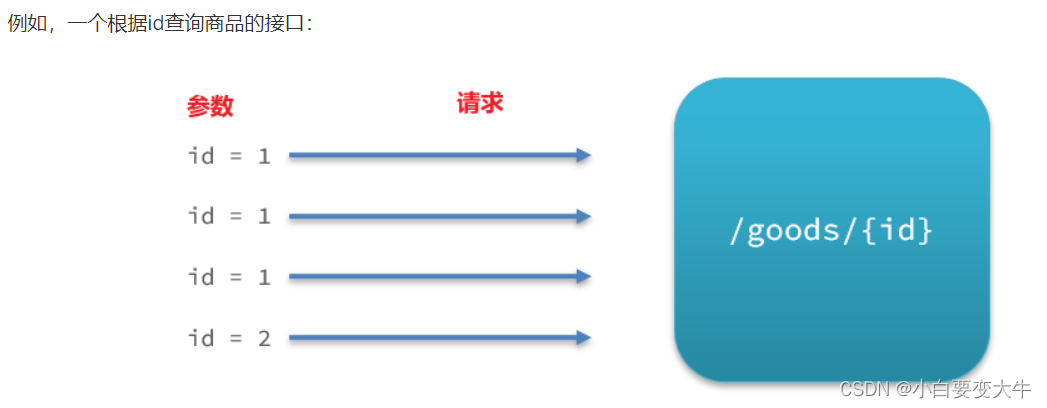
之前的限流是统计访问某个资源的所有请求,判断是否超过QPS阈值。而热点参数限流是分别统计参数值相同的请求,判断是否超过QPS阈值。
就是说我们同一个接口但是我们访问时代的参数是不同的,这时候我们可以对某一个参数进行限流
例如:京东的秒杀茅台,加入茅台的id为1,那么我们很多都会携带id=1去访问这个接口,这时候我们就可以设置id=1的QPS,当请求带的为id=1就限流,当携带的其他参数就不限流,这就是一个例子
使用步骤:
/**
* 使用热点限流时需要将这个接口加上一个注解,里面的hot值时随便设置的,但是可以在sentinel可视化页面看到并且是资源名称
* @param orderId
* @param httpServletRequest
* @return
*/
@SentinelResource("hot")
@GetMapping("{orderId}")
public Order queryOrderByUserId(@PathVariable("orderId") Long orderId, HttpServletRequest httpServletRequest) {
// 根据id查询订单并返回
return orderService.queryOrderById(orderId,httpServletRequest);
}
案例代码:
案例需求:给/order/{orderId}这个资源添加热点参数限流,规则如下:
•默认的热点参数规则是每1秒请求量不超过2
•给102这个参数设置例外:每1秒请求量不超过4
•给103这个参数设置例外:每1秒请求量不超过1
点击左侧菜单中热点规则菜单:
击新增,填写表单:
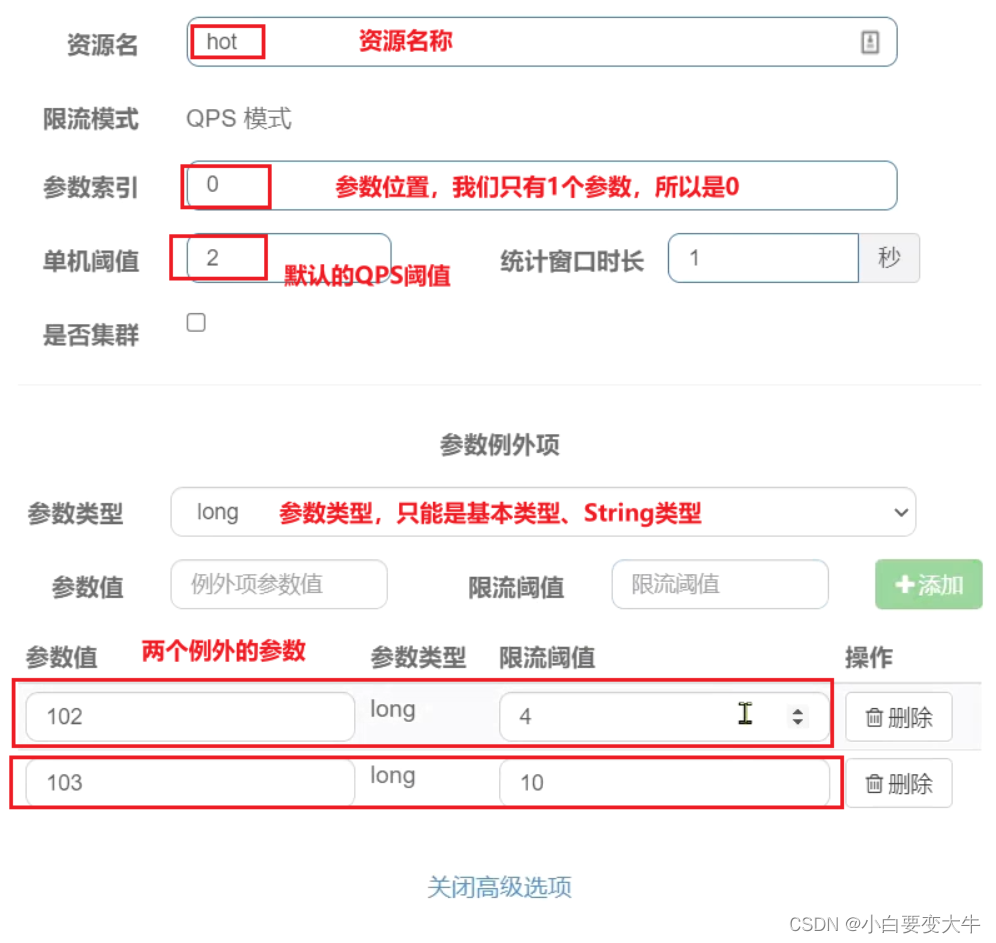
最上边那个单机阈值,在参数例外项中的限流阈值不能超过上边的单机阈值
Jmeter测试
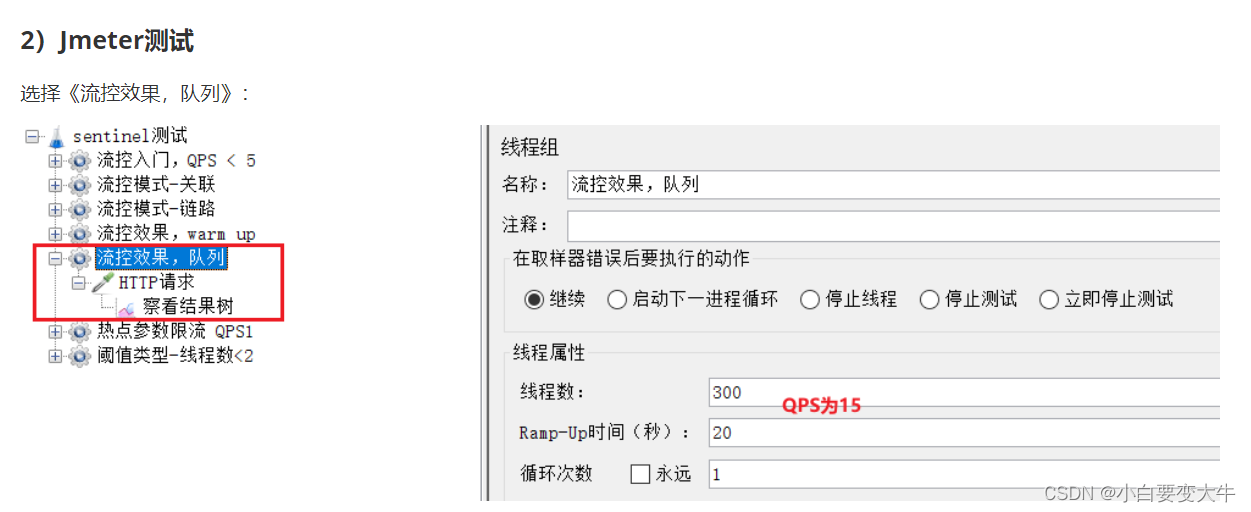
选择《热点参数限流 QPS1》:
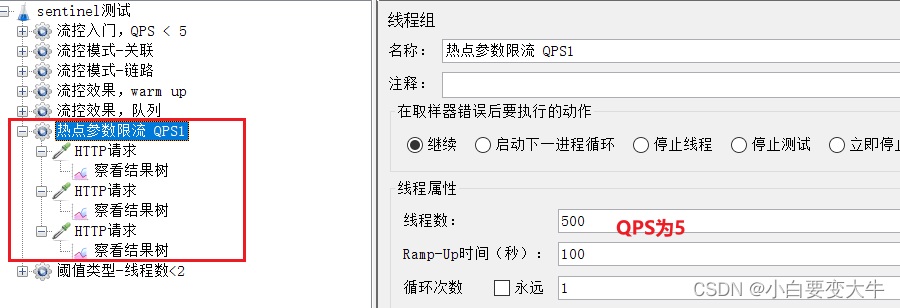
这里发起请求的QPS为5.
包含3个http请求:
普通参数,QPS阈值为2
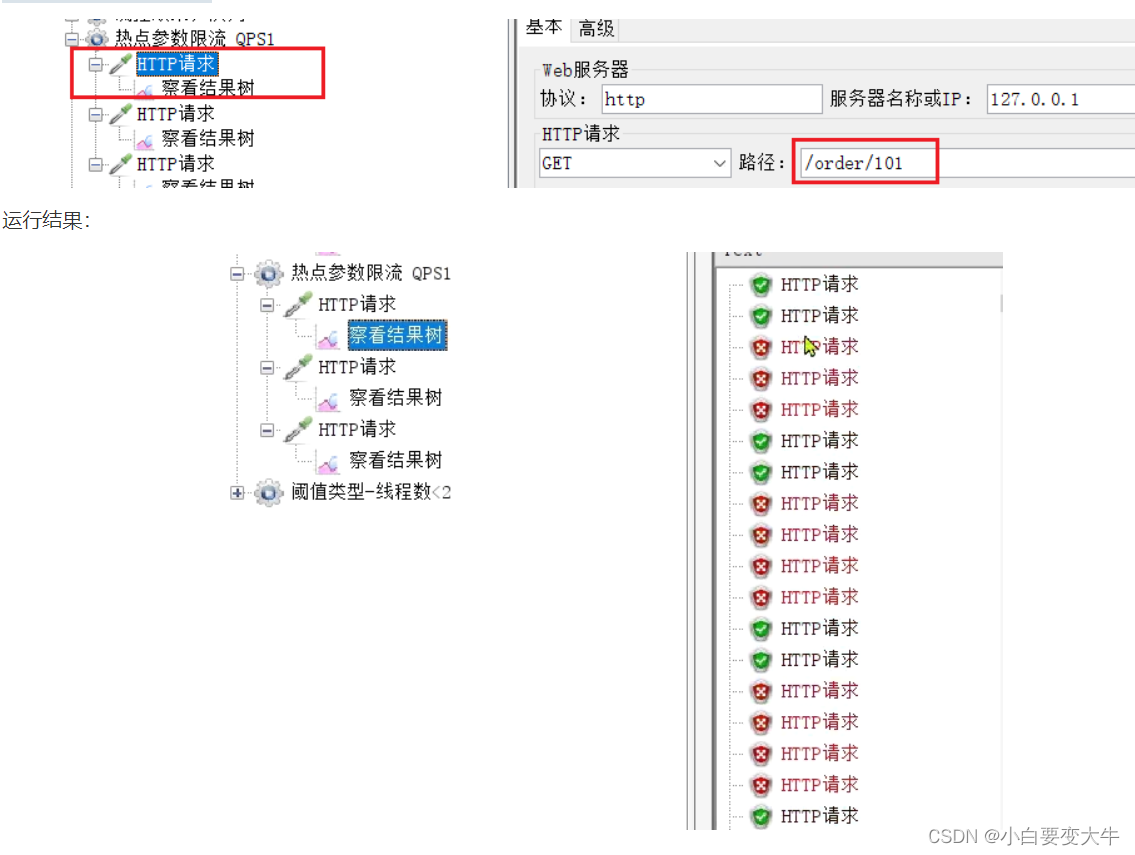
例外项,QPS阈值为4
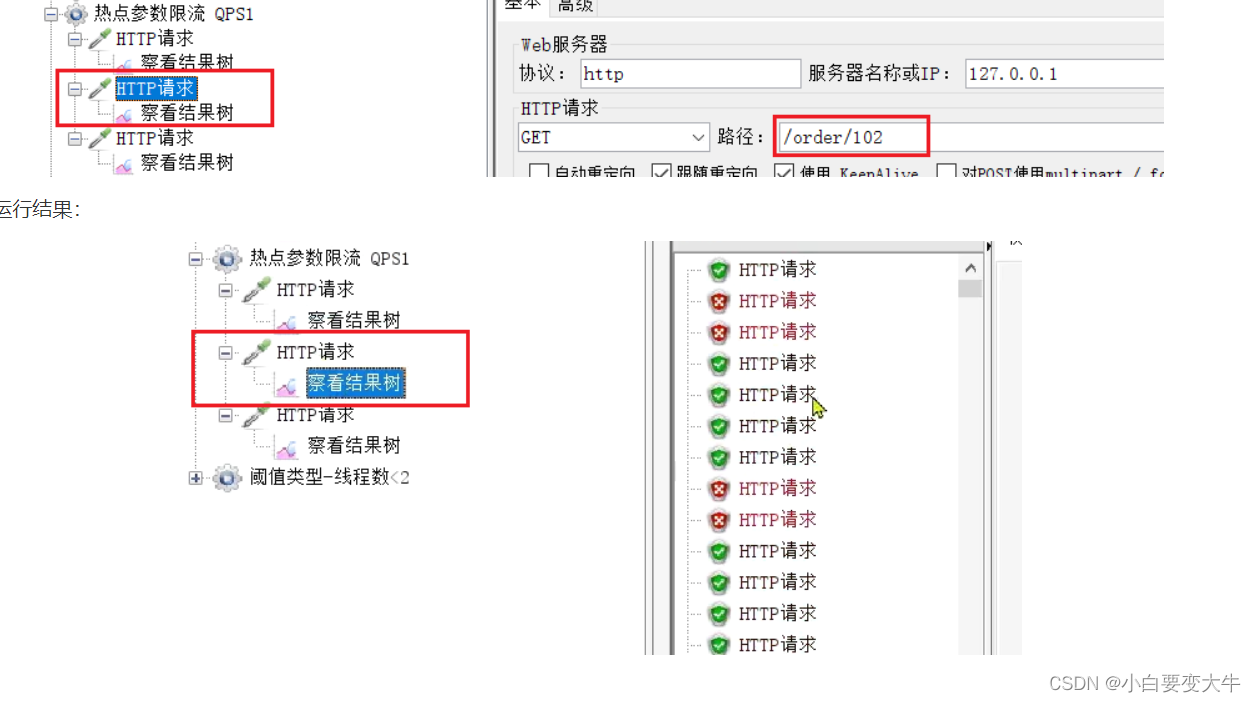
例外项,QPS阈值为10
隔离和降级
限流是一种预防措施,虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。
而要将这些故障控制在一定范围,避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了。
线程隔离:调用者在调用服务提供者时,给每个调用的请求分配独立线程池,出现故障时,最多消耗这个线程池内资源,避免把调用者的所有资源耗尽。
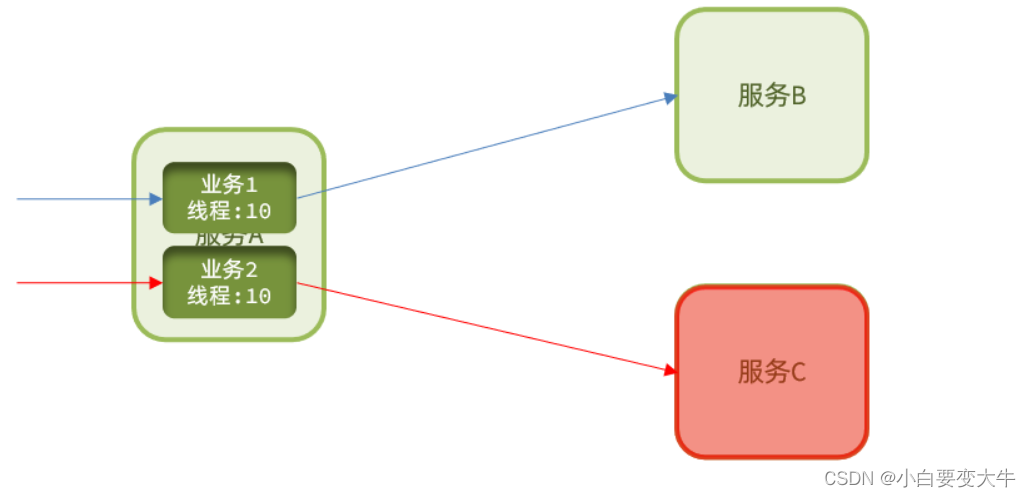
熔断降级:
是在调用方这边加入断路器,统计对服务提供者的调用,如果调用的失败比例过高,则熔断该业务,不允许访问该服务的提供者了。 换一种方式快速处理
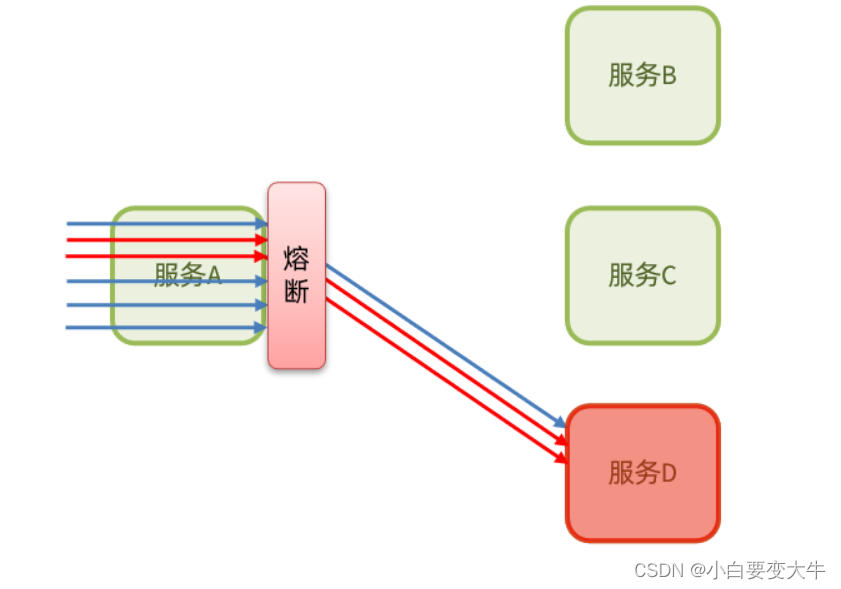
可以看到,不管是线程隔离还是熔断降级,都是对客户端(调用方)的保护。需要在调用方 发起远程调用时做线程隔离、或者服务熔断。
而我们的微服务远程调用都是基于Feign来完成的,因此我们需要将Feign与Sentinel整合,在Feign里面实现线程隔离和服务熔断。
FeignClient整合Sentinel
SpringCloud中,微服务调用都是通过Feign来实现的,因此做客户端保护必须整合Feign和Sentinel。
第一步:
修改OrderService的application.yml文件,开启Feign的Sentinel功能:
feign:
sentinel:
enabled: true # 开启feign对sentinel的支持
步骤儿编写降级方法:
业务失败后,不能直接报错,而应该返回用户一个友好提示或者默认结果,这个就是失败降级逻辑。
给FeignClient编写失败后的降级逻辑
①方式一:FallbackClass,无法对远程调用的异常做处理
②方式二:FallbackFactory,可以对远程调用的异常做处理,我们选择这种
我们使用的是当时二,代码如下
package cn.itcast.order.fallback;
import cn.itcast.order.feign.UserFeignClient;
import cn.itcast.order.pojo.User;
import feign.hystrix.FallbackFactory;
import lombok.extern.slf4j.Slf4j;
/**
* 说明:这个里类实现的FallbackFactory里面的泛型UserFeignClient就是我们的编写的feign的访问路径的接口,
* 这样设置的话,当我们访问到UserFeignClient这个接口中的路径出错需要熔断了,因为UserFeignClient加了fallbackFactory注解指定UserClientFallbackFactory类了
* 所以直接来这里去访问这个类中的实现重写了的访问的路径,也就是说访问UserFeignClient的queryById是出错了需要熔断,就会找UserClientFallbackFactory中
* 重写了queryById的方法
*/
@Slf4j
public class UserClientFallbackFactory implements FallbackFactory<UserFeignClient> {
@Override
public UserFeignClient create(Throwable throwable) {
return new UserFeignClient() {
@Override
public User queryById(Long id) {
log.info("查询用户异常");
User user = new User();
user.setUsername("查询用户异常");
System.out.println("user = " + user);
return user;
}
};
}
}
第三步:将UserClientFallbackFactory 加到IOC容器中
@Bean
public UserClientFallbackFactory userClientFallbackFactory(){
return new UserClientFallbackFactory();
}或者直接在UserClientFallbackFactory上边写一个@Component
第三步:
在我们的正常访问的那个UserClient接口上添加注解指定UserClientFallbackFactory类,这样正常的UserClient需要熔断降级了就可以直接去找到UserClientFallbackFactory类
//加的就是fallbackFactory = UserClientFallbackFactory.class
@FeignClient(value = "userservice", fallbackFactory = UserClientFallbackFactory.class)
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}然后重启我们的服务就会发现出现了链接也就是簇点链路
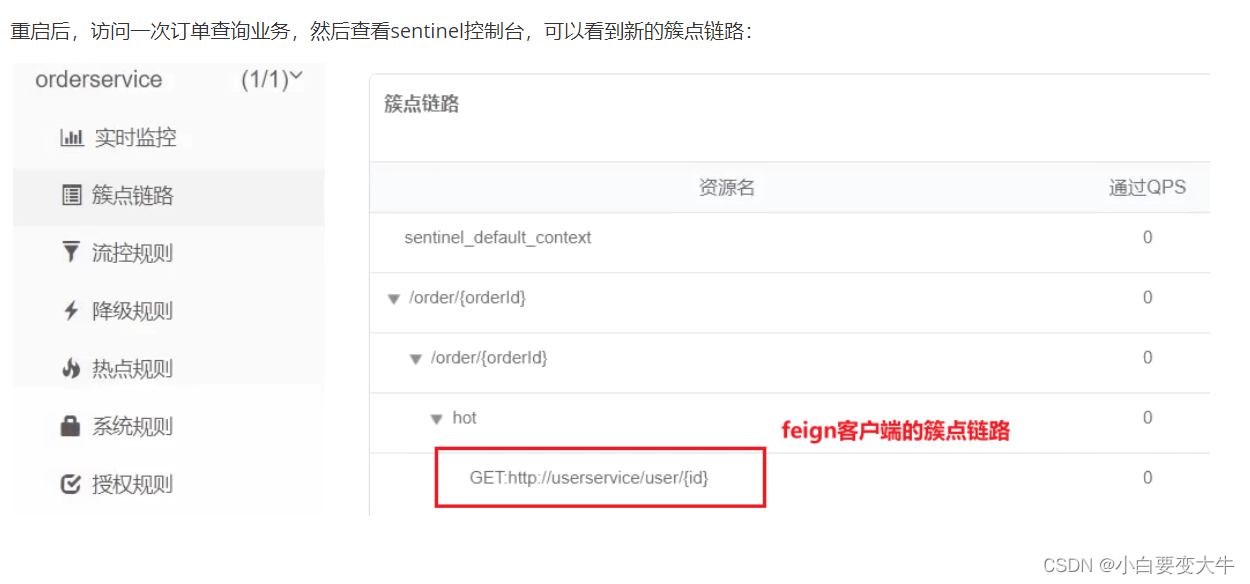
线程隔离
线程隔离有两种方式实现:
线程池隔离
信号量隔离(Sentinel默认采用)
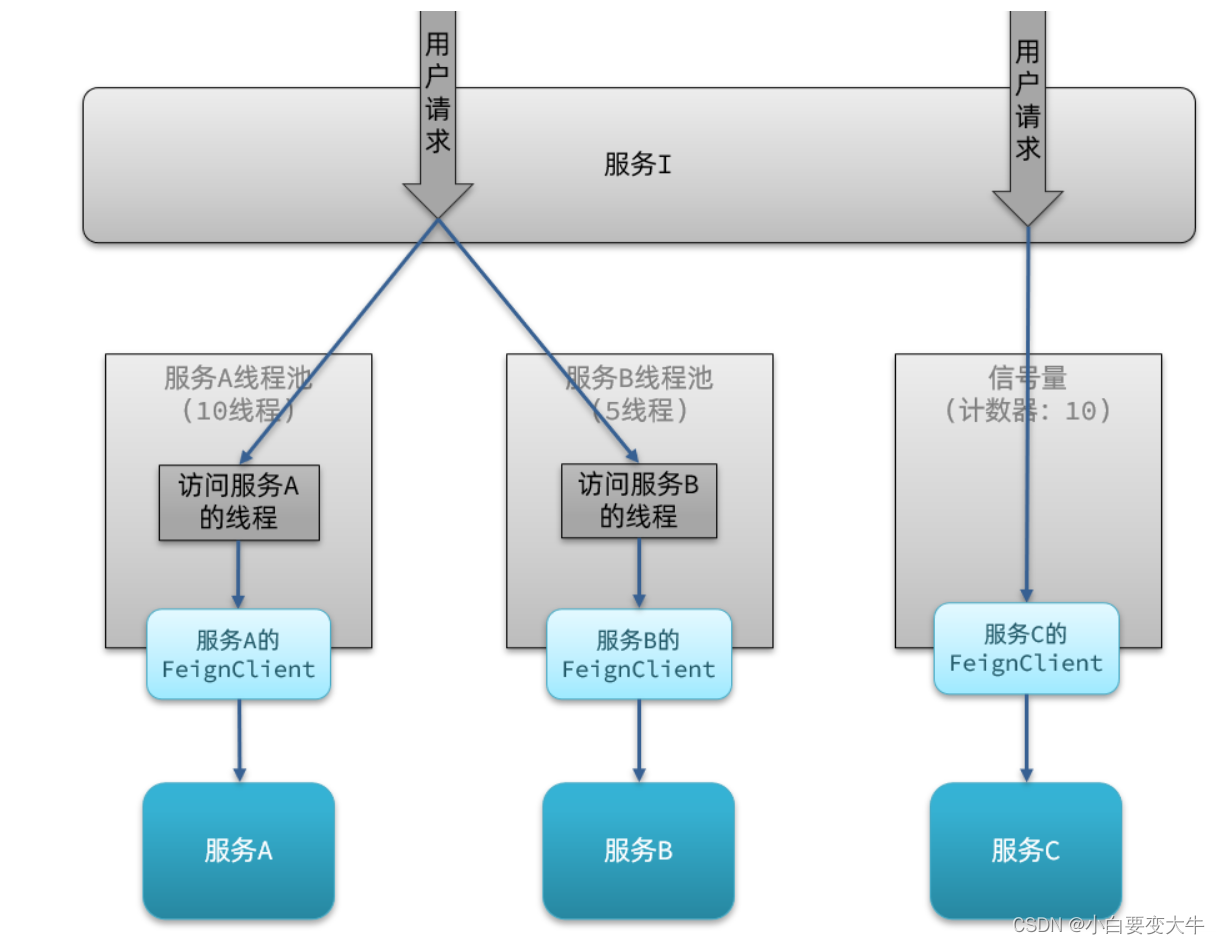
线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果
信号量隔离:不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求。
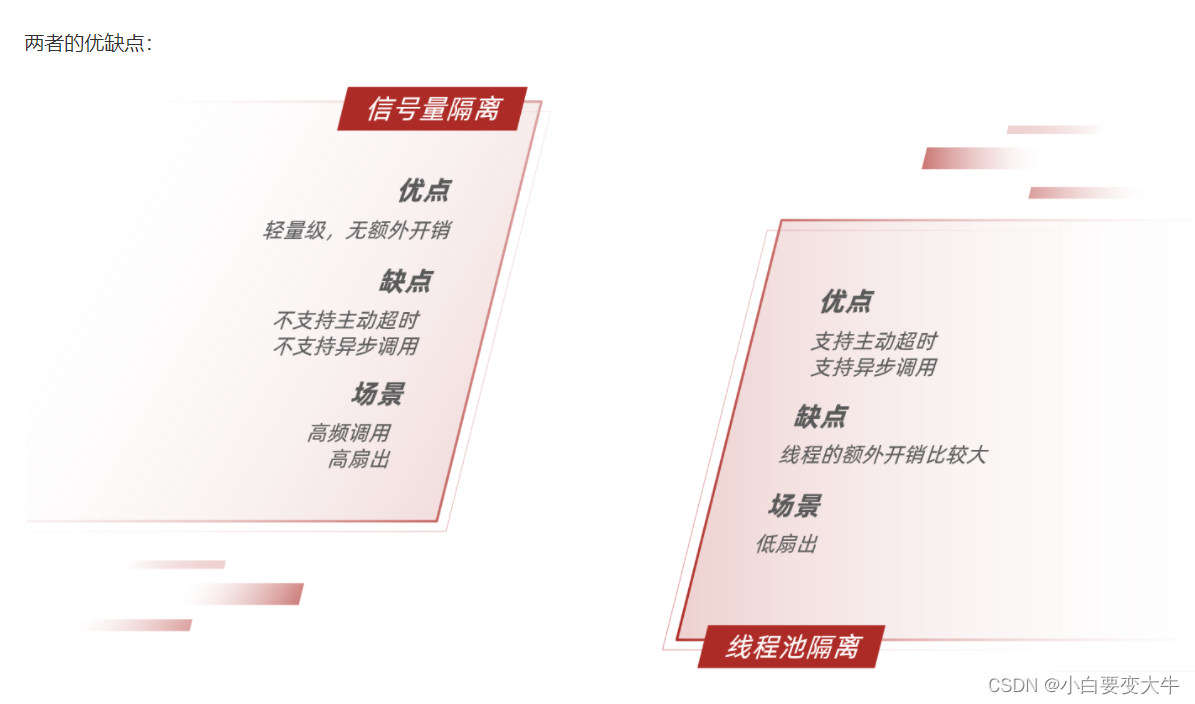
sentinel的线程隔离和使用步骤
sentinel默认线程隔离 方式就是信号量隔离
使用步骤
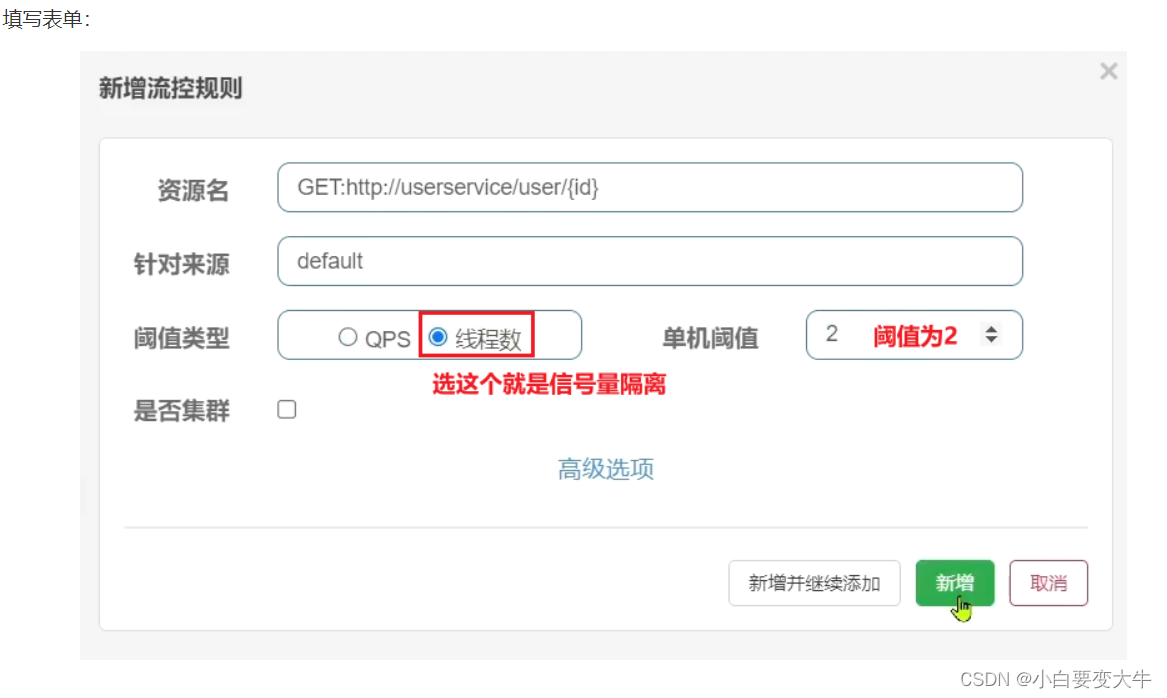
1选择feign接口后面的流控按钮:

填写表单
熔断降级
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
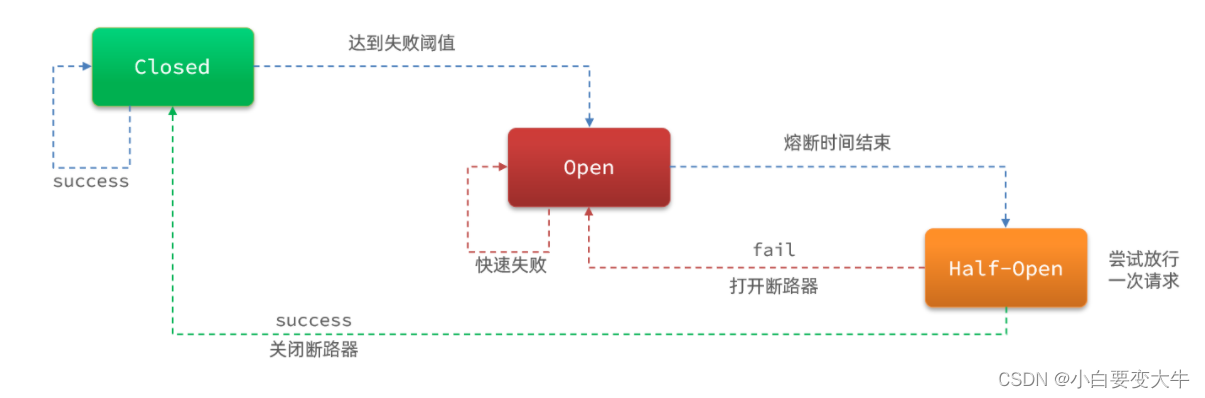
状态机包括三个状态:
-
closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
-
open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态5秒后会进入half-open状态
-
half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
-
请求成功:则切换到closed状态
-
请求失败:则切换到open状态
-
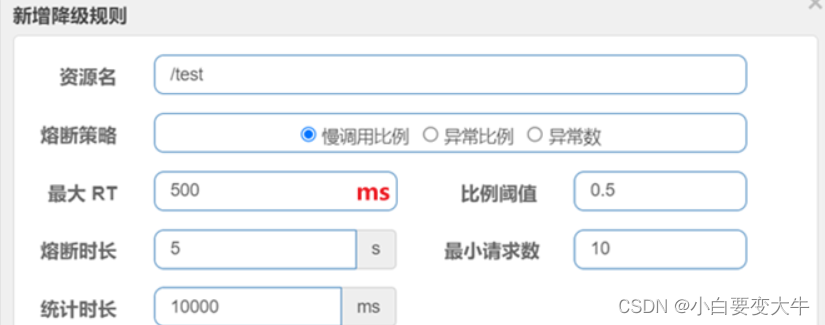
断路器熔断策略有三种:慢调用、异常比例、异常数
1.慢调用
慢调用:业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。
异常比例、异常数
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
例如,一个异常比例设置:
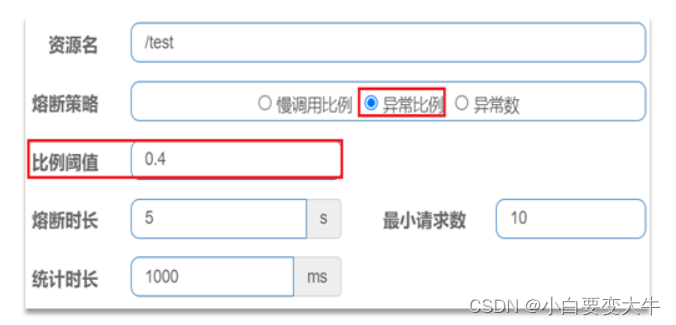
解读:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于0.4,则触发熔断。
一个异常数设置:
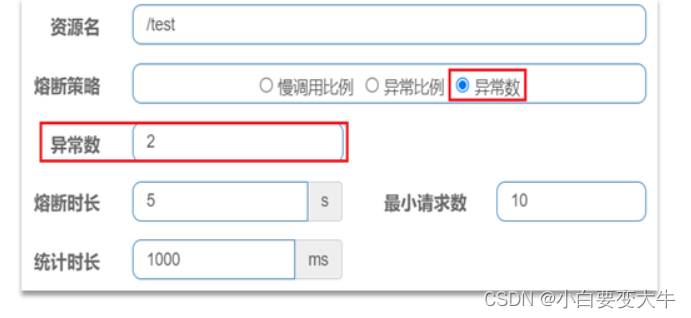
解读:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于2次,则触发熔断。
授权规则
授权规则可以对调用方的来源做控制,有白名单和黑名单两种方式。
-
白名单:来源(origin)在白名单内的调用者允许访问
-
黑名单:来源(origin)在黑名单内的调用者不允许访问
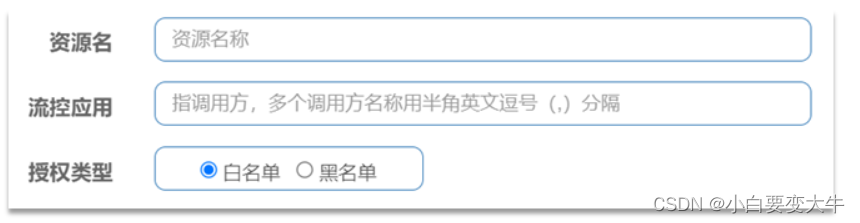
点击左侧菜单的授权,可以看到授权规则:
-
资源名:就是受保护的资源,例如/order/{orderId}
-
流控应用:是来源者的名单,
-
如果是勾选白名单,则名单中的来源被许可访问。
-
如果是勾选黑名单,则名单中的来源被禁止访问。
-
Sentinel是通过RequestOriginParser这个接口的parseOrigin来获取请求的来源的。
默认情况下,sentinel不管请求者从哪里来,返回值永远是default,也就是说一切请求的来源都被认为是一样的值default。
因此,我们需要自定义这个接口的实现,让不同的请求,返回不同的origin。
例如order-service服务中,我们定义一个RequestOriginParser的实现类:
@Component
public class HeaderOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest request) {
// 1.获取请求头
String origin = request.getHeader("origin");
// 2.非空判断
if (StringUtils.isEmpty(origin)) {
origin = "blank";
}
return origin;
}
}
规则持久化
现在,sentinel的所有规则都是内存存储,重启后所有规则都会丢失。在生产环境下,我们必须确保这些规则的持久化,避免丢失。
规则是否能持久化,取决于规则管理模式,sentinel支持三种规则管理模式:
-
原始模式:Sentinel的默认模式,将规则保存在内存,重启服务会丢失。
-
pull模式
-
push模式
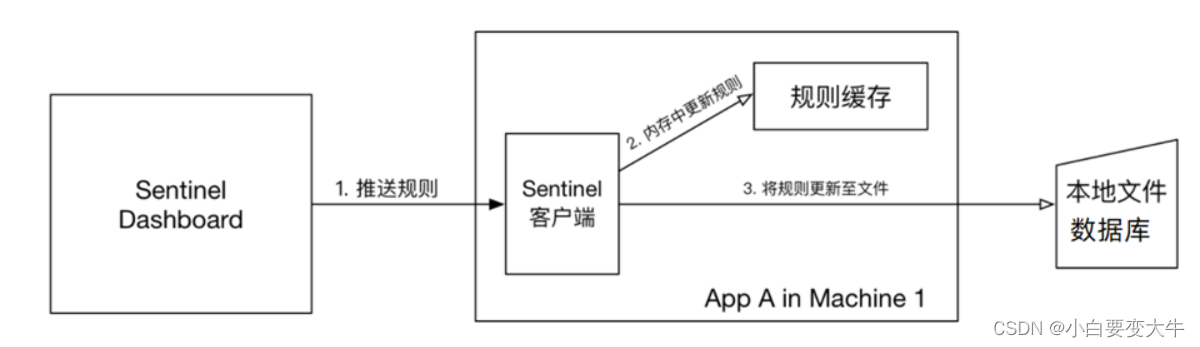
pull模式:控制台将配置的规则推送到Sentinel客户端,而客户端会将配置规则保存在本地文件或数据库中。以后会定时去本地文件或数据库中查询,更新本地规则。
如果有很多集群那么配置相对麻烦
.push模式
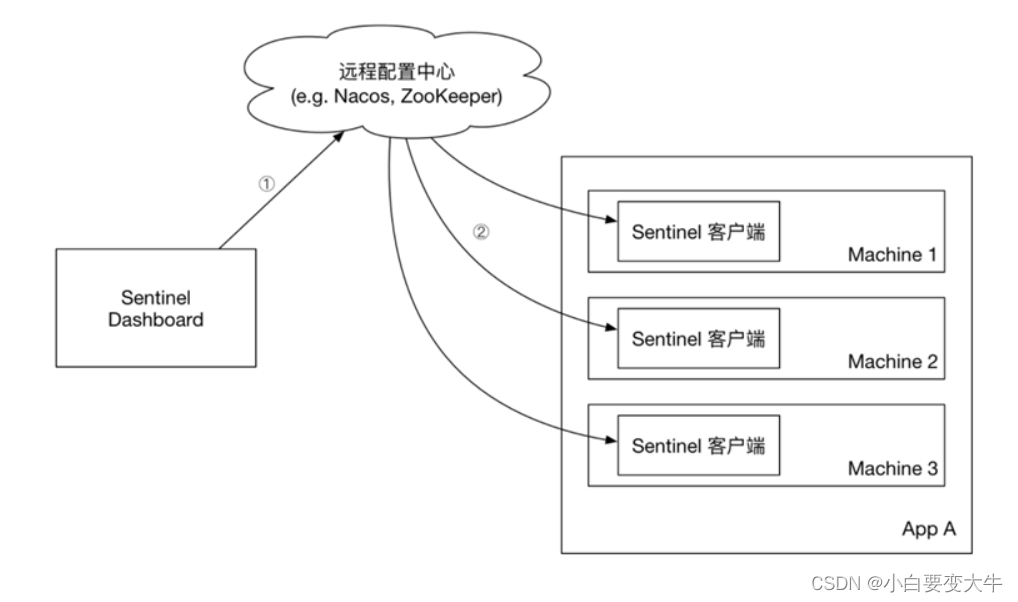
push模式:控制台将配置规则推送到远程配置中心,例如Nacos。Sentinel客户端监听Nacos,获取配置变更的推送消息,完成本地配置更新。















 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









