







我们上一篇聊到了 jQuery 中的无 new 构造,我们发现其真正的初始化操作是放在 new jQuery.fn.init( selector, context );里面的,今天我们就来看看这个 init() 函数的具体内容;
jQuery 的源码中是这么定义的:
init = jQuery.fn.init = function( selector, context, root ) {
var match, elem;
// HANDLE: $(""), $(null), $(undefined), $(false)
if ( !selector ) {
return this;
}
// Method init() accepts an alternate rootjQuery
// so migrate can support jQuery.sub (gh-2101)
root = root || rootjQuery;
// Handle HTML strings
if ( typeof selector === "string" ) {
if ( selector[ 0 ] === "<" &&
selector[ selector.length - 1 ] === ">" &&
selector.length >= 3 ) {
// Assume that strings that start and end with <> are HTML and skip the regex check
match = [ null, selector, null ];
} else {
match = rquickExpr.exec( selector );
}
// Match html or make sure no context is specified for #id
if ( match && ( match[ 1 ] || !context ) ) {
// HANDLE: $(html) -> $(array)
if ( match[ 1 ] ) {
context = context instanceof jQuery ? context[ 0 ] : context;
// Option to run scripts is true for back-compat
// Intentionally let the error be thrown if parseHTML is not present
jQuery.merge( this, jQuery.parseHTML(
match[ 1 ],
context && context.nodeType ? context.ownerDocument || context : document,
true
) );
// HANDLE: $(html, props)
if ( rsingleTag.test( match[ 1 ] ) && jQuery.isPlainObject( context ) ) {
for ( match in context ) {
// Properties of context are called as methods if possible
if ( jQuery.isFunction( this[ match ] ) ) {
this[ match ]( context[ match ] );
// ...and otherwise set as attributes
} else {
this.attr( match, context[ match ] );
}
}
}
return this;
// HANDLE: $(#id)
} else {
elem = document.getElementById( match[ 2 ] );
if ( elem ) {
// Inject the element directly into the jQuery object
this[ 0 ] = elem;
this.length = 1;
}
return this;
}
// HANDLE: $(expr, $(...))
} else if ( !context || context.jquery ) {
return ( context || root ).find( selector );
// HANDLE: $(expr, context)
// (which is just equivalent to: $(context).find(expr)
} else {
return this.constructor( context ).find( selector );
}
// HANDLE: $(DOMElement)
} else if ( selector.nodeType ) {
this[ 0 ] = selector;
this.length = 1;
return this;
// HANDLE: $(function)
// Shortcut for document ready
} else if ( jQuery.isFunction( selector ) ) {
return root.ready !== undefined ?
root.ready( selector ) :
// Execute immediately if ready is not present
selector( jQuery );
}
return jQuery.makeArray( selector, this );
};我们来分析一下这一段代码,
首先定义了 match 和 elem 两个变量, 接着进行一个判断,这个判断作用注释也写的很清楚,主要是过滤$(""), $(null), $(undefined), $(false)这种不符合规则的选择,如果成立,就直接返回(此时返回的是空的 jq 对象)~
root = root || rootjQuery; 接着对 root 赋值 , 因为源码中有 rootjQuery = jQuery( document ); 这么一句, 所以此时的 root 也就是 document 对象。
如果我们输入合法,那么就走下面的判断,判断字符串里面的内容比较多,我们先看字符串以外的部分,
第一个判断就是
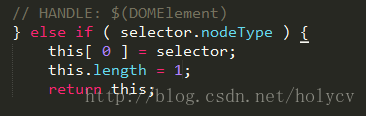
这个判断主要是针对 DOM 元素 , 比如 我们平时用的 $(document) , $(body) 这种类型的选择 ,因为DOM 元素 nodeType节点类型一定是存在的,利用是否有nodeType属性来判断是否是DOM元素 ,如果正确就赋给 this 对象 并将其返回。
如果还不是 DOM 元素呢 , 那么就会 进入下面这个判断
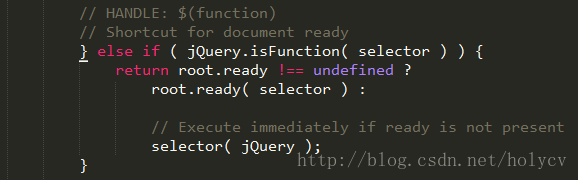
这个判断是用来判断,如果我们传入的是一个 function 类型的时候,其主要是处理我们 平时这么写的一种文档加载完成的方式——$(function(){}),其实这种写法最终还是走到了 $(document).ready(function(){})里面来,如果 ready 函数存在 , 那么直接放在 $(document).ready() 中等待执行,如果没有 ready 函数那么直接执行(一般引入了 jQuery 的话 ready函数是存在的);
如果以上条件都不是 , 那么传入的就是一个 DOM 类数组,也就是$(document.getElementsByTagName('li')) 类似这种形式 , 直接合并到当前 jQuery 对象将其返回, 对应源码中最后 return jQuery.makeArray( selector, this );
ok,我们接下来仔细看看 jQuery 处理各种各样的字符串 类型 ,
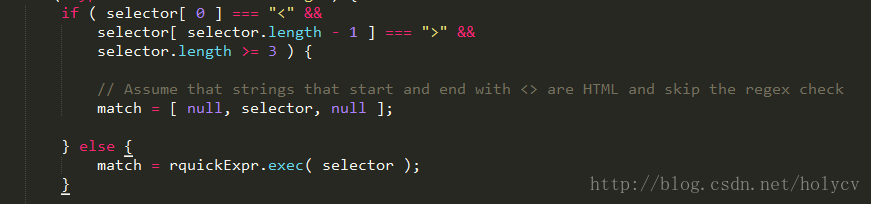
先来一个判断,判断当前字符串 是不是 符合 第一个字符是 ‘<’ , 最后一个字符是 ‘>’ , 而且字符串总长度大于等于 3 , 也就是处理我们常用的 HTML 单标签 类型($('<div>') , $('<a>') 等) , 我们将标签 放到 match 这个变量的 第二个 位置上;
如果不符合条件,就将 rquickExpr.exec( selector ); 的执行结果赋给 match , 那我们先看看这个 rquickExpr 正则表达式,源码中是这么定义的
rquickExpr = /^(?:\s*(<[\w\W]+>)[^>]*|#([\w-]+))$/这个正则是匹配 <tag>text, <tag>text</tag>text 或 #id 文本, 也就是$("htmlText")和$("#id")用法 的字符(ps:这个正则还防止了 XSS 通过哈希注入, 感兴趣的同学可以去了解一下 ~)
那么正则返回什么呢,我们做个测试,
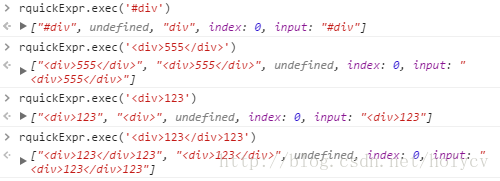
我们发现使用exec方法后,如果匹配到了,则应该返回一个长度为3,包括 index 和 input 属性的数组。
那么match[0]是整体匹配的数组,match[1]是匹配的<tag>标签(如果有),match[2]匹配#id(如果有),并且 match[1],match[2]只能有一个被捕获~
如果匹配的字符串是 htmlText 标签 ,也就是 $('<div>123</div>') 或者 $('<div>123') 这种情况的话,那么 jQuery 会根据html生成dom元素,返回 jQuery 对象;
context = context instanceof jQuery ? context[0] : context;如果context是jQuery对象,那么就采用 context[0] 将其转为js原生对象 , 在这里context期待传入的就是document 或者 $(document);
接着执行调用了 jQuery.parseHTML 方法,该方法就是把 htmlString 转为 dom 数组
jQuery.merge( this, jQuery.parseHTML(
match[ 1 ],
context && context.nodeType ? context.ownerDocument || context : document,
true
) );还调用了jQuery.merge( first , second ),这个方法接收两个”类数组”参数,并把第二个数组追加到第一个数组尾部,会改变第一个数组,所以这段代买就是就是把 htmlString 转为 dom 数组并追加到this的对象中。(这些方法我们后面陆续介绍,先了解其作用~)
// HANDLE: $(html, props)
if ( rsingleTag.test( match[ 1 ] ) && jQuery.isPlainObject( context ) ) {
for ( match in context ) {
// Properties of context are called as methods if possible
if ( jQuery.isFunction( this[ match ] ) ) {
this[ match ]( context[ match ] );
// ...and otherwise set as attributes
} else {
this.attr( match, context[ match ] );
}
}
}这一段是处理 jQuery( html, attributes ) 这种用法 , 第一个参数必须是单标签,第二个参数是一个普通对象,类似 { html:"hello world", id: "test" } , 把后面对象的属性一一添加到创建的这个DOM节点的属性上,(ps: 注意,这种情况下,会走上面的分支,也就是已经把单标签转为 DOM 并放到 this 对象中了,for 循环中的 match 是 context 对象的属性。如果有match的方法,就会调用 对应的 match 方法
比如{ html : “hello world”, id : “test” },就会调用 this.html(“hello world”) 方法 , 否则按照属性处理)
接着是处理 match[2] 被捕获到的情况,也就是 #id 的情况,直接了当,调用原生获取 id 元素的方法,并存放到 this 对象 返回;
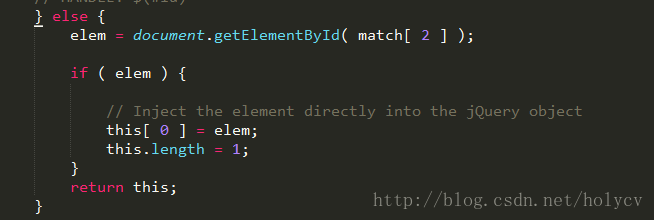
接下来就是处理复杂选择器的情况,采用find方法处理并返回,
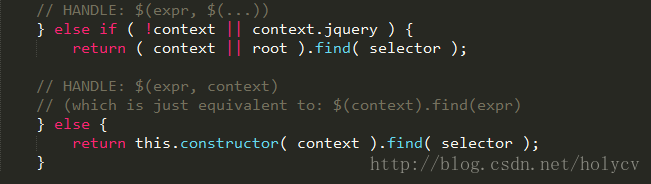
这里两个else的判断,就是为了确保是 jQuery 对象调用find方法,如果 context不是 jQuery 对象,使用 constructor 构造一个~
(ps:这块是调用Sizzle方法,这是jQuery选择器的核心方法,等到了后面我看懂了再告诉大家吧 ~ 逃 )














 511
511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









