









对Lucene代码优化
我们再次看回我们上一篇快速入门写过的代码,我来截取一些有代表性的:
以下代码在把数据填充到索引库,和从索引库查询数据的时候,都出现了。是重复代码!
Directory directory = FSDirectory.open(new File("E:/createIndexDB"));
//使用标准的分词算法对原始记录表进行拆分
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);以下的代码其实就是将JavaBean的数据封装到Document对象中,我们是可以通过反射来对其进行封装….如果不封装的话,我们如果有很多JavaBean都要添加到Document对象中,就会出现很多类似的代码。
document.add(new Field("id", user.getId(), Field.Store.YES, Field.Index.ANALYZED));
document.add(new Field("userName", user.getUserName(), Field.Store.YES, Field.Index.ANALYZED));
document.add(new Field("sal", user.getSal(), Field.Store.YES, Field.Index.ANALYZED));以下代码就是从Document对象中把数据取出来,封装到JavaBean去。如果JavaBean中有很多属性,也是需要我们写很多次类似代码….
//将Document对象中的所有属性取出,再封装回JavaBean对象中去
String id = document.get("id");
String userName = document.get("userName");
String sal = document.get("sal");
User user = new User(id, userName, sal);编写Lucene工具类
在编写工具类的时候,值得注意的地方:
- 当我们得到了对象的属性的时候,就可以把属性的get方法封装起来
- 得到get方法,就可以调用它,得到对应的值
- 在操作对象的属性时,我们要使用暴力访问
- 如果有属性,值,对象这三个变量,我们记得使用BeanUtils组件
import org.apache.commons.beanutils.BeanUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import java.io.File;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
/**
* Created by ozc on 2017/7/12.
*/
/**
* 使用单例事例模式
* */
public class LuceneUtils {
private static Directory directory;
private static Analyzer analyzer;
private static IndexWriter.MaxFieldLength maxFieldLength;
private LuceneUtils() {}
static{
try {
directory = FSDirectory.open(new File("E:/createIndexDB"));
analyzer = new StandardAnalyzer(Version.LUCENE_30);
maxFieldLength = IndexWriter.MaxFieldLength.LIMITED;
} catch (Exception e) {
e.printStackTrace();
}
}
public static Directory getDirectory() {
return directory;
}
public static Analyzer getAnalyzer() {
return analyzer;
}
public static IndexWriter.MaxFieldLength getMaxFieldLength() {
return maxFieldLength;
}
/**
* @param object 传入的JavaBean类型
* @return 返回Document对象
*/
public static Document javaBean2Document(Object object) {
try {
Document document = new Document();
//得到JavaBean的字节码文件对象
Class<?> aClass = object.getClass();
//通过字节码文件对象得到对应的属性【全部的属性,不能仅仅调用getFields()】
Field[] fields = aClass.getDeclaredFields();
//得到每个属性的名字
for (Field field : fields) {
String name = field.getName();
//得到属性的值【也就是调用getter方法获取对应的值】
String method = "get" + name.substring(0, 1).toUpperCase() + name.substring(1);
//得到对应的值【就是得到具体的方法,然后调用就行了。因为是get方法,没有参数】
Method aClassMethod = aClass.getDeclaredMethod(method, null);
String value = aClassMethod.invoke(object).toString();
System.out.println(value);
//把数据封装到Document对象中。
document.add(new org.apache.lucene.document.Field(name, value, org.apache.lucene.document.Field.Store.YES, org.apache.lucene.document.Field.Index.ANALYZED));
}
return document;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
/**
* @param aClass 要解析的对象类型,要用户传入进来
* @param document 将Document对象传入进来
* @return 返回一个JavaBean
*/
public static Object Document2JavaBean(Document document, Class aClass) {
try {
//创建该JavaBean对象
Object obj = aClass.newInstance();
//得到该JavaBean所有的成员变量
Field[] fields = aClass.getDeclaredFields();
for (Field field : fields) {
//设置允许暴力访问
field.setAccessible(true);
String name = field.getName();
String value = document.get(name);
//使用BeanUtils把数据封装到Bean中
BeanUtils.setProperty(obj, name, value);
}
return obj;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
@Test
public void test() {
User user = new User();
LuceneUtils.javaBean2Document(user);
}
}
使用LuceneUtils改造程序
@Test
public void createIndexDB() throws Exception {
//把数据填充到JavaBean对象中
User user = new User("2", "钟福成2", "未来的程序员2");
Document document = LuceneUtils.javaBean2Document(user);
/**
* IndexWriter将我们的document对象写到硬盘中
*
* 参数一:Directory d,写到硬盘中的目录路径是什么
* 参数二:Analyzer a, 以何种算法来对document中的原始记录表数据进行拆分成词汇表
* 参数三:MaxFieldLength mfl 最多将文本拆分出多少个词汇
*
* */
IndexWriter indexWriter = new IndexWriter(LuceneUtils.getDirectory(), LuceneUtils.getAnalyzer(), LuceneUtils.getMaxFieldLength());
//将Document对象通过IndexWriter对象写入索引库中
indexWriter.addDocument(document);
//关闭IndexWriter对象
indexWriter.close();
}
@Test
public void findIndexDB() throws Exception {
//创建IndexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtils.getDirectory());
//创建QueryParser对象
QueryParser queryParser = new QueryParser(Version.LUCENE_30, "userName", LuceneUtils.getAnalyzer());
//给出要查询的关键字
String keyWords = "钟";
//创建Query对象来封装关键字
Query query = queryParser.parse(keyWords);
//用IndexSearcher对象去索引库中查询符合条件的前100条记录,不足100条记录的以实际为准
TopDocs topDocs = indexSearcher.search(query, 100);
//获取符合条件的编号
for (int i = 0; i < topDocs.scoreDocs.length; i++) {
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
//用indexSearcher对象去索引库中查询编号对应的Document对象
Document document = indexSearcher.doc(no);
//将Document对象中的所有属性取出,再封装回JavaBean对象中去
User user = (User) LuceneUtils.Document2JavaBean(document, User.class);
System.out.println(user);
}
}
索引库优化
我们已经可以创建索引库并且从索引库读取对象的数据了。其实索引库还有地方可以优化的….
合并文件
我们把数据添加到索引库中的时候,每添加一次,都会帮我们自动创建一个cfs文件…
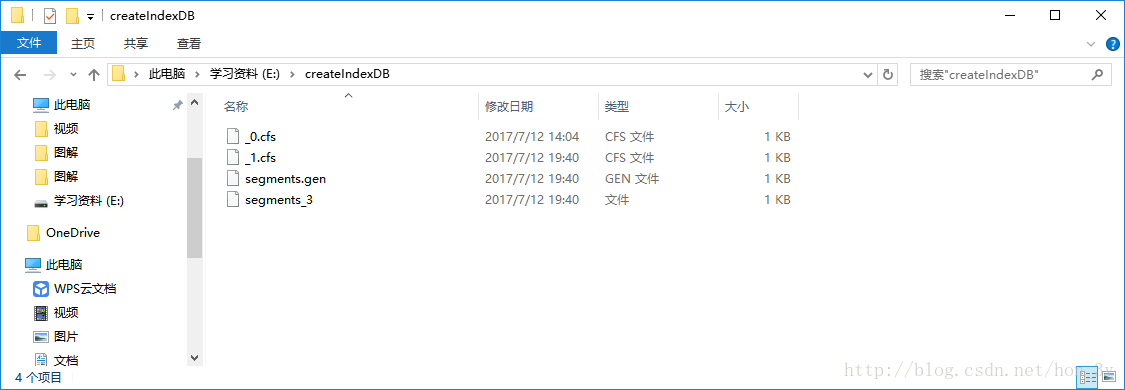
这样其实不好,因为如果数据量一大,我们的硬盘就有非常非常多的cfs文件了…..其实索引库会帮我们自动合并文件的,默认是10个。
如果,我们想要修改默认的值,我们可以通过以下的代码修改:
//索引库优化
indexWriter.optimize();
//设置合并因子为3,每当有3个cfs文件,就合并
indexWriter.setMergeFactor(3);
设置内存索引库
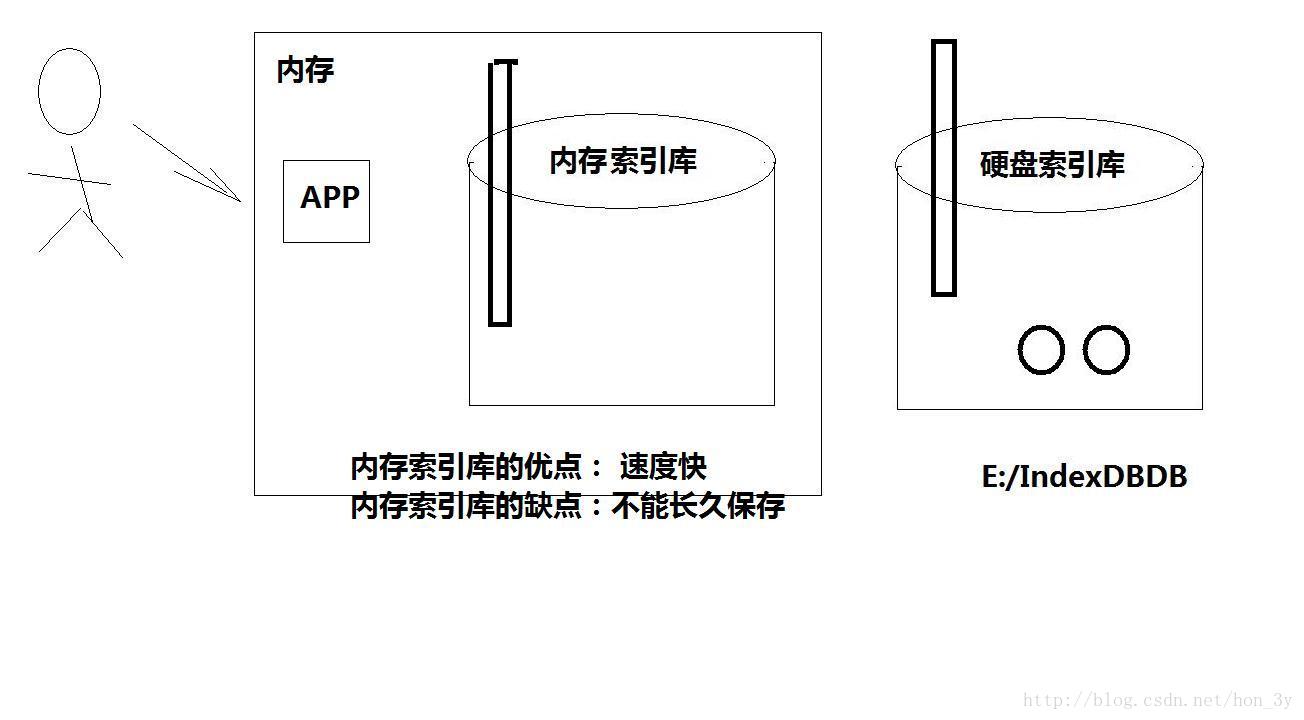
我们的目前的程序是直接与文件进行操作,这样对IO的开销其实是比较大的。而且速度相对较慢….我们可以使用内存索引库来提高我们的读写效率…
对于内存索引库而言,它的速度是很快的,因为我们直接操作内存…但是呢,我们要将内存索引库是要到硬盘索引库中保存起来的。当我们读取数据的时候,先要把硬盘索引库的数据同步到内存索引库中去的。
Article article = new Article(1,"培训","传智是一家Java培训机构");
Document document = LuceneUtil.javabean2document(article);
Directory fsDirectory = FSDirectory.open(new File("E:/indexDBDBDBDBDBDBDBDB"));
Directory ramDirectory = new RAMDirectory(fsDirectory);
IndexWriter fsIndexWriter = new IndexWriter(fsDirectory,LuceneUtil.getAnalyzer(),true,LuceneUtil.getMaxFieldLength());
IndexWriter ramIndexWriter = new IndexWriter(ramDirectory,LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
ramIndexWriter.addDocument(document);
ramIndexWriter.close();
fsIndexWriter.addIndexesNoOptimize(ramDirectory);
fsIndexWriter.close();分词器
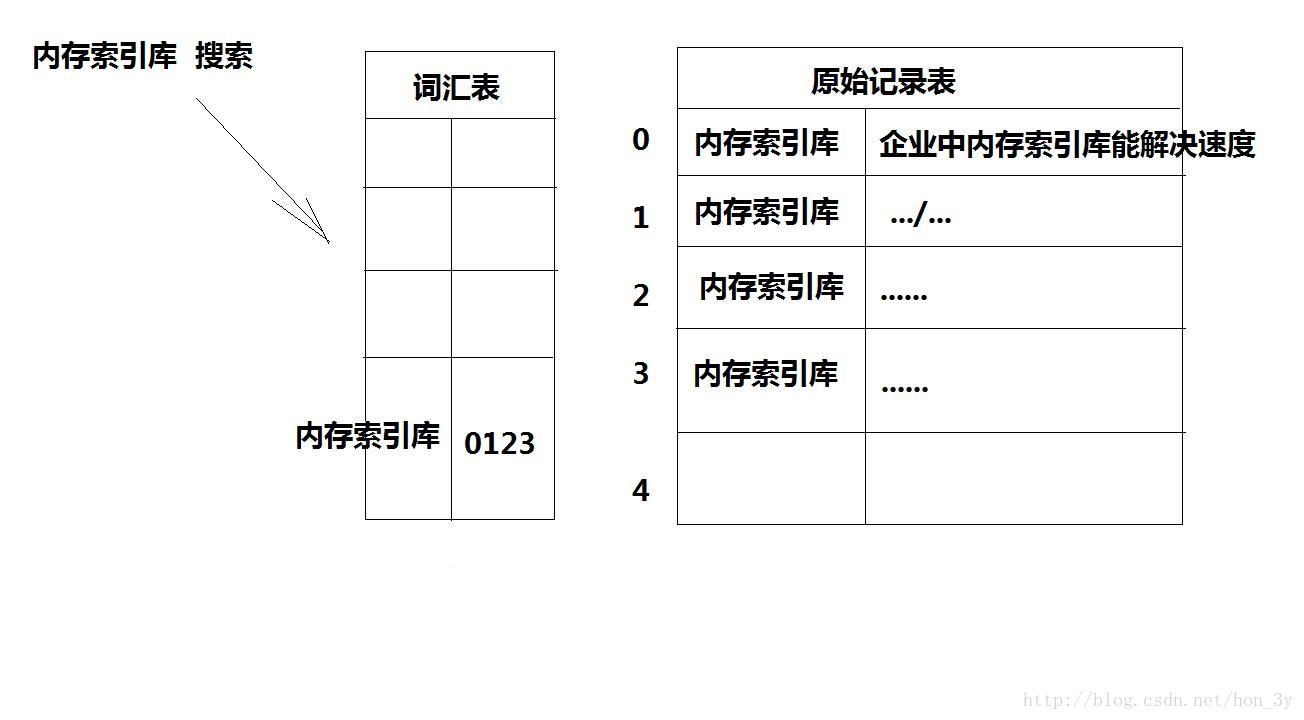
我们在Lucene第一篇中就已经说过了,在把数据存到索引库的时候,我们会使用某些算法,将原始记录表的数据存到词汇表中…..那么这些算法总和我们可以称之为分词器
分词器: * 采用一种算法,将中英文本中的字符拆分开来,形成词汇,以待用户输入关健字后搜索*
对于为什么要使用分词器,我们也明确地说过:由于用户不可能把我们的原始记录数据完完整整地记录下来,于是他们在搜索的时候,是通过关键字进行对原始记录表的查询….此时,我们就采用分词器来最大限度地匹配相关的数据
分词器流程
- 步一:按分词器拆分出词汇
- 步二:去除停用词和禁用词
- 步三:如果有英文,把英文字母转为小写,即搜索不分大小写
分词器API
我们在选择分词算法的时候,我们会发现有非常非常多地分词器API,我们可以用以下代码来看看该分词器是怎么将数据分割的:
private static void testAnalyzer(Analyzer analyzer, String text) throws Exception {
System.out.println("当前使用的分词器:" + analyzer.getClass());
TokenStream tokenStream = analyzer.tokenStream("content",new StringReader(text));
tokenStream.addAttribute(TermAttribute.class);
while (tokenStream.incrementToken()) {
TermAttribute termAttribute = tokenStream.getAttribute(TermAttribute.class);
System.out.println(termAttribute.term());
}
}在实验完之后,我们就可以选择恰当的分词算法了….
IKAnalyzer分词器
这是一个第三方的分词器,我们如果要使用的话需要导入对应的jar包
- IKAnalyzer3.2.0Stable.jar
- 步二:将IKAnalyzer.cfg.xml和stopword.dic和xxx.dic文件复制到MyEclipse的src目录下,再进行配置,在配置时,首行需要一个空行
这个第三方的分词器有什么好呢????他是中文首选的分词器…也就是说:他是按照中文的词语来进行拆分的!
搜索结果高亮
我们在使用SQL时,搜索出来的数据是没有高亮的…而我们使用Lucene,搜索出来的内容我们可以设置关键字为高亮…这样一来就更加注重用户体验了!
String keywords = "钟福成";
List<Article> articleList = new ArrayList<Article>();
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,1000000);
//设置关键字高亮
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter,scorer);
for(int i=0;i<topDocs.scoreDocs.length;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no);
//设置内容高亮
String highlighterContent = highlighter.getBestFragment(LuceneUtil.getAnalyzer(),"content",document.get("content"));
document.getField("content").setValue(highlighterContent);
Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
for(Article article : articleList){
System.out.println(article);
}
}搜索结果摘要
如果我们搜索出来的文章内容太大了,而我们只想显示部分的内容,那么我们可以对其进行摘要…
值得注意的是:搜索结果摘要需要与设置高亮一起使用
String keywords = "钟福成";
List<Article> articleList = new ArrayList<Article>();
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,1000000);
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter,scorer);
//设置摘要
Fragmenter fragmenter = new SimpleFragmenter(4);
highlighter.setTextFragmenter(fragmenter);
for(int i=0;i<topDocs.scoreDocs.length;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no);
String highlighterContent = highlighter.getBestFragment(LuceneUtil.getAnalyzer(),"content",document.get("content"));
document.getField("content").setValue(highlighterContent);
Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
for(Article article : articleList){
System.out.println(article);
}
}搜索结果排序
我们搜索引擎肯定用得也不少,使用不同的搜索引擎来搜索相同的内容。他们首页的排行顺序也会不同…这就是它们内部用了搜索结果排序….
影响网页的排序有非常多种:
- head/meta/【keywords关键字】
- 网页的标签整洁
- 网页执行速度
- 采用div+css
- 等等等等
而在Lucene中我们就可以设置相关度得分来使不同的结果对其进行排序:
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
//为结果设置得分
document.setBoost(20F);
indexWriter.addDocument(document);
indexWriter.close();当然了,我们也可以按单个字段排序:
//true表示降序
Sort sort = new Sort(new SortField("id",SortField.INT,true));
TopDocs topDocs = indexSearcher.search(query,null,1000000,sort);也可以按多个字段排序:在多字段排序中,只有第一个字段排序结果相同时,第二个字段排序才有作用 提倡用数值型排序
Sort sort = new Sort(new SortField("count",SortField.INT,true),new SortField("id",SortField.INT,true));
TopDocs topDocs = indexSearcher.search(query,null,1000000,sort);条件搜索
在我们的例子中,我们使用的是根据一个关键字来对某个字段的内容进行搜索。语法类似于下面:
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
其实,我们也可以使用关键字来对多个字段进行搜索,也就是多条件搜索。我们实际中常常用到的是多条件搜索,多条件搜索可以使用我们最大限度匹配对应的数据!
QueryParser queryParser = new MultiFieldQueryParser(LuceneUtil.getVersion(),new String[]{"content","title"},LuceneUtil.getAnalyzer());














 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









