







 本文介绍了时序数据库InfluxDB的原理与应用,特别是InfluxDB 2.0的特性。内容涵盖InfluxDB的基础知识、TICK架构、存储原理,以及通过Telegraf进行系统监控和Jmeter搭建性能监控环境的实践。InfluxDB的TSM存储引擎确保高并发写入和高效查询,适用于DevOps监控、IoT等领域。
本文介绍了时序数据库InfluxDB的原理与应用,特别是InfluxDB 2.0的特性。内容涵盖InfluxDB的基础知识、TICK架构、存储原理,以及通过Telegraf进行系统监控和Jmeter搭建性能监控环境的实践。InfluxDB的TSM存储引擎确保高并发写入和高效查询,适用于DevOps监控、IoT等领域。
什么是时序数据库
时序数据库,全称时间序列数据库(Time Series Database,TSDB),用于存储大量基于时间的数据,时序数据(Time Series Data)指的是一系列基于时间的数据,例如CPU利用率,北京的房价变化趋势,某一地区的温度变化等。
时序数据库支持时序数据的快速写入、持久化,多维度查询、聚合等操作,同时可以记录所有的历史数据,查询时将时间作为数据的过滤条件。
时序数据的使用场景广泛,包括DevOps监控,应用程序指标,IoT传感器数据,实时动态数据分析等场景。
1
初识InfluxDB
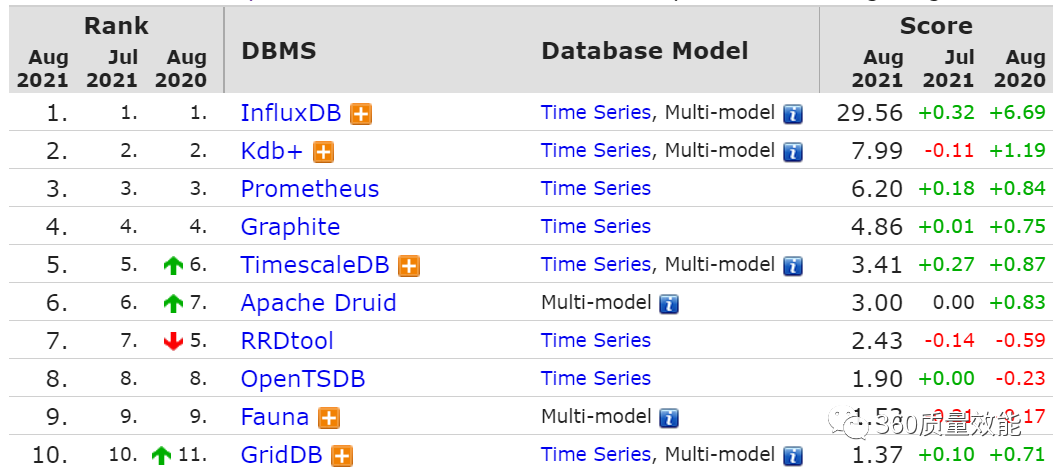
InfluxDB是时序数据库中应用比较广泛的一种,在DB-Engines TSDB rank中位居首位,可见InfluxDB在互联网的受欢迎程度是非常高的。下图是截止到2021年8月时序数据库的排名情况。

它是go语言开发的数据库,InfluxDB自发布至今,已经有两个版本,InfluxDB1.x系列提供一种类似SQL的查询语言InfluxQL,用于数据交互。2019年1月新推出的influxDB2.0 alpha版本,主推全新的查询语言Flux,支持TICK架构。在 2020 年底推出InfluxDB 2.0 正式版本,该版本又分为InfluxDB Cloud 和 InfluxDB OSS两个系列。
时序数据库与我们熟悉的关系型数据库有所不同,首先需要了解一下InfluxDB中字段的含义,如下图所示:

2
TICK架构分析与各组件功能介绍
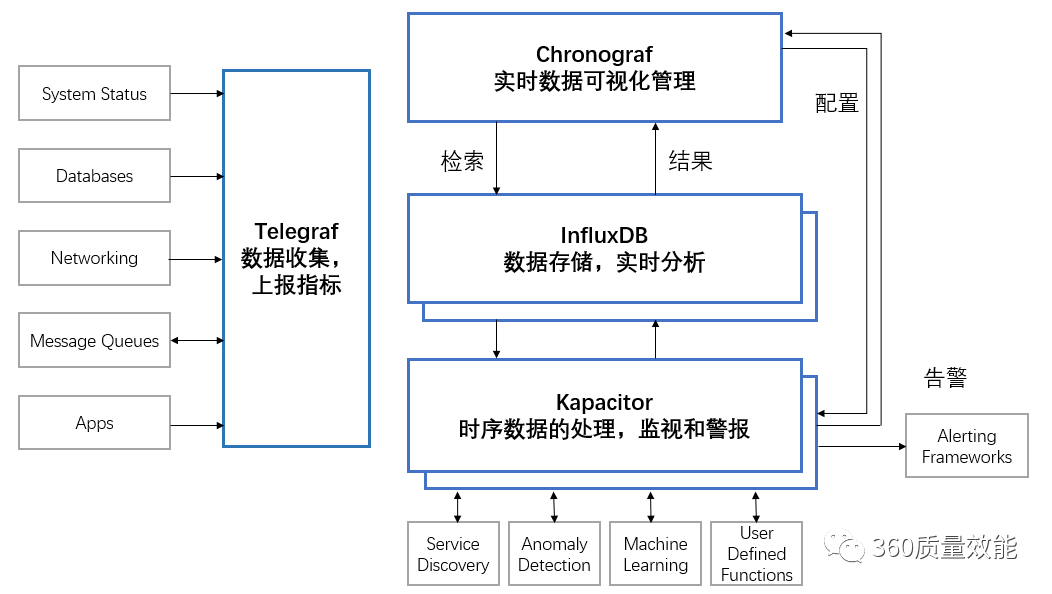
TICK架构 是 InfluxData 平台的组件的集合首字母缩写,该集合包括Telegraf、InfluxDB、Chronograf和 Kapacitor。TICK架构以及各组件分工情况如图所示:

除了上图可视化管理工具Chronograf外,还有一种可视化工具Grafana,它也是用于大规模指标数据的可视化展示,提供包括折线图,饼图,仪表盘等多种监控数据可视化UI,若应用过程中考虑到扩展性问题,也会使用Grafana代替Chronograf。
3
InfluxDB的特点
● 数据写入:
①. 高并发高吞吐,可持续的数据写入。
②. 写多读少,时序数据95%以上都是写操作,例如在监控系统数据的时候,监控数据特别多,但是通常只会关注几个关键指标。
③. 数据实时写入,不支持数据更新,但是可以人为更新修改。
● 数据分析与查询:
①. 数据查询是按照时间段读取,例如1小时,1分钟,给出具体时间范围。
②. 最近的数据读取率高,越旧的数据读取率越低。
③. 多种精度查询和多种维度分析。
● 数据存储:
①. 存储数据规模大的数据,监控数据的数据大多数情况下都是TB或者PB级。
②. 数据存放具有时效性,InfluxDB提供了保存策略,可以认为是数据的保质期,超过周期范围,就可以认为数据失效,需要回收。节约存储成本,清理低价值的数据。
4
InfluxDB存储原理
InfluxDB的存储
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7939
7939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}