







深入理解 Java8
简介
Java8 可谓是Java语言历史上变化最大的一个版本,其承诺要调整Java编程向着函数式风格迈进,这有助于编写出更为简介、表达力更强,并且在很多情况下能够利用并行硬件的代码。学习后可以通过Lambda表达式使用一行代码编写Java函数、如何通过这种功能使用新的Stream API进行编程,如何将冗长的集合处理代码压缩为简单且可读性更好的流程序。学习创建和消费流的机制,分析其性能,能够判断何时应该调用API的并行执行特性。
Lambda 表达式
Lambda: In programming languages such as Lisp, Python and Ruby lambda is an operator useed to denote anonymous functions or closures, following the usage of lambda calculus.
Lambda 表达式可以理解为简洁地表示可传递的匿名函数的一种方式:它没有名字,但是有参数列表、函数主题、返回类型,可能还会抛出异常列表。
匿名 — 它不像普通方法那样有一个明确的名字
函数 — 它是函数,是因为Lambda函数不像方法那样属于某个特定的类。但和方法一样,有参数列表、函数主题、返回类型,可能还会抛出异常列表。
传递 — Lambda表达式可以作为参数传递给方法或存储在变量中
简洁 — 无需想匿名类那样写很多模板代码
Lambda 表达式语法
(parameters) -> expression
(parameters) -> {statement;}
Lambda 表达式作用
Lambda表达式为Java添加了缺失的函数式编程特性,使我们能将函数当做一等公民看待
在将函数作为一等公民的语言中,Lambda表达式的类型是函数。但在Java中,Lambda表达式是对象,他们必须依附于一类特别的对象类型–函数式接口(Functional Interface)
示例
public class Test2 {
public static void main(String[] args) {
SampleInterface1 interface1 = () -> {};
System.out.println(interface1.getClass().getInterfaces()[0]);
SampleInterface2 interface2 = () -> {};
System.out.println(interface2.getClass().getInterfaces()[0]);
// 编译错误,因为Lambda表达式必须要有对应的context环境
// () -> {};
}
}
@FunctionalInterface
interface SampleInterface1 {
void method();
}
@FunctionalInterface
interface SampleInterface2 {
void method2();
}
// result
interface com.hongguo.java8.functionalinterface.SampleInterface1
interface com.hongguo.java8.functionalinterface.SampleInterface2
类型检查、类型推断和限制
类型检查
Lambda 的类型是从使用Lambda的上下文推断出来的。上下文(例如,接受它传递的方法的参数,或者接受它的值的局部变量)中Lambda表达式需要的类型称为目标类型。
类型检查示例
// 方法定义
public static List<Apple> filter(List<Applie> inventory, Predicate<Apple> p);
List<Apple> heavierThan150g = filter(inventory, a -> a.getWeight() > 150);
分析
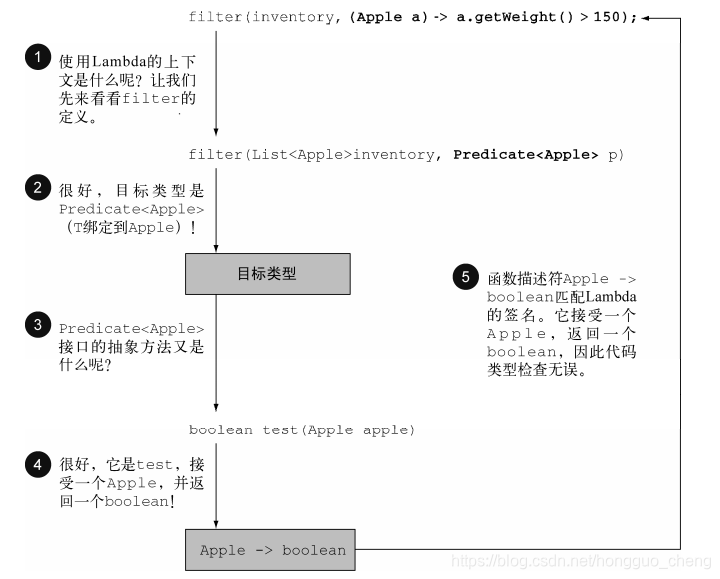
类型推断
Java编译器会从上下文(目标类型)推断出用什么函数式接口来配合Lambda表达式,它可以推断出适合Lambda的签名,因为函数描述符可以通过目标类型来得到。这样的好处在于,编译器可以了解Lambda表达式的参数类型,这样可以在Lambda语法中省去标注参数类型。
限制
局部变量的限制
- 实例变量和局部变量背后的实现有一个关键不同。实例变量都存在堆中,而局部变量则存在栈上。如果Lambda表达式可以直接访问局部变量,而且Lambda是在一个线程中使用的,则使用Lambda的线程,可能会在分配该变量的线程将这个变量回收后,去访问这个变量。因此,Java在访问自有局部变量时,实际上是访问它的副本,而不是访问原始变量。
- 这一限制不鼓励你使用改变外部变量的典型命令式编程模式
方法引用
方法引用可以看作仅仅调用特定方法的Lambda的一种快写法。
基本思想:如果一个Lambda代表的只是“直接调用这个方法”,那最好还是用名来调用它,而不是去描述如何调用它。
事实上,方法引用就是让你根据已有的方法实现来创建Lambda表达式。
构建方法引用方式
- 指向静态方法的方法引用(例如 Integer的parseInt方法,写作Integer::parseInt) ClassName::staticMethodName
- 指向任意类型实例方法的方法引用(例如 String 的 length 方法,写作String::length) instanceName::instanceMethodName
- 指向现有对象的实例方法引用(假设你有一个局部变量expensiveTransaction 用于存放Transaction类型的对象,它支持实例方法getValue,那么你就可以写expensiveTransaction::getValue)ClassName::instanceMethodName (理解:将函数式接口中的第一个参数作为实例对象,后面的参数作为instanceMethodName的参数)
- 构造方法引用 ClassName::new
分析
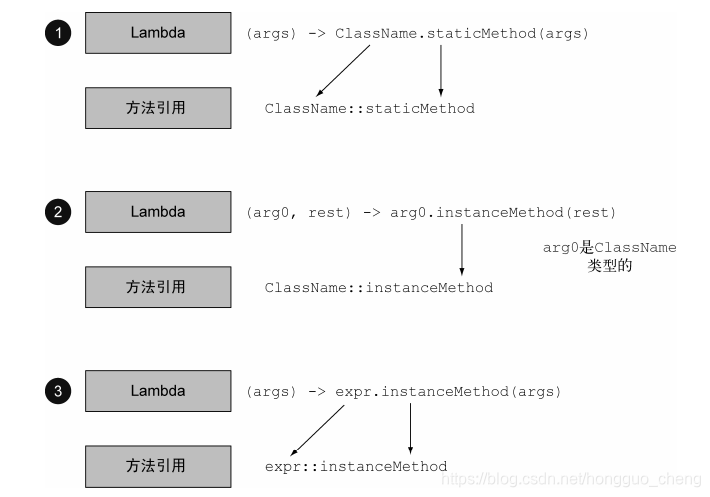
示例
// 无参构造函数,适合Supplier的签名:() -> Person。
class Person {}
Supplier<Person> supplier = Person::new;
Person person = supplier.get();
// 一个参数的构造函数,适合Function<Interer, Person>的签名:(param) -> Person
class Person {
private Integer age;
public Person(Integer age) {
this.age = age;
}
}
Function<Integer, Person> function = Person::new;
Person person = function.apply(30);
// 两个参数的构造函数,适合BiFunction<Integer, String, Person> 的签名:(param1, param2) -> Person
class Person {
private Integer age;
private String name;
public Person(Integer age, String name) {
this.age = age;
this.name = name;
}
}
BiFunction<Integer, String, Person> biFunction = Person::new;
Person person = biFunction.apply(20, "zhangsan");
函数式接口
函数式接口:
- 接口中只有一个抽象方法的接口
- 我们在某个接口上声明了FunctionalInterface注解,那么编译器就会按照函数式接口的定义来要求该接口
- 某个接口中只有一个抽象方法,但该接口没有声明FunctionalInterface注解,那么编译器依旧会将该接口看做是函数式接口
FunctionalInterface 注解
JavaDoc 文档
Note that instances of functional interfaces can be created with lambda expressions(Lambda表达式), method references(方法引用), constructor references(构造器引用)
注意:函数式接口的实例可以由 Lambda表达式、方法引用、构造器引用 来创建。
/**
* An informative annotation type used to indicate that an interface
* type declaration is intended to be a <i>functional interface</i> as
* defined by the Java Language Specification.
*
* Conceptually, a functional interface has exactly one abstract
* method. Since {@linkplain java.lang.reflect.Method#isDefault()
* default methods} have an implementation, they are not abstract. If
* an interface declares an abstract method overriding one of the
* public methods of {@code java.lang.Object}, that also does
* <em>not</em> count toward the interface's abstract method count
* since any implementation of the interface will have an
* implementation from {@code java.lang.Object} or elsewhere.
*
* <p>Note that instances of functional interfaces can be created with
* lambda expressions(Lambda表达式), method references(方法引用), or constructor references(构造器引用).
*
* <p>If a type is annotated with this annotation type, compilers are
* required to generate an error message unless:
*
* <ul>
* <li> The type is an interface type and not an annotation type, enum, or class.
* <li> The annotated type satisfies the requirements of a functional interface.
* </ul>
*
* <p>However, the compiler will treat any interface meeting the
* definition of a functional interface as a functional interface
* regardless of whether or not a {@code FunctionalInterface}
* annotation is present on the interface declaration.
*
* @jls 4.3.2. The Class Object
* @jls 9.8 Functional Interfaces
* @jls 9.4.3 Interface Method Body
* @since 1.8
*/
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface FunctionalInterface {}
示例
// 函数式接口(FunctionalInterface注解)
@FunctionalInterface
public interface MyInterface {
void test();
}
// 依旧是函数式接口(无FunctionalInterface注解)
public interface MyInterface2 {
void test();
}
// 依旧是函数式接口(FunctionalInterface注解)
// 因为toString()方法是重写了Object中的方法,故该接口依旧是函数式接口
@FunctionalInterface
public interface MyInterface3 {
void test();
// 重写了Object#toString()中的方法
String toString();
}
// 同理,此类接口不加FunctionalInterface注解,但依旧是函数式接口
public interface MyInterface4 {
void test();
String toString();
}
Consumer 接口
JavaDoc 文档
/**
* Represents an operation that accepts a single input argument and returns no
* result. Unlike most other functional interfaces, {@code Consumer} is expected
* to operate via side-effects.
*
* <p>This is a <a href="package-summary.html">functional interface</a>
* whose functional method is {@link #accept(Object)}.
*
* @param <T> the type of the input to the operation
*
* @since 1.8
*/
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
/**
* Returns a composed {@code Consumer} that performs, in sequence, this
* operation followed by the {@code after} operation. If performing either
* operation throws an exception, it is relayed to the caller of the
* composed operation. If performing this operation throws an exception,
* the {@code after} operation will not be performed.
*
* @param after the operation to perform after this operation
* @return a composed {@code Consumer} that performs in sequence this
* operation followed by the {@code after} operation
* @throws NullPointerException if {@code after} is null
*/
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
示例
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 匿名内部类
list.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(integer);
}
});
// lambda表达式
list.forEach((Integer i) -> {
System.out.println(i);
});
// lambda表达式:如果只有一个参数,可以省略()括号
list.forEach(i -> {
System.out.println(i);
});
// lambda表达式:如果方法体中只有一行,可以将statement 转换成 expression
list.forEach(i -> System.out.println(i));
// 方法引用
list.forEach(System.out::println);
Function 接口
JavaDoc 文档
/**
* Represents a function that accepts one argument and produces a result.
*
* <p>This is a <a href="package-summary.html">functional interface</a>
* whose functional method is {@link #apply(Object)}.
*
* @param <T> the type of the input to the function
* @param <R> the type of the result of the function
*
* @since 1.8
*/
@FunctionalInterface
public interface Function<T, R> {
/**
* Applies this function to the given argument.
*
* @param t the function argument
* @return the function result
*/
R apply(T t);
/**
* Returns a composed function that first applies the {@code before}
* function to its input, and then applies this function to the result.
* If evaluation of either function throws an exception, it is relayed to
* the caller of the composed function.
*
* @param <V> the type of input to the {@code before} function, and to the
* composed function
* @param before the function to apply before this function is applied
* @return a composed function that first applies the {@code before}
* function and then applies this function
* @throws NullPointerException if before is null
*
* @see #andThen(Function)
*/
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
/**
* Returns a composed function that first applies this function to
* its input, and then applies the {@code after} function to the result.
* If evaluation of either function throws an exception, it is relayed to
* the caller of the composed function.
*
* @param <V> the type of output of the {@code after} function, and of the
* composed function
* @param after the function to apply after this function is applied
* @return a composed function that first applies this function and then
* applies the {@code after} function
* @throws NullPointerException if after is null
*
* @see #compose(Function)
*/
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
/**
* Returns a function that always returns its input argument.
*
* @param <T> the type of the input and output objects to the function
* @return a function that always returns its input argument
*/
static <T> Function<T, T> identity() {
return t -> t;
}
}
示例
public class FunctionTest {
@Test
public void testApply() {
int result = compute(2, value -> value * 2);
Assert.assertEquals(4, result);
result = compute(3, value -> value * value);
Assert.assertEquals(9, result);
result = compute(5, value -> value + 5);
Assert.assertEquals(10, result);
}
private int compute(int a, Function<Integer, Integer> function) {
return function.apply(a);
}
@Test
public void testCompose() {
// compose方法代表的是在该function执行之前先执行compose中的function(before)
// 将before执行结果作为该function的输入。
Function<Integer, Integer> before = value -> value + 5;
Function<Integer, Integer> function = value -> value * 5;
// result = (2 + 5 + 5) * 5
int result = function.compose(before).compose(before).apply(2);
Assert.assertEquals(60, result);
}
@Test
public void testAndThen() {
// andThen方法代表的是在该function执行之后再执行andThen中的function(after)
// 将该function的结果作为after函数的输入。
Function<Integer, Integer> after = value -> value + 5;
Function<Integer, Integer> function = value -> value * 5;
// result = 2 * 5 + 5 + 5
int result = function.andThen(after).andThen(after).apply(2);
Assert.assertEquals(20, result);
}
@Test
public void testIdentity() {
// identity方法表示了给定一个输入,返回相同的结果。
Function<Integer, Integer> function = Function.identity();
Assert.assertEquals(Integer.valueOf(100), function.apply(100));
Assert.assertEquals(Integer.valueOf(10), function.apply(10));
}
}
BiFunction 接口
输入两个参数并返回一个结果
JavaDoc 文档
/**
* Represents a function that accepts two arguments and produces a result.
* This is the two-arity specialization of {@link Function}.
*
* <p>This is a <a href="package-summary.html">functional interface</a>
* whose functional method is {@link #apply(Object, Object)}.
*
* @param <T> the type of the first argument to the function
* @param <U> the type of the second argument to the function
* @param <R> the type of the result of the function
*
* @see Function
* @since 1.8
*/
@FunctionalInterface
public interface BiFunction<T, U, R> {
/**
* Applies this function to the given arguments.
*
* @param t the first function argument
* @param u the second function argument
* @return the function result
*/
R apply(T t, U u);
/**
* Returns a composed function that first applies this function to
* its input, and then applies the {@code after} function to the result.
* If evaluation of either function throws an exception, it is relayed to
* the caller of the composed function.
*
* @param <V> the type of output of the {@code after} function, and of the
* composed function
* @param after the function to apply after this function is applied
* @return a composed function that first applies this function and then
* applies the {@code after} function
* @throws NullPointerException if after is null
*/
default <V> BiFunction<T, U, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t, U u) -> after.apply(apply(t, u));
}
}
示例
public class BiFunctionTest {
private List<Student> students;
@Before
public void before() {
Student s1 = new Student(20, "zhangsan");
Student s2 = new Student(30, "lisi");
Student s3 = new Student(40, "wangwu");
students = Arrays.asList(s1, s2, s3);
}
@Test
public void testApply() {
List<Student> students = findStudentByAge(20, this.students);
students.forEach(student -> System.out.println(student.getAge()));
System.out.println("-------------------");
students = findStudentByAge2(20, students, (age, studentList) ->
studentList.stream().filter(student -> student.getAge() > age).collect(Collectors.toList()));
students.forEach(student -> System.out.println(student.getAge()));
}
private List<Student> findStudentByAge(Integer age, List<Student> students) {
BiFunction<Integer, List<Student>, List<Student>> biFunction = (ageOfStu, studentList) ->
studentList.stream().filter(student -> student.getAge() > ageOfStu).collect(Collectors.toList());
return biFunction.apply(age, students);
}
private List<Student> findStudentByAge2(Integer age, List<Student> students, BiFunction<Integer, List<Student>, List<Student>> biFunction) {
return biFunction.apply(age, students);
}
@Test
public void testAndThen() {
Function<Integer, Integer> function = value -> value * value;
BiFunction<Integer, Integer, Integer> bi = (value2, value3) -> value2 + value3;
// result = (10 + 5) * (10 + 5)
Integer result = bi.andThen(function).apply(10, 5);
System.out.println(result);
}
}
class Student {
private Integer age;
private String name;
public Student(Integer age, String name) {
this.age = age;
this.name = name;
}
// getter and setter
}
Predicate 接口
JavaDoc 文档
/**
* Represents a predicate (boolean-valued function) of one argument.
*
* <p>This is a <a href="package-summary.html">functional interface</a>
* whose functional method is {@link #test(Object)}.
*
* @param <T> the type of the input to the predicate
*
* @since 1.8
*/
@FunctionalInterface
public interface Predicate<T> {
/**
* Evaluates this predicate on the given argument.
*
* @param t the input argument
* @return {@code true} if the input argument matches the predicate,
* otherwise {@code false}
*/
boolean test(T t);
/**
* Returns a composed predicate that represents a short-circuiting logical
* AND of this predicate and another. When evaluating the composed
* predicate, if this predicate is {@code false}, then the {@code other}
* predicate is not evaluated.
*
* <p>Any exceptions thrown during evaluation of either predicate are relayed
* to the caller; if evaluation of this predicate throws an exception, the
* {@code other} predicate will not be evaluated.
*
* @param other a predicate that will be logically-ANDed with this
* predicate
* @return a composed predicate that represents the short-circuiting logical
* AND of this predicate and the {@code other} predicate
* @throws NullPointerException if other is null
*/
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
/**
* Returns a predicate that represents the logical negation of this
* predicate.
*
* @return a predicate that represents the logical negation of this
* predicate
*/
default Predicate<T> negate() {
return (t) -> !test(t);
}
/**
* Returns a composed predicate that represents a short-circuiting logical
* OR of this predicate and another. When evaluating the composed
* predicate, if this predicate is {@code true}, then the {@code other}
* predicate is not evaluated.
*
* <p>Any exceptions thrown during evaluation of either predicate are relayed
* to the caller; if evaluation of this predicate throws an exception, the
* {@code other} predicate will not be evaluated.
*
* @param other a predicate that will be logically-ORed with this
* predicate
* @return a composed predicate that represents the short-circuiting logical
* OR of this predicate and the {@code other} predicate
* @throws NullPointerException if other is null
*/
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
/**
* Returns a predicate that tests if two arguments are equal according
* to {@link Objects#equals(Object, Object)}.
*
* @param <T> the type of arguments to the predicate
* @param targetRef the object reference with which to compare for equality,
* which may be {@code null}
* @return a predicate that tests if two arguments are equal according
* to {@link Objects#equals(Object, Object)}
*/
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
示例
public class PredicateTest {
@Test
public void test() {
Predicate<String> predicate = s -> s.length() > 5;
boolean result = predicate.test("123467");
System.out.println(result);
}
@Test
public void testAnd() {
Predicate<String> predicate = s -> s.length() > 5;
boolean result = predicate.test("123467");
System.out.println(result);
System.out.println("-------------------");
Predicate<String> predicate1 = s -> s.length() > 10;
boolean test = predicate.and(predicate1).test("123467");
System.out.println(test);
}
@Test
public void testOr() {
Predicate<String> predicate = s -> s.length() > 5;
boolean result = predicate.test("123467");
System.out.println(result);
System.out.println("-------------------");
Predicate<String> predicate1 = s -> s.length() > 10;
boolean test = predicate.or(predicate1).test("123467");
System.out.println(test);
}
@Test
public void testNegate() {
Predicate<String> predicate = s -> s.length() > 5;
System.out.println(predicate.test("123"));
Predicate<String> negate = predicate.negate();
System.out.println(negate.test("123"));
}
@Test
public void testIsEqual() {
Predicate<Object> equal = Predicate.isEqual("123");
System.out.println(equal.test("1235"));
}
}
Supplier 接口
JavaDoc 文档
/**
* Represents a supplier of results.
*
* <p>There is no requirement that a new or distinct result be returned each
* time the supplier is invoked.
*
* <p>This is a <a href="package-summary.html">functional interface</a>
* whose functional method is {@link #get()}.
*
* @param <T> the type of results supplied by this supplier
*
* @since 1.8
*/
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
Stream 流
流允许你以声明性方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)。简短的定义就是“从支持数据处理操作的源生成的元素序列”
流元素
- 数据源 – 提供数据的源,如集合、数组等
- 中间操作 – 零个或多个中间操作,即将一个流转换成另一个流等,操作例如filter,map,reduce,find,match等。
- 终止操作 – 只能有一个终止操作,即会产生一个结果或副作用,例如count(),forEach() 等。
特点
- 流水线 – 很多流操作本身会返回一个流,这样多个操作就可以连接起来,形成一个大的流水线
- 内部迭代 – 与使用迭代器显示迭代的集合不同,流的迭代操作是在背后进行的。
- 流只能遍历一次 – 和迭代器类似,流只能遍历一次。遍历完之后,流就被消费了。
生成流
流分为串行流和并行流,创建方式很相似
通过Collection中的stream()和parallelStream() 可分别创建串行流和并行流。
JavaDoc文档
/**
* Returns a sequential {@code Stream} with this collection as its source.
*
* <p>This method should be overridden when the {@link #spliterator()}
* method cannot return a spliterator that is {@code IMMUTABLE},
* {@code CONCURRENT}, or <em>late-binding</em>. (See {@link #spliterator()}
* for details.)
*
* @implSpec
* The default implementation creates a sequential {@code Stream} from the
* collection's {@code Spliterator}.
*
* @return a sequential {@code Stream} over the elements in this collection
* @since 1.8
*/
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
/**
* Returns a possibly parallel {@code Stream} with this collection as its
* source. It is allowable for this method to return a sequential stream.
*
* <p>This method should be overridden when the {@link #spliterator()}
* method cannot return a spliterator that is {@code IMMUTABLE},
* {@code CONCURRENT}, or <em>late-binding</em>. (See {@link #spliterator()}
* for details.)
*
* @implSpec
* The default implementation creates a parallel {@code Stream} from the
* collection's {@code Spliterator}.
*
* @return a possibly parallel {@code Stream} over the elements in this
* collection
* @since 1.8
*/
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
java.util.function.Stream:
/**
* Returns a sequential {@code Stream} containing a single element.
*
* @param t the single element
* @param <T> the type of stream elements
* @return a singleton sequential stream
*/
public static<T> Stream<T> of(T t) {
return StreamSupport.stream(new Streams.StreamBuilderImpl<>(t), false);
}
/**
* Returns a sequential ordered stream whose elements are the specified values.
*
* @param <T> the type of stream elements
* @param values the elements of the new stream
* @return the new stream
*/
@SafeVarargs
@SuppressWarnings("varargs") // Creating a stream from an array is safe
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
示例
private List<Person> persons;
@Before
public void before() {
persons = new ArrayList<>();
persons.add(new Person("zhangsan", 20, 90));
persons.add(new Person("lisi", 30, 80));
persons.add(new Person("wangwu", 25, 100));
persons.add(new Person("wangwu", 40, 70));
}
@Test
public void test() {
Stream<Person> stream = persons.stream();
Stream<String> stringStream = Stream.of("hello", "world");
String[] array = new String[]{"a", "b"};
Stream<String> arrayStream = Stream.of(array);
Stream<String> stringStream1 = Arrays.stream(array);
}
class Person {
private String name;
private int age;
private int score;
public Person(String name, int age, int score) {
this.name = name;
this.age = age;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", score=" + score +
'}';
}
}
中间操作
- filter
- map
- flatMap
- sorted
- distinct
终止操作
- limit
- skip
- allMatch
- anyMatch
- noneMatch
- findFirst
- findAny
- reduce
- count
收集器
收集器是一个可变汇聚操作,该操作将输入元素累加到一个可变的结果容器,在所有输入元素处理完成后会将累加的结果转换成一个最终表示。执行汇聚操作可以是串行或并行。
一个Collector是由4个函数一起工作将输入进的元素累加到一个可变结果容器,然后对结果执行一个最终的转换。4个方法是:
- supplier() — 创建一个新的结果容器
- accumulator() — 将一个新数据元素累加到一个结果容器
- combiner() — 将两个结果容器合并成一个
- finisher() — 对结果容器执行一个可选的最终转换
串行与并行
- 串行:使用一个收集器的汇聚操作的串行实现可以使用supplier函数创建一个单一的结果容器,然后只调用accumulator函数一次来处理每个输入元素。
- 并行:一个并行实现可以将输入数据分区,每个分区创建一个结果容器,累加每个容器的内容到这个分区的子结果中,然后使用combiner函数将这些子结果合并成一个结果。
同一性和结合性
为确保串行和并行执行产生相同的结果,收集器函数必须满足同一性(identity)和结合性(associativity)约束。
- 同一性:同一性约束是指任何部分累积结果与一个空结果容器合并必须产生一个相同的结果。就是一个部分累积结果 a(任意连续的accumulator和combiner调用的结果),a必须与combiner.apply(a, supplier.get()) 相等。
- 结合性:结合性约束是指分隔计算必须生成相同的结果。就是对任何输入元素 t1和t2,r1和r2的计算的结果必须相等. 代码示例如下:
A a1 = supplier.get();
accumulator.accept(a1, t1);
accumulator.accept(a1, t2);
R r1 = finisher.apply(a1); // result without splitting
A a2 = supplier.get();
accumulator.accept(a2, t1);
A a3 = supplier.get();
accumulator.accept(a3, t2);
R r2 = finisher.apply(combiner.apply(a2, a3)); // result with splitting
对于没有UNORDERED特性的收集器来说,如果finisher.apply(a1).equals(finisher.apply(a2))则两个累加结果是相等的。对于无序的收集器来说,相等是松散的去允许非相等性关于不同顺序(例如,一个无序收集器将累加结果到一个List中,如果两个list中的元素不考虑顺序外是相等的,那这两个list是相等的)
约束
基于Collector实现汇聚操作的类库,例如Stream#collect(Collector),必须满足以下几个约束
- 传递accumulate函数的第一个参数,传递给combiner函数的两个参数,传递给finisher函数的参数必须是函数supplier,accumulator或combiner上一次调用的结果。
- 收集器的一个实现不应该对supplier,accumulator或combiner函数的任何结果做任何事,而仅仅应该将这些结果再次传递给accumulator,combiner或finisher函数,或者返回给汇聚操作的调用者。
- 如果一个结果传递给combiner或finisher函数,并且相同对象未从该函数返回,那么它将不在使用了。
- 一旦一个结果传递给combiner或finisher函数,则它不会再次传递给accumulator函数。
- 对于非并发收集器来说,任何从supplier,accumulator或combiner函数返回的结果必须线程保证的(必须在同一线程中执行)。这就确保并发收集时无需额外的同步实现。汇聚实现必须管理输入被正确的分区,而且各区之间相互隔离,只当所有累加操作完成后再执行合并操作。
- 对于并发收集器来说,一个实现是自由的实现并发的汇聚操作。一个并发汇聚是从多个线程并发调用accumlator函数,使用相同的并发可修改的结果容器而不是累加期间保持结果相互隔离。一个汇聚操作应该仅仅应用如果收集器包含UNORDERED特性或如果院士数据是无序的。
JavaDoc
package java.util.stream;
import java.util.Collections;
import java.util.EnumSet;
import java.util.Objects;
import java.util.Set;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
/**
* A <a href="package-summary.html#Reduction">mutable reduction operation</a> that
* accumulates input elements into a mutable result container, optionally transforming
* the accumulated result into a final representation after all input elements
* have been processed. Reduction operations can be performed either sequentially
* or in parallel.
*
* <p>Examples of mutable reduction operations include:
* accumulating elements into a {@code Collection}; concatenating
* strings using a {@code StringBuilder}; computing summary information about
* elements such as sum, min, max, or average; computing "pivot table" summaries
* such as "maximum valued transaction by seller", etc. The class {@link Collectors}
* provides implementations of many common mutable reductions.
*
* <p>A {@code Collector} is specified by four functions that work together to
* accumulate entries into a mutable result container, and optionally perform
* a final transform on the result. They are: <ul>
* <li>creation of a new result container ({@link #supplier()})</li>
* <li>incorporating a new data element into a result container ({@link #accumulator()})</li>
* <li>combining two result containers into one ({@link #combiner()})</li>
* <li>performing an optional final transform on the container ({@link #finisher()})</li>
* </ul>
*
* <p>Collectors also have a set of characteristics, such as
* {@link Characteristics#CONCURRENT}, that provide hints that can be used by a
* reduction implementation to provide better performance.
*
* <p>A sequential implementation of a reduction using a collector would
* create a single result container using the supplier function, and invoke the
* accumulator function once for each input element. A parallel implementation
* would partition the input, create a result container for each partition,
* accumulate the contents of each partition into a subresult for that partition,
* and then use the combiner function to merge the subresults into a combined
* result.
*
* <p>To ensure that sequential and parallel executions produce equivalent
* results, the collector functions must satisfy an <em>identity</em> and an
* <a href="package-summary.html#Associativity">associativity</a> constraints.
*
* <p>The identity constraint says that for any partially accumulated result,
* combining it with an empty result container must produce an equivalent
* result. That is, for a partially accumulated result {@code a} that is the
* result of any series of accumulator and combiner invocations, {@code a} must
* be equivalent to {@code combiner.apply(a, supplier.get())}.
*
* <p>The associativity constraint says that splitting the computation must
* produce an equivalent result. That is, for any input elements {@code t1}
* and {@code t2}, the results {@code r1} and {@code r2} in the computation
* below must be equivalent:
* <pre>{@code
* A a1 = supplier.get();
* accumulator.accept(a1, t1);
* accumulator.accept(a1, t2);
* R r1 = finisher.apply(a1); // result without splitting
*
* A a2 = supplier.get();
* accumulator.accept(a2, t1);
* A a3 = supplier.get();
* accumulator.accept(a3, t2);
* R r2 = finisher.apply(combiner.apply(a2, a3)); // result with splitting
* } </pre>
*
* <p>For collectors that do not have the {@code UNORDERED} characteristic,
* two accumulated results {@code a1} and {@code a2} are equivalent if
* {@code finisher.apply(a1).equals(finisher.apply(a2))}. For unordered
* collectors, equivalence is relaxed to allow for non-equality related to
* differences in order. (For example, an unordered collector that accumulated
* elements to a {@code List} would consider two lists equivalent if they
* contained the same elements, ignoring order.)
*
* <p>Libraries that implement reduction based on {@code Collector}, such as
* {@link Stream#collect(Collector)}, must adhere to the following constraints:
* <ul>
* <li>The first argument passed to the accumulator function, both
* arguments passed to the combiner function, and the argument passed to the
* finisher function must be the result of a previous invocation of the
* result supplier, accumulator, or combiner functions.</li>
* <li>The implementation should not do anything with the result of any of
* the result supplier, accumulator, or combiner functions other than to
* pass them again to the accumulator, combiner, or finisher functions,
* or return them to the caller of the reduction operation.</li>
* <li>If a result is passed to the combiner or finisher
* function, and the same object is not returned from that function, it is
* never used again.</li>
* <li>Once a result is passed to the combiner or finisher function, it
* is never passed to the accumulator function again.</li>
* <li>For non-concurrent collectors, any result returned from the result
* supplier, accumulator, or combiner functions must be serially
* thread-confined. This enables collection to occur in parallel without
* the {@code Collector} needing to implement any additional synchronization.
* The reduction implementation must manage that the input is properly
* partitioned, that partitions are processed in isolation, and combining
* happens only after accumulation is complete.</li>
* <li>For concurrent collectors, an implementation is free to (but not
* required to) implement reduction concurrently. A concurrent reduction
* is one where the accumulator function is called concurrently from
* multiple threads, using the same concurrently-modifiable result container,
* rather than keeping the result isolated during accumulation.
* A concurrent reduction should only be applied if the collector has the
* {@link Characteristics#UNORDERED} characteristics or if the
* originating data is unordered.</li>
* </ul>
*
* <p>In addition to the predefined implementations in {@link Collectors}, the
* static factory methods {@link #of(Supplier, BiConsumer, BinaryOperator, Characteristics...)}
* can be used to construct collectors. For example, you could create a collector
* that accumulates widgets into a {@code TreeSet} with:
*
* <pre>{@code
* Collector<Widget, ?, TreeSet<Widget>> intoSet =
* Collector.of(TreeSet::new, TreeSet::add,
* (left, right) -> { left.addAll(right); return left; });
* }</pre>
*
* (This behavior is also implemented by the predefined collector
* {@link Collectors#toCollection(Supplier)}).
*
* @apiNote
* Performing a reduction operation with a {@code Collector} should produce a
* result equivalent to:
* <pre>{@code
* R container = collector.supplier().get();
* for (T t : data)
* collector.accumulator().accept(container, t);
* return collector.finisher().apply(container);
* }</pre>
*
* <p>However, the library is free to partition the input, perform the reduction
* on the partitions, and then use the combiner function to combine the partial
* results to achieve a parallel reduction. (Depending on the specific reduction
* operation, this may perform better or worse, depending on the relative cost
* of the accumulator and combiner functions.)
*
* <p>Collectors are designed to be <em>composed</em>; many of the methods
* in {@link Collectors} are functions that take a collector and produce
* a new collector. For example, given the following collector that computes
* the sum of the salaries of a stream of employees:
*
* <pre>{@code
* Collector<Employee, ?, Integer> summingSalaries
* = Collectors.summingInt(Employee::getSalary))
* }</pre>
*
* If we wanted to create a collector to tabulate the sum of salaries by
* department, we could reuse the "sum of salaries" logic using
* {@link Collectors#groupingBy(Function, Collector)}:
*
* <pre>{@code
* Collector<Employee, ?, Map<Department, Integer>> summingSalariesByDept
* = Collectors.groupingBy(Employee::getDepartment, summingSalaries);
* }</pre>
*
* @see Stream#collect(Collector)
* @see Collectors
*
* @param <T> the type of input elements to the reduction operation
* @param <A> the mutable accumulation type of the reduction operation (often
* hidden as an implementation detail)
* @param <R> the result type of the reduction operation
* @since 1.8
*/
public interface Collector<T, A, R> {
/**
* A function that creates and returns a new mutable result container.
*
* @return a function which returns a new, mutable result container
*/
Supplier<A> supplier();
/**
* A function that folds a value into a mutable result container.
*
* @return a function which folds a value into a mutable result container
*/
BiConsumer<A, T> accumulator();
/**
* A function that accepts two partial results and merges them. The
* combiner function may fold state from one argument into the other and
* return that, or may return a new result container.
*
* @return a function which combines two partial results into a combined
* result
*/
BinaryOperator<A> combiner();
/**
* Perform the final transformation from the intermediate accumulation type
* {@code A} to the final result type {@code R}.
*
* <p>If the characteristic {@code IDENTITY_TRANSFORM} is
* set, this function may be presumed to be an identity transform with an
* unchecked cast from {@code A} to {@code R}.
*
* @return a function which transforms the intermediate result to the final
* result
*/
Function<A, R> finisher();
/**
* Returns a {@code Set} of {@code Collector.Characteristics} indicating
* the characteristics of this Collector. This set should be immutable.
*
* @return an immutable set of collector characteristics
*/
Set<Characteristics> characteristics();
/**
* Returns a new {@code Collector} described by the given {@code supplier},
* {@code accumulator}, and {@code combiner} functions. The resulting
* {@code Collector} has the {@code Collector.Characteristics.IDENTITY_FINISH}
* characteristic.
*
* @param supplier The supplier function for the new collector
* @param accumulator The accumulator function for the new collector
* @param combiner The combiner function for the new collector
* @param characteristics The collector characteristics for the new
* collector
* @param <T> The type of input elements for the new collector
* @param <R> The type of intermediate accumulation result, and final result,
* for the new collector
* @throws NullPointerException if any argument is null
* @return the new {@code Collector}
*/
public static<T, R> Collector<T, R, R> of(Supplier<R> supplier,
BiConsumer<R, T> accumulator,
BinaryOperator<R> combiner,
Characteristics... characteristics) {
Objects.requireNonNull(supplier);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(combiner);
Objects.requireNonNull(characteristics);
Set<Characteristics> cs = (characteristics.length == 0)
? Collectors.CH_ID
: Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH,
characteristics));
return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, cs);
}
/**
* Returns a new {@code Collector} described by the given {@code supplier},
* {@code accumulator}, {@code combiner}, and {@code finisher} functions.
*
* @param supplier The supplier function for the new collector
* @param accumulator The accumulator function for the new collector
* @param combiner The combiner function for the new collector
* @param finisher The finisher function for the new collector
* @param characteristics The collector characteristics for the new
* collector
* @param <T> The type of input elements for the new collector
* @param <A> The intermediate accumulation type of the new collector
* @param <R> The final result type of the new collector
* @throws NullPointerException if any argument is null
* @return the new {@code Collector}
*/
public static<T, A, R> Collector<T, A, R> of(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A, R> finisher,
Characteristics... characteristics) {
Objects.requireNonNull(supplier);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(combiner);
Objects.requireNonNull(finisher);
Objects.requireNonNull(characteristics);
Set<Characteristics> cs = Collectors.CH_NOID;
if (characteristics.length > 0) {
cs = EnumSet.noneOf(Characteristics.class);
Collections.addAll(cs, characteristics);
cs = Collections.unmodifiableSet(cs);
}
return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, finisher, cs);
}
/**
* Characteristics indicating properties of a {@code Collector}, which can
* be used to optimize reduction implementations.
*/
enum Characteristics {
/**
* Indicates that this collector is <em>concurrent</em>, meaning that
* the result container can support the accumulator function being
* called concurrently with the same result container from multiple
* threads.
*
* <p>If a {@code CONCURRENT} collector is not also {@code UNORDERED},
* then it should only be evaluated concurrently if applied to an
* unordered data source.
*/
CONCURRENT,
/**
* Indicates that the collection operation does not commit to preserving
* the encounter order of input elements. (This might be true if the
* result container has no intrinsic order, such as a {@link Set}.)
*/
UNORDERED,
/**
* Indicates that the finisher function is the identity function and
* can be elided. If set, it must be the case that an unchecked cast
* from A to R will succeed.
*/
IDENTITY_FINISH
}
}
自定义收集器
将List转换为Set收集器
代码示例:
package com.hongguo.java.base.collectors;
import java.util.*;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
/**
* List转Set收集器
*/
public class MySetCollector<T> implements Collector<T, Set<T>, Set<T>> {
@Override
public Supplier<Set<T>> supplier() {
return HashSet::new;
}
@Override
public BiConsumer<Set<T>, T> accumulator() {
return Set::add;
}
@Override
public BinaryOperator<Set<T>> combiner() {
return (left, right) -> {
left.addAll(right);
return left;
};
}
@Override
public Function<Set<T>, Set<T>> finisher() {
return Function.identity();
}
@Override
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH, Characteristics.UNORDERED));
}
// 测试
public static void main(String[] args) {
List<String> list = Arrays.asList("hello", "world", "hello", "world", "hello world");
Set<String> set = list.stream().collect(new MySetCollector<>());
set.forEach(System.out::println);
}
// output
world
hello
hello world
}
Collectors 工具类
Collectors工具类提供了很多收集器的实现方法,包括toList(), toSet(), toCollection(), groupingBy(), paratitioningBy() 等。主要是为Stream.collect()收集方法提供便利
JavaDoc文档
package java.util.stream;
import java.util.AbstractMap;
import java.util.AbstractSet;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.Collections;
import java.util.Comparator;
import java.util.DoubleSummaryStatistics;
import java.util.EnumSet;
import java.util.HashMap;
import java.util.HashSet;
import java.util.IntSummaryStatistics;
import java.util.Iterator;
import java.util.List;
import java.util.LongSummaryStatistics;
import java.util.Map;
import java.util.Objects;
import java.util.Optional;
import java.util.Set;
import java.util.StringJoiner;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.function.BiConsumer;
import java.util.function.BiFunction;
import java.util.function.BinaryOperator;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.Predicate;
import java.util.function.Supplier;
import java.util.function.ToDoubleFunction;
import java.util.function.ToIntFunction;
import java.util.function.ToLongFunction;
/**
* Implementations of {@link Collector} that implement various useful reduction
* operations, such as accumulating elements into collections, summarizing
* elements according to various criteria, etc.
*
* <p>The following are examples of using the predefined collectors to perform
* common mutable reduction tasks:
*
* <pre>{@code
* // Accumulate names into a List
* List<String> list = people.stream().map(Person::getName).collect(Collectors.toList());
*
* // Accumulate names into a TreeSet
* Set<String> set = people.stream().map(Person::getName).collect(Collectors.toCollection(TreeSet::new));
*
* // Convert elements to strings and concatenate them, separated by commas
* String joined = things.stream()
* .map(Object::toString)
* .collect(Collectors.joining(", "));
*
* // Compute sum of salaries of employee
* int total = employees.stream()
* .collect(Collectors.summingInt(Employee::getSalary)));
*
* // Group employees by department
* Map<Department, List<Employee>> byDept
* = employees.stream()
* .collect(Collectors.groupingBy(Employee::getDepartment));
*
* // Compute sum of salaries by department
* Map<Department, Integer> totalByDept
* = employees.stream()
* .collect(Collectors.groupingBy(Employee::getDepartment,
* Collectors.summingInt(Employee::getSalary)));
*
* // Partition students into passing and failing
* Map<Boolean, List<Student>> passingFailing =
* students.stream()
* .collect(Collectors.partitioningBy(s -> s.getGrade() >= PASS_THRESHOLD));
*
* }</pre>
*
* @since 1.8
*/
public final class Collectors {
static final Set<Collector.Characteristics> CH_CONCURRENT_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_CONCURRENT_NOID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED));
static final Set<Collector.Characteristics> CH_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_UNORDERED_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_NOID = Collections.emptySet();
private Collectors() { }
/**
* Returns a merge function, suitable for use in
* {@link Map#merge(Object, Object, BiFunction) Map.merge()} or
* {@link #toMap(Function, Function, BinaryOperator) toMap()}, which always
* throws {@code IllegalStateException}. This can be used to enforce the
* assumption that the elements being collected are distinct.
*
* @param <T> the type of input arguments to the merge function
* @return a merge function which always throw {@code IllegalStateException}
*/
private static <T> BinaryOperator<T> throwingMerger() {
return (u,v) -> { throw new IllegalStateException(String.format("Duplicate key %s", u)); };
}
@SuppressWarnings("unchecked")
private static <I, R> Function<I, R> castingIdentity() {
return i -> (R) i;
}
/**
* Simple implementation class for {@code Collector}.
*
* @param <T> the type of elements to be collected
* @param <R> the type of the result
*/
static class CollectorImpl<T, A, R> implements Collector<T, A, R> {
private final Supplier<A> supplier;
private final BiConsumer<A, T> accumulator;
private final BinaryOperator<A> combiner;
private final Function<A, R> finisher;
private final Set<Characteristics> characteristics;
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A,R> finisher,
Set<Characteristics> characteristics) {
this.supplier = supplier;
this.accumulator = accumulator;
this.combiner = combiner;
this.finisher = finisher;
this.characteristics = characteristics;
}
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Set<Characteristics> characteristics) {
this(supplier, accumulator, combiner, castingIdentity(), characteristics);
}
@Override
public BiConsumer<A, T> accumulator() {
return accumulator;
}
@Override
public Supplier<A> supplier() {
return supplier;
}
@Override
public BinaryOperator<A> combiner() {
return combiner;
}
@Override
public Function<A, R> finisher() {
return finisher;
}
@Override
public Set<Characteristics> characteristics() {
return characteristics;
}
}
/**
* Returns a {@code Collector} that accumulates the input elements into a
* new {@code Collection}, in encounter order. The {@code Collection} is
* created by the provided factory.
*
* @param <T> the type of the input elements
* @param <C> the type of the resulting {@code Collection}
* @param collectionFactory a {@code Supplier} which returns a new, empty
* {@code Collection} of the appropriate type
* @return a {@code Collector} which collects all the input elements into a
* {@code Collection}, in encounter order
*/
public static <T, C extends Collection<T>>
Collector<T, ?, C> toCollection(Supplier<C> collectionFactory) {
return new CollectorImpl<>(collectionFactory, Collection<T>::add,
(r1, r2) -> { r1.addAll(r2); return r1; },
CH_ID);
}
/**
* Returns a {@code Collector} that accumulates the input elements into a
* new {@code List}. There are no guarantees on the type, mutability,
* serializability, or thread-safety of the {@code List} returned; if more
* control over the returned {@code List} is required, use {@link #toCollection(Supplier)}.
*
* @param <T> the type of the input elements
* @return a {@code Collector} which collects all the input elements into a
* {@code List}, in encounter order
*/
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
/**
* Returns a {@code Collector} that accumulates the input elements into a
* new {@code Set}. There are no guarantees on the type, mutability,
* serializability, or thread-safety of the {@code Set} returned; if more
* control over the returned {@code Set} is required, use
* {@link #toCollection(Supplier)}.
*
* <p>This is an {@link Collector.Characteristics#UNORDERED unordered}
* Collector.
*
* @param <T> the type of the input elements
* @return a {@code Collector} which collects all the input elements into a
* {@code Set}
*/
public static <T>
Collector<T, ?, Set<T>> toSet() {
return new CollectorImpl<>((Supplier<Set<T>>) HashSet::new, Set::add,
(left, right) -> { left.addAll(right); return left; },
CH_UNORDERED_ID);
}
/**
* Returns a {@code Collector} that concatenates the input elements into a
* {@code String}, in encounter order.
*
* @return a {@code Collector} that concatenates the input elements into a
* {@code String}, in encounter order
*/
public static Collector<CharSequence, ?, String> joining() {
return new CollectorImpl<CharSequence, StringBuilder, String>(
StringBuilder::new, StringBuilder::append,
(r1, r2) -> { r1.append(r2); return r1; },
StringBuilder::toString, CH_NOID);
}
/**
* Returns a {@code Collector} that concatenates the input elements,
* separated by the specified delimiter, in encounter order.
*
* @param delimiter the delimiter to be used between each element
* @return A {@code Collector} which concatenates CharSequence elements,
* separated by the specified delimiter, in encounter order
*/
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter) {
return joining(delimiter, "", "");
}
/**
* Returns a {@code Collector} that concatenates the input elements,
* separated by the specified delimiter, with the specified prefix and
* suffix, in encounter order.
*
* @param delimiter the delimiter to be used between each element
* @param prefix the sequence of characters to be used at the beginning
* of the joined result
* @param suffix the sequence of characters to be used at the end
* of the joined result
* @return A {@code Collector} which concatenates CharSequence elements,
* separated by the specified delimiter, in encounter order
*/
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter,
CharSequence prefix,
CharSequence suffix) {
return new CollectorImpl<>(
() -> new StringJoiner(delimiter, prefix, suffix),
StringJoiner::add, StringJoiner::merge,
StringJoiner::toString, CH_NOID);
}
/**
* {@code BinaryOperator<Map>} that merges the contents of its right
* argument into its left argument, using the provided merge function to
* handle duplicate keys.
*
* @param <K> type of the map keys
* @param <V> type of the map values
* @param <M> type of the map
* @param mergeFunction A merge function suitable for
* {@link Map#merge(Object, Object, BiFunction) Map.merge()}
* @return a merge function for two maps
*/
private static <K, V, M extends Map<K,V>>
BinaryOperator<M> mapMerger(BinaryOperator<V> mergeFunction) {
return (m1, m2) -> {
for (Map.Entry<K,V> e : m2.entrySet())
m1.merge(e.getKey(), e.getValue(), mergeFunction);
return m1;
};
}
/**
* Adapts a {@code Collector} accepting elements of type {@code U} to one
* accepting elements of type {@code T} by applying a mapping function to
* each input element before accumulation.
*
* @apiNote
* The {@code mapping()} collectors are most useful when used in a
* multi-level reduction, such as downstream of a {@code groupingBy} or
* {@code partitioningBy}. For example, given a stream of
* {@code Person}, to accumulate the set of last names in each city:
* <pre>{@code
* Map<City, Set<String>> lastNamesByCity
* = people.stream().collect(groupingBy(Person::getCity,
* mapping(Person::getLastName, toSet())));
* }</pre>
*
* @param <T> the type of the input elements
* @param <U> type of elements accepted by downstream collector
* @param <A> intermediate accumulation type of the downstream collector
* @param <R> result type of collector
* @param mapper a function to be applied to the input elements
* @param downstream a collector which will accept mapped values
* @return a collector which applies the mapping function to the input
* elements and provides the mapped results to the downstream collector
*/
public static <T, U, A, R>
Collector<T, ?, R> mapping(Function<? super T, ? extends U> mapper,
Collector<? super U, A, R> downstream) {
BiConsumer<A, ? super U> downstreamAccumulator = downstream.accumulator();
return new CollectorImpl<>(downstream.supplier(),
(r, t) -> downstreamAccumulator.accept(r, mapper.apply(t)),
downstream.combiner(), downstream.finisher(),
downstream.characteristics());
}
/**
* Adapts a {@code Collector} to perform an additional finishing
* transformation. For example, one could adapt the {@link #toList()}
* collector to always produce an immutable list with:
* <pre>{@code
* List<String> people
* = people.stream().collect(collectingAndThen(toList(), Collections::unmodifiableList));
* }</pre>
*
* @param <T> the type of the input elements
* @param <A> intermediate accumulation type of the downstream collector
* @param <R> result type of the downstream collector
* @param <RR> result type of the resulting collector
* @param downstream a collector
* @param finisher a function to be applied to the final result of the downstream collector
* @return a collector which performs the action of the downstream collector,
* followed by an additional finishing step
*/
public static<T,A,R,RR> Collector<T,A,RR> collectingAndThen(Collector<T,A,R> downstream,
Function<R,RR> finisher) {
Set<Collector.Characteristics> characteristics = downstream.characteristics();
if (characteristics.contains(Collector.Characteristics.IDENTITY_FINISH)) {
if (characteristics.size() == 1)
characteristics = Collectors.CH_NOID;
else {
characteristics = EnumSet.copyOf(characteristics);
characteristics.remove(Collector.Characteristics.IDENTITY_FINISH);
characteristics = Collections.unmodifiableSet(characteristics);
}
}
return new CollectorImpl<>(downstream.supplier(),
downstream.accumulator(),
downstream.combiner(),
downstream.finisher().andThen(finisher),
characteristics);
}
/**
* Returns a {@code Collector} accepting elements of type {@code T} that
* counts the number of input elements. If no elements are present, the
* result is 0.
*
* @implSpec
* This produces a result equivalent to:
* <pre>{@code
* reducing(0L, e -> 1L, Long::sum)
* }</pre>
*
* @param <T> the type of the input elements
* @return a {@code Collector} that counts the input elements
*/
public static <T> Collector<T, ?, Long>
counting() {
return reducing(0L, e -> 1L, Long::sum);
}
/**
* Returns a {@code Collector} that produces the minimal element according
* to a given {@code Comparator}, described as an {@code Optional<T>}.
*
* @implSpec
* This produces a result equivalent to:
* <pre>{@code
* reducing(BinaryOperator.minBy(comparator))
* }</pre>
*
* @param <T> the type of the input elements
* @param comparator a {@code Comparator} for comparing elements
* @return a {@code Collector} that produces the minimal value
*/
public static <T> Collector<T, ?, Optional<T>>
minBy(Comparator<? super T> comparator) {
return reducing(BinaryOperator.minBy(comparator));
}
/**
* Returns a {@code Collector} that produces the maximal element according
* to a given {@code Comparator}, described as an {@code Optional<T>}.
*
* @implSpec
* This produces a result equivalent to:
* <pre>{@code
* reducing(BinaryOperator.maxBy(comparator))
* }</pre>
*
* @param <T> the type of the input elements
* @param comparator a {@code Comparator} for comparing elements
* @return a {@code Collector} that produces the maximal value
*/
public static <T> Collector<T, ?, Optional<T>>
maxBy(Comparator<? super T> comparator) {
return reducing(BinaryOperator.maxBy(comparator));
}
/**
* Returns a {@code Collector} that produces the sum of a integer-valued
* function applied to the input elements. If no elements are present,
* the result is 0.
*
* @param <T> the type of the input elements
* @param mapper a function extracting the property to be summed
* @return a {@code Collector} that produces the sum of a derived property
*/
public static <T> Collector<T, ?, Integer>
summingInt(ToIntFunction<? super T> mapper) {
return new CollectorImpl<>(
() -> new int[1],
(a, t) -> { a[0] += mapper.applyAsInt(t); },
(a, b) -> { a[0] += b[0]; return a; },
a -> a[0], CH_NOID);
}
/**
* Returns a {@code Collector} that produces the sum of a long-valued
* function applied to the input elements. If no elements are present,
* the result is 0.
*
* @param <T> the type of the input elements
* @param mapper a function extracting the property to be summed
* @return a {@code Collector} that produces the sum of a derived property
*/
public static <T> Collector<T, ?, Long>
summingLong(ToLongFunction<? super T> mapper) {
return new CollectorImpl<>(
() -> new long[1],
(a, t) -> { a[0] += mapper.applyAsLong(t); },
(a, b) -> { a[0] += b[0]; return a; },
a -> a[0], CH_NOID);
}
/**
* Returns a {@code Collector} that produces the sum of a double-valued
* function applied to the input elements. If no elements are present,
* the result is 0.
*
* <p>The sum returned can vary depending upon the order in which
* values are recorded, due to accumulated rounding error in
* addition of values of differing magnitudes. Values sorted by increasing
* absolute magnitude tend to yield more accurate results. If any recorded
* value is a {@code NaN} or the sum is at any point a {@code NaN} then the
* sum will be {@code NaN}.
*
* @param <T> the type of the input elements
* @param mapper a function extracting the property to be summed
* @return a {@code Collector} that produces the sum of a derived property
*/
public static <T> Collector<T, ?, Double>
summingDouble(ToDoubleFunction<? super T> mapper) {
/*
* In the arrays allocated for the collect operation, index 0
* holds the high-order bits of the running sum, index 1 holds
* the low-order bits of the sum computed via compensated
* summation, and index 2 holds the simple sum used to compute
* the proper result if the stream contains infinite values of
* the same sign.
*/
return new CollectorImpl<>(
() -> new double[3],
(a, t) -> { sumWithCompensation(a, mapper.applyAsDouble(t));
a[2] += mapper.applyAsDouble(t);},
(a, b) -> { sumWithCompensation(a, b[0]);
a[2] += b[2];
return sumWithCompensation(a, b[1]); },
a -> computeFinalSum(a),
CH_NOID);
}
/**
* Incorporate a new double value using Kahan summation /
* compensation summation.
*
* High-order bits of the sum are in intermediateSum[0], low-order
* bits of the sum are in intermediateSum[1], any additional
* elements are application-specific.
*
* @param intermediateSum the high-order and low-order words of the intermediate sum
* @param value the name value to be included in the running sum
*/
static double[] sumWithCompensation(double[] intermediateSum, double value) {
double tmp = value - intermediateSum[1];
double sum = intermediateSum[0];
double velvel = sum + tmp; // Little wolf of rounding error
intermediateSum[1] = (velvel - sum) - tmp;
intermediateSum[0] = velvel;
return intermediateSum;
}
/**
* If the compensated sum is spuriously NaN from accumulating one
* or more same-signed infinite values, return the
* correctly-signed infinity stored in the simple sum.
*/
static double computeFinalSum(double[] summands) {
// Better error bounds to add both terms as the final sum
double tmp = summands[0] + summands[1];
double simpleSum = summands[summands.length - 1];
if (Double.isNaN(tmp) && Double.isInfinite(simpleSum))
return simpleSum;
else
return tmp;
}
/**
* Returns a {@code Collector} that produces the arithmetic mean of an integer-valued
* function applied to the input elements. If no elements are present,
* the result is 0.
*
* @param <T> the type of the input elements
* @param mapper a function extracting the property to be summed
* @return a {@code Collector} that produces the sum of a derived property
*/
public static <T> Collector<T, ?, Double>
averagingInt(ToIntFunction<? super T> mapper) {
return new CollectorImpl<>(
() -> new long[2],
(a, t) -> { a[0] += mapper.applyAsInt(t); a[1]++; },
(a, b) -> { a[0] += b[0]; a[1] += b[1]; return a; },
a -> (a[1] == 0) ? 0.0d : (double) a[0] / a[1], CH_NOID);
}
/**
* Returns a {@code Collector} that produces the arithmetic mean of a long-valued
* function applied to the input elements. If no elements are present,
* the result is 0.
*
* @param <T> the type of the input elements
* @param mapper a function extracting the property to be summed
* @return a {@code Collector} that produces the sum of a derived property
*/
public static <T> Collector<T, ?, Double>
averagingLong(ToLongFunction<? super T> mapper) {
return new CollectorImpl<>(
() -> new long[2],
(a, t) -> { a[0] += mapper.applyAsLong(t); a[1]++; },
(a, b) -> { a[0] += b[0]; a[1] += b[1]; return a; },
a -> (a[1] == 0) ? 0.0d : (double) a[0] / a[1], CH_NOID);
}
/**
* Returns a {@code Collector} that produces the arithmetic mean of a double-valued
* function applied to the input elements. If no elements are present,
* the result is 0.
*
* <p>The average returned can vary depending upon the order in which
* values are recorded, due to accumulated rounding error in
* addition of values of differing magnitudes. Values sorted by increasing
* absolute magnitude tend to yield more accurate results. If any recorded
* value is a {@code NaN} or the sum is at any point a {@code NaN} then the
* average will be {@code NaN}.
*
* @implNote The {@code double} format can represent all
* consecutive integers in the range -2<sup>53</sup> to
* 2<sup>53</sup>. If the pipeline has more than 2<sup>53</sup>
* values, the divisor in the average computation will saturate at
* 2<sup>53</sup>, leading to additional numerical errors.
*
* @param <T> the type of the input elements
* @param mapper a function extracting the property to be summed
* @return a {@code Collector} that produces the sum of a derived property
*/
public static <T> Collector<T, ?, Double>
averagingDouble(ToDoubleFunction<? super T> mapper) {
/*
* In the arrays allocated for the collect operation, index 0
* holds the high-order bits of the running sum, index 1 holds
* the low-order bits of the sum computed via compensated
* summation, and index 2 holds the number of values seen.
*/
return new CollectorImpl<>(
() -> new double[4],
(a, t) -> { sumWithCompensation(a, mapper.applyAsDouble(t)); a[2]++; a[3]+= mapper.applyAsDouble(t);},
(a, b) -> { sumWithCompensation(a, b[0]); sumWithCompensation(a, b[1]); a[2] += b[2]; a[3] += b[3]; return a; },
a -> (a[2] == 0) ? 0.0d : (computeFinalSum(a) / a[2]),
CH_NOID);
}
/**
* Returns a {@code Collector} which performs a reduction of its
* input elements under a specified {@code BinaryOperator} using the
* provided identity.
*
* @apiNote
* The {@code reducing()} collectors are most useful when used in a
* multi-level reduction, downstream of {@code groupingBy} or
* {@code partitioningBy}. To perform a simple reduction on a stream,
* use {@link Stream#reduce(Object, BinaryOperator)}} instead.
*
* @param <T> element type for the input and output of the reduction
* @param identity the identity value for the reduction (also, the value
* that is returned when there are no input elements)
* @param op a {@code BinaryOperator<T>} used to reduce the input elements
* @return a {@code Collector} which implements the reduction operation
*
* @see #reducing(BinaryOperator)
* @see #reducing(Object, Function, BinaryOperator)
*/
public static <T> Collector<T, ?, T>
reducing(T identity, BinaryOperator<T> op) {
return new CollectorImpl<>(
boxSupplier(identity),
(a, t) -> { a[0] = op.apply(a[0], t); },
(a, b) -> { a[0] = op.apply(a[0], b[0]); return a; },
a -> a[0],
CH_NOID);
}
@SuppressWarnings("unchecked")
private static <T> Supplier<T[]> boxSupplier(T identity) {
return () -> (T[]) new Object[] { identity };
}
/**
* Returns a {@code Collector} which performs a reduction of its
* input elements under a specified {@code BinaryOperator}. The result
* is described as an {@code Optional<T>}.
*
* @apiNote
* The {@code reducing()} collectors are most useful when used in a
* multi-level reduction, downstream of {@code groupingBy} or
* {@code partitioningBy}. To perform a simple reduction on a stream,
* use {@link Stream#reduce(BinaryOperator)} instead.
*
* <p>For example, given a stream of {@code Person}, to calculate tallest
* person in each city:
* <pre>{@code
* Comparator<Person> byHeight = Comparator.comparing(Person::getHeight);
* Map<City, Person> tallestByCity
* = people.stream().collect(groupingBy(Person::getCity, reducing(BinaryOperator.maxBy(byHeight))));
* }</pre>
*
* @param <T> element type for the input and output of the reduction
* @param op a {@code BinaryOperator<T>} used to reduce the input elements
* @return a {@code Collector} which implements the reduction operation
*
* @see #reducing(Object, BinaryOperator)
* @see #reducing(Object, Function, BinaryOperator)
*/
public static <T> Collector<T, ?, Optional<T>>
reducing(BinaryOperator<T> op) {
class OptionalBox implements Consumer<T> {
T value = null;
boolean present = false;
@Override
public void accept(T t) {
if (present) {
value = op.apply(value, t);
}
else {
value = t;
present = true;
}
}
}
return new CollectorImpl<T, OptionalBox, Optional<T>>(
OptionalBox::new, OptionalBox::accept,
(a, b) -> { if (b.present) a.accept(b.value); return a; },
a -> Optional.ofNullable(a.value), CH_NOID);
}
/**
* Returns a {@code Collector} which performs a reduction of its
* input elements under a specified mapping function and
* {@code BinaryOperator}. This is a generalization of
* {@link #reducing(Object, BinaryOperator)} which allows a transformation
* of the elements before reduction.
*
* @apiNote
* The {@code reducing()} collectors are most useful when used in a
* multi-level reduction, downstream of {@code groupingBy} or
* {@code partitioningBy}. To perform a simple map-reduce on a stream,
* use {@link Stream#map(Function)} and {@link Stream#reduce(Object, BinaryOperator)}
* instead.
*
* <p>For example, given a stream of {@code Person}, to calculate the longest
* last name of residents in each city:
* <pre>{@code
* Comparator<String> byLength = Comparator.comparing(String::length);
* Map<City, String> longestLastNameByCity
* = people.stream().collect(groupingBy(Person::getCity,
* reducing(Person::getLastName, BinaryOperator.maxBy(byLength))));
* }</pre>
*
* @param <T> the type of the input elements
* @param <U> the type of the mapped values
* @param identity the identity value for the reduction (also, the value
* that is returned when there are no input elements)
* @param mapper a mapping function to apply to each input value
* @param op a {@code BinaryOperator<U>} used to reduce the mapped values
* @return a {@code Collector} implementing the map-reduce operation
*
* @see #reducing(Object, BinaryOperator)
* @see #reducing(BinaryOperator)
*/
public static <T, U>
Collector<T, ?, U> reducing(U identity,
Function<? super T, ? extends U> mapper,
BinaryOperator<U> op) {
return new CollectorImpl<>(
boxSupplier(identity),
(a, t) -> { a[0] = op.apply(a[0], mapper.apply(t)); },
(a, b) -> { a[0] = op.apply(a[0], b[0]); return a; },
a -> a[0], CH_NOID);
}
/**
* Returns a {@code Collector} implementing a "group by" operation on
* input elements of type {@code T}, grouping elements according to a
* classification function, and returning the results in a {@code Map}.
*
* <p>The classification function maps elements to some key type {@code K}.
* The collector produces a {@code Map<K, List<T>>} whose keys are the
* values resulting from applying the classification function to the input
* elements, and whose corresponding values are {@code List}s containing the
* input elements which map to the associated key under the classification
* function.
*
* <p>There are no guarantees on the type, mutability, serializability, or
* thread-safety of the {@code Map} or {@code List} objects returned.
* @implSpec
* This produces a result similar to:
* <pre>{@code
* groupingBy(classifier, toList());
* }</pre>
*
* @implNote
* The returned {@code Collector} is not concurrent. For parallel stream
* pipelines, the {@code combiner} function operates by merging the keys
* from one map into another, which can be an expensive operation. If
* preservation of the order in which elements appear in the resulting {@code Map}
* collector is not required, using {@link #groupingByConcurrent(Function)}
* may offer better parallel performance.
*
* @param <T> the type of the input elements
* @param <K> the type of the keys
* @param classifier the classifier function mapping input elements to keys
* @return a {@code Collector} implementing the group-by operation
*
* @see #groupingBy(Function, Collector)
* @see #groupingBy(Function, Supplier, Collector)
* @see #groupingByConcurrent(Function)
*/
public static <T, K> Collector<T, ?, Map<K, List<T>>>
groupingBy(Function<? super T, ? extends K> classifier) {
return groupingBy(classifier, toList());
}
/**
* Returns a {@code Collector} implementing a cascaded "group by" operation
* on input elements of type {@code T}, grouping elements according to a
* classification function, and then performing a reduction operation on
* the values associated with a given key using the specified downstream
* {@code Collector}.
*
* <p>The classification function maps elements to some key type {@code K}.
* The downstream collector operates on elements of type {@code T} and
* produces a result of type {@code D}. The resulting collector produces a
* {@code Map<K, D>}.
*
* <p>There are no guarantees on the type, mutability,
* serializability, or thread-safety of the {@code Map} returned.
*
* <p>For example, to compute the set of last names of people in each city:
* <pre>{@code
* Map<City, Set<String>> namesByCity
* = people.stream().collect(groupingBy(Person::getCity,
* mapping(Person::getLastName, toSet())));
* }</pre>
*
* @implNote
* The returned {@code Collector} is not concurrent. For parallel stream
* pipelines, the {@code combiner} function operates by merging the keys
* from one map into another, which can be an expensive operation. If
* preservation of the order in which elements are presented to the downstream
* collector is not required, using {@link #groupingByConcurrent(Function, Collector)}
* may offer better parallel performance.
*
* @param <T> the type of the input elements
* @param <K> the type of the keys
* @param <A> the intermediate accumulation type of the downstream collector
* @param <D> the result type of the downstream reduction
* @param classifier a classifier function mapping input elements to keys
* @param downstream a {@code Collector} implementing the downstream reduction
* @return a {@code Collector} implementing the cascaded group-by operation
* @see #groupingBy(Function)
*
* @see #groupingBy(Function, Supplier, Collector)
* @see #groupingByConcurrent(Function, Collector)
*/
public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream) {
return groupingBy(classifier, HashMap::new, downstream);
}
/**
* Returns a {@code Collector} implementing a cascaded "group by" operation
* on input elements of type {@code T}, grouping elements according to a
* classification function, and then performing a reduction operation on
* the values associated with a given key using the specified downstream
* {@code Collector}. The {@code Map} produced by the Collector is created
* with the supplied factory function.
*
* <p>The classification function maps elements to some key type {@code K}.
* The downstream collector operates on elements of type {@code T} and
* produces a result of type {@code D}. The resulting collector produces a
* {@code Map<K, D>}.
*
* <p>For example, to compute the set of last names of people in each city,
* where the city names are sorted:
* <pre>{@code
* Map<City, Set<String>> namesByCity
* = people.stream().collect(groupingBy(Person::getCity, TreeMap::new,
* mapping(Person::getLastName, toSet())));
* }</pre>
*
* @implNote
* The returned {@code Collector} is not concurrent. For parallel stream
* pipelines, the {@code combiner} function operates by merging the keys
* from one map into another, which can be an expensive operation. If
* preservation of the order in which elements are presented to the downstream
* collector is not required, using {@link #groupingByConcurrent(Function, Supplier, Collector)}
* may offer better parallel performance.
*
* @param <T> the type of the input elements
* @param <K> the type of the keys
* @param <A> the intermediate accumulation type of the downstream collector
* @param <D> the result type of the downstream reduction
* @param <M> the type of the resulting {@code Map}
* @param classifier a classifier function mapping input elements to keys
* @param downstream a {@code Collector} implementing the downstream reduction
* @param mapFactory a function which, when called, produces a new empty
* {@code Map} of the desired type
* @return a {@code Collector} implementing the cascaded group-by operation
*
* @see #groupingBy(Function, Collector)
* @see #groupingBy(Function)
* @see #groupingByConcurrent(Function, Supplier, Collector)
*/
public static <T, K, D, A, M extends Map<K, D>>
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream) {
Supplier<A> downstreamSupplier = downstream.supplier();
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BiConsumer<Map<K, A>, T> accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A container = m.computeIfAbsent(key, k -> downstreamSupplier.get());
downstreamAccumulator.accept(container, t);
};
BinaryOperator<Map<K, A>> merger = Collectors.<K, A, Map<K, A>>mapMerger(downstream.combiner());
@SuppressWarnings("unchecked")
Supplier<Map<K, A>> mangledFactory = (Supplier<Map<K, A>>) mapFactory;
if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(mangledFactory, accumulator, merger, CH_ID);
}
else {
@SuppressWarnings("unchecked")
Function<A, A> downstreamFinisher = (Function<A, A>) downstream.finisher();
Function<Map<K, A>, M> finisher = intermediate -> {
intermediate.replaceAll((k, v) -> downstreamFinisher.apply(v));
@SuppressWarnings("unchecked")
M castResult = (M) intermediate;
return castResult;
};
return new CollectorImpl<>(mangledFactory, accumulator, merger, finisher, CH_NOID);
}
}
/**
* Returns a concurrent {@code Collector} implementing a "group by"
* operation on input elements of type {@code T}, grouping elements
* according to a classification function.
*
* <p>This is a {@link Collector.Characteristics#CONCURRENT concurrent} and
* {@link Collector.Characteristics#UNORDERED unordered} Collector.
*
* <p>The classification function maps elements to some key type {@code K}.
* The collector produces a {@code ConcurrentMap<K, List<T>>} whose keys are the
* values resulting from applying the classification function to the input
* elements, and whose corresponding values are {@code List}s containing the
* input elements which map to the associated key under the classification
* function.
*
* <p>There are no guarantees on the type, mutability, or serializability
* of the {@code Map} or {@code List} objects returned, or of the
* thread-safety of the {@code List} objects returned.
* @implSpec
* This produces a result similar to:
* <pre>{@code
* groupingByConcurrent(classifier, toList());
* }</pre>
*
* @param <T> the type of the input elements
* @param <K> the type of the keys
* @param classifier a classifier function mapping input elements to keys
* @return a concurrent, unordered {@code Collector} implementing the group-by operation
*
* @see #groupingBy(Function)
* @see #groupingByConcurrent(Function, Collector)
* @see #groupingByConcurrent(Function, Supplier, Collector)
*/
public static <T, K>
Collector<T, ?, ConcurrentMap<K, List<T>>>
groupingByConcurrent(Function<? super T, ? extends K> classifier) {
return groupingByConcurrent(classifier, ConcurrentHashMap::new, toList());
}
/**
* Returns a concurrent {@code Collector} implementing a cascaded "group by"
* operation on input elements of type {@code T}, grouping elements
* according to a classification function, and then performing a reduction
* operation on the values associated with a given key using the specified
* downstream {@code Collector}.
*
* <p>This is a {@link Collector.Characteristics#CONCURRENT concurrent} and
* {@link Collector.Characteristics#UNORDERED unordered} Collector.
*
* <p>The classification function maps elements to some key type {@code K}.
* The downstream collector operates on elements of type {@code T} and
* produces a result of type {@code D}. The resulting collector produces a
* {@code Map<K, D>}.
*
* <p>For example, to compute the set of last names of people in each city,
* where the city names are sorted:
* <pre>{@code
* ConcurrentMap<City, Set<String>> namesByCity
* = people.stream().collect(groupingByConcurrent(Person::getCity,
* mapping(Person::getLastName, toSet())));
* }</pre>
*
* @param <T> the type of the input elements
* @param <K> the type of the keys
* @param <A> the intermediate accumulation type of the downstream collector
* @param <D> the result type of the downstream reduction
* @param classifier a classifier function mapping input elements to keys
* @param downstream a {@code Collector} implementing the downstream reduction
* @return a concurrent, unordered {@code Collector} implementing the cascaded group-by operation
*
* @see #groupingBy(Function, Collector)
* @see #groupingByConcurrent(Function)
* @see #groupingByConcurrent(Function, Supplier, Collector)
*/
public static <T, K, A, D>
Collector<T, ?, ConcurrentMap<K, D>> groupingByConcurrent(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream) {
return groupingByConcurrent(classifier, ConcurrentHashMap::new, downstream);
}
/**
* Returns a concurrent {@code Collector} implementing a cascaded "group by"
* operation on input elements of type {@code T}, grouping elements
* according to a classification function, and then performing a reduction
* operation on the values associated with a given key using the specified
* downstream {@code Collector}. The {@code ConcurrentMap} produced by the
* Collector is created with the supplied factory function.
*
* <p>This is a {@link Collector.Characteristics#CONCURRENT concurrent} and
* {@link Collector.Characteristics#UNORDERED unordered} Collector.
*
* <p>The classification function maps elements to some key type {@code K}.
* The downstream collector operates on elements of type {@code T} and
* produces a result of type {@code D}. The resulting collector produces a
* {@code Map<K, D>}.
*
* <p>For example, to compute the set of last names of people in each city,
* where the city names are sorted:
* <pre>{@code
* ConcurrentMap<City, Set<String>> namesByCity
* = people.stream().collect(groupingBy(Person::getCity, ConcurrentSkipListMap::new,
* mapping(Person::getLastName, toSet())));
* }</pre>
*
*
* @param <T> the type of the input elements
* @param <K> the type of the keys
* @param <A> the intermediate accumulation type of the downstream collector
* @param <D> the result type of the downstream reduction
* @param <M> the type of the resulting {@code ConcurrentMap}
* @param classifier a classifier function mapping input elements to keys
* @param downstream a {@code Collector} implementing the downstream reduction
* @param mapFactory a function which, when called, produces a new empty
* {@code ConcurrentMap} of the desired type
* @return a concurrent, unordered {@code Collector} implementing the cascaded group-by operation
*
* @see #groupingByConcurrent(Function)
* @see #groupingByConcurrent(Function, Collector)
* @see #groupingBy(Function, Supplier, Collector)
*/
public static <T, K, A, D, M extends ConcurrentMap<K, D>>
Collector<T, ?, M> groupingByConcurrent(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream) {
Supplier<A> downstreamSupplier = downstream.supplier();
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BinaryOperator<ConcurrentMap<K, A>> merger = Collectors.<K, A, ConcurrentMap<K, A>>mapMerger(downstream.combiner());
@SuppressWarnings("unchecked")
Supplier<ConcurrentMap<K, A>> mangledFactory = (Supplier<ConcurrentMap<K, A>>) mapFactory;
BiConsumer<ConcurrentMap<K, A>, T> accumulator;
if (downstream.characteristics().contains(Collector.Characteristics.CONCURRENT)) {
accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A resultContainer = m.computeIfAbsent(key, k -> downstreamSupplier.get());
downstreamAccumulator.accept(resultContainer, t);
};
}
else {
accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A resultContainer = m.computeIfAbsent(key, k -> downstreamSupplier.get());
synchronized (resultContainer) {
downstreamAccumulator.accept(resultContainer, t);
}
};
}
if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(mangledFactory, accumulator, merger, CH_CONCURRENT_ID);
}
else {
@SuppressWarnings("unchecked")
Function<A, A> downstreamFinisher = (Function<A, A>) downstream.finisher();
Function<ConcurrentMap<K, A>, M> finisher = intermediate -> {
intermediate.replaceAll((k, v) -> downstreamFinisher.apply(v));
@SuppressWarnings("unchecked")
M castResult = (M) intermediate;
return castResult;
};
return new CollectorImpl<>(mangledFactory, accumulator, merger, finisher, CH_CONCURRENT_NOID);
}
}
/**
* Returns a {@code Collector} which partitions the input elements according
* to a {@code Predicate}, and organizes them into a
* {@code Map<Boolean, List<T>>}.
*
* There are no guarantees on the type, mutability,
* serializability, or thread-safety of the {@code Map} returned.
*
* @param <T> the type of the input elements
* @param predicate a predicate used for classifying input elements
* @return a {@code Collector} implementing the partitioning operation
*
* @see #partitioningBy(Predicate, Collector)
*/
public static <T>
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {
return partitioningBy(predicate, toList());
}
/**
* Returns a {@code Collector} which partitions the input elements according
* to a {@code Predicate}, reduces the values in each partition according to
* another {@code Collector}, and organizes them into a
* {@code Map<Boolean, D>} whose values are the result of the downstream
* reduction.
*
* <p>There are no guarantees on the type, mutability,
* serializability, or thread-safety of the {@code Map} returned.
*
* @param <T> the type of the input elements
* @param <A> the intermediate accumulation type of the downstream collector
* @param <D> the result type of the downstream reduction
* @param predicate a predicate used for classifying input elements
* @param downstream a {@code Collector} implementing the downstream
* reduction
* @return a {@code Collector} implementing the cascaded partitioning
* operation
*
* @see #partitioningBy(Predicate)
*/
public static <T, D, A>
Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate,
Collector<? super T, A, D> downstream) {
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BiConsumer<Partition<A>, T> accumulator = (result, t) ->
downstreamAccumulator.accept(predicate.test(t) ? result.forTrue : result.forFalse, t);
BinaryOperator<A> op = downstream.combiner();
BinaryOperator<Partition<A>> merger = (left, right) ->
new Partition<>(op.apply(left.forTrue, right.forTrue),
op.apply(left.forFalse, right.forFalse));
Supplier<Partition<A>> supplier = () ->
new Partition<>(downstream.supplier().get(),
downstream.supplier().get());
if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(supplier, accumulator, merger, CH_ID);
}
else {
Function<Partition<A>, Map<Boolean, D>> finisher = par ->
new Partition<>(downstream.finisher().apply(par.forTrue),
downstream.finisher().apply(par.forFalse));
return new CollectorImpl<>(supplier, accumulator, merger, finisher, CH_NOID);
}
}
/**
* Returns a {@code Collector} that accumulates elements into a
* {@code Map} whose keys and values are the result of applying the provided
* mapping functions to the input elements.
*
* <p>If the mapped keys contains duplicates (according to
* {@link Object#equals(Object)}), an {@code IllegalStateException} is
* thrown when the collection operation is performed. If the mapped keys
* may have duplicates, use {@link #toMap(Function, Function, BinaryOperator)}
* instead.
*
* @apiNote
* It is common for either the key or the value to be the input elements.
* In this case, the utility method
* {@link java.util.function.Function#identity()} may be helpful.
* For example, the following produces a {@code Map} mapping
* students to their grade point average:
* <pre>{@code
* Map<Student, Double> studentToGPA
* students.stream().collect(toMap(Functions.identity(),
* student -> computeGPA(student)));
* }</pre>
* And the following produces a {@code Map} mapping a unique identifier to
* students:
* <pre>{@code
* Map<String, Student> studentIdToStudent
* students.stream().collect(toMap(Student::getId,
* Functions.identity());
* }</pre>
*
* @implNote
* The returned {@code Collector} is not concurrent. For parallel stream
* pipelines, the {@code combiner} function operates by merging the keys
* from one map into another, which can be an expensive operation. If it is
* not required that results are inserted into the {@code Map} in encounter
* order, using {@link #toConcurrentMap(Function, Function)}
* may offer better parallel performance.
*
* @param <T> the type of the input elements
* @param <K> the output type of the key mapping function
* @param <U> the output type of the value mapping function
* @param keyMapper a mapping function to produce keys
* @param valueMapper a mapping function to produce values
* @return a {@code Collector} which collects elements into a {@code Map}
* whose keys and values are the result of applying mapping functions to
* the input elements
*
* @see #toMap(Function, Function, BinaryOperator)
* @see #toMap(Function, Function, BinaryOperator, Supplier)
* @see #toConcurrentMap(Function, Function)
*/
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper) {
return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new);
}
/**
* Returns a {@code Collector} that accumulates elements into a
* {@code Map} whose keys and values are the result of applying the provided
* mapping functions to the input elements.
*
* <p>If the mapped
* keys contains duplicates (according to {@link Object#equals(Object)}),
* the value mapping function is applied to each equal element, and the
* results are merged using the provided merging function.
*
* @apiNote
* There are multiple ways to deal with collisions between multiple elements
* mapping to the same key. The other forms of {@code toMap} simply use
* a merge function that throws unconditionally, but you can easily write
* more flexible merge policies. For example, if you have a stream
* of {@code Person}, and you want to produce a "phone book" mapping name to
* address, but it is possible that two persons have the same name, you can
* do as follows to gracefully deals with these collisions, and produce a
* {@code Map} mapping names to a concatenated list of addresses:
* <pre>{@code
* Map<String, String> phoneBook
* people.stream().collect(toMap(Person::getName,
* Person::getAddress,
* (s, a) -> s + ", " + a));
* }</pre>
*
* @implNote
* The returned {@code Collector} is not concurrent. For parallel stream
* pipelines, the {@code combiner} function operates by merging the keys
* from one map into another, which can be an expensive operation. If it is
* not required that results are merged into the {@code Map} in encounter
* order, using {@link #toConcurrentMap(Function, Function, BinaryOperator)}
* may offer better parallel performance.
*
* @param <T> the type of the input elements
* @param <K> the output type of the key mapping function
* @param <U> the output type of the value mapping function
* @param keyMapper a mapping function to produce keys
* @param valueMapper a mapping function to produce values
* @param mergeFunction a merge function, used to resolve collisions between
* values associated with the same key, as supplied
* to {@link Map#merge(Object, Object, BiFunction)}
* @return a {@code Collector} which collects elements into a {@code Map}
* whose keys are the result of applying a key mapping function to the input
* elements, and whose values are the result of applying a value mapping
* function to all input elements equal to the key and combining them
* using the merge function
*
* @see #toMap(Function, Function)
* @see #toMap(Function, Function, BinaryOperator, Supplier)
* @see #toConcurrentMap(Function, Function, BinaryOperator)
*/
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction) {
return toMap(keyMapper, valueMapper, mergeFunction, HashMap::new);
}
/**
* Returns a {@code Collector} that accumulates elements into a
* {@code Map} whose keys and values are the result of applying the provided
* mapping functions to the input elements.
*
* <p>If the mapped
* keys contains duplicates (according to {@link Object#equals(Object)}),
* the value mapping function is applied to each equal element, and the
* results are merged using the provided merging function. The {@code Map}
* is created by a provided supplier function.
*
* @implNote
* The returned {@code Collector} is not concurrent. For parallel stream
* pipelines, the {@code combiner} function operates by merging the keys
* from one map into another, which can be an expensive operation. If it is
* not required that results are merged into the {@code Map} in encounter
* order, using {@link #toConcurrentMap(Function, Function, BinaryOperator, Supplier)}
* may offer better parallel performance.
*
* @param <T> the type of the input elements
* @param <K> the output type of the key mapping function
* @param <U> the output type of the value mapping function
* @param <M> the type of the resulting {@code Map}
* @param keyMapper a mapping function to produce keys
* @param valueMapper a mapping function to produce values
* @param mergeFunction a merge function, used to resolve collisions between
* values associated with the same key, as supplied
* to {@link Map#merge(Object, Object, BiFunction)}
* @param mapSupplier a function which returns a new, empty {@code Map} into
* which the results will be inserted
* @return a {@code Collector} which collects elements into a {@code Map}
* whose keys are the result of applying a key mapping function to the input
* elements, and whose values are the result of applying a value mapping
* function to all input elements equal to the key and combining them
* using the merge function
*
* @see #toMap(Function, Function)
* @see #toMap(Function, Function, BinaryOperator)
* @see #toConcurrentMap(Function, Function, BinaryOperator, Supplier)
*/
public static <T, K, U, M extends Map<K, U>>
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
BiConsumer<M, T> accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
}
/**
* Returns a concurrent {@code Collector} that accumulates elements into a
* {@code ConcurrentMap} whose keys and values are the result of applying
* the provided mapping functions to the input elements.
*
* <p>If the mapped keys contains duplicates (according to
* {@link Object#equals(Object)}), an {@code IllegalStateException} is
* thrown when the collection operation is performed. If the mapped keys
* may have duplicates, use
* {@link #toConcurrentMap(Function, Function, BinaryOperator)} instead.
*
* @apiNote
* It is common for either the key or the value to be the input elements.
* In this case, the utility method
* {@link java.util.function.Function#identity()} may be helpful.
* For example, the following produces a {@code Map} mapping
* students to their grade point average:
* <pre>{@code
* Map<Student, Double> studentToGPA
* students.stream().collect(toMap(Functions.identity(),
* student -> computeGPA(student)));
* }</pre>
* And the following produces a {@code Map} mapping a unique identifier to
* students:
* <pre>{@code
* Map<String, Student> studentIdToStudent
* students.stream().collect(toConcurrentMap(Student::getId,
* Functions.identity());
* }</pre>
*
* <p>This is a {@link Collector.Characteristics#CONCURRENT concurrent} and
* {@link Collector.Characteristics#UNORDERED unordered} Collector.
*
* @param <T> the type of the input elements
* @param <K> the output type of the key mapping function
* @param <U> the output type of the value mapping function
* @param keyMapper the mapping function to produce keys
* @param valueMapper the mapping function to produce values
* @return a concurrent, unordered {@code Collector} which collects elements into a
* {@code ConcurrentMap} whose keys are the result of applying a key mapping
* function to the input elements, and whose values are the result of
* applying a value mapping function to the input elements
*
* @see #toMap(Function, Function)
* @see #toConcurrentMap(Function, Function, BinaryOperator)
* @see #toConcurrentMap(Function, Function, BinaryOperator, Supplier)
*/
public static <T, K, U>
Collector<T, ?, ConcurrentMap<K,U>> toConcurrentMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper) {
return toConcurrentMap(keyMapper, valueMapper, throwingMerger(), ConcurrentHashMap::new);
}
/**
* Returns a concurrent {@code Collector} that accumulates elements into a
* {@code ConcurrentMap} whose keys and values are the result of applying
* the provided mapping functions to the input elements.
*
* <p>If the mapped keys contains duplicates (according to {@link Object#equals(Object)}),
* the value mapping function is applied to each equal element, and the
* results are merged using the provided merging function.
*
* @apiNote
* There are multiple ways to deal with collisions between multiple elements
* mapping to the same key. The other forms of {@code toConcurrentMap} simply use
* a merge function that throws unconditionally, but you can easily write
* more flexible merge policies. For example, if you have a stream
* of {@code Person}, and you want to produce a "phone book" mapping name to
* address, but it is possible that two persons have the same name, you can
* do as follows to gracefully deals with these collisions, and produce a
* {@code Map} mapping names to a concatenated list of addresses:
* <pre>{@code
* Map<String, String> phoneBook
* people.stream().collect(toConcurrentMap(Person::getName,
* Person::getAddress,
* (s, a) -> s + ", " + a));
* }</pre>
*
* <p>This is a {@link Collector.Characteristics#CONCURRENT concurrent} and
* {@link Collector.Characteristics#UNORDERED unordered} Collector.
*
* @param <T> the type of the input elements
* @param <K> the output type of the key mapping function
* @param <U> the output type of the value mapping function
* @param keyMapper a mapping function to produce keys
* @param valueMapper a mapping function to produce values
* @param mergeFunction a merge function, used to resolve collisions between
* values associated with the same key, as supplied
* to {@link Map#merge(Object, Object, BiFunction)}
* @return a concurrent, unordered {@code Collector} which collects elements into a
* {@code ConcurrentMap} whose keys are the result of applying a key mapping
* function to the input elements, and whose values are the result of
* applying a value mapping function to all input elements equal to the key
* and combining them using the merge function
*
* @see #toConcurrentMap(Function, Function)
* @see #toConcurrentMap(Function, Function, BinaryOperator, Supplier)
* @see #toMap(Function, Function, BinaryOperator)
*/
public static <T, K, U>
Collector<T, ?, ConcurrentMap<K,U>>
toConcurrentMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction) {
return toConcurrentMap(keyMapper, valueMapper, mergeFunction, ConcurrentHashMap::new);
}
/**
* Returns a concurrent {@code Collector} that accumulates elements into a
* {@code ConcurrentMap} whose keys and values are the result of applying
* the provided mapping functions to the input elements.
*
* <p>If the mapped keys contains duplicates (according to {@link Object#equals(Object)}),
* the value mapping function is applied to each equal element, and the
* results are merged using the provided merging function. The
* {@code ConcurrentMap} is created by a provided supplier function.
*
* <p>This is a {@link Collector.Characteristics#CONCURRENT concurrent} and
* {@link Collector.Characteristics#UNORDERED unordered} Collector.
*
* @param <T> the type of the input elements
* @param <K> the output type of the key mapping function
* @param <U> the output type of the value mapping function
* @param <M> the type of the resulting {@code ConcurrentMap}
* @param keyMapper a mapping function to produce keys
* @param valueMapper a mapping function to produce values
* @param mergeFunction a merge function, used to resolve collisions between
* values associated with the same key, as supplied
* to {@link Map#merge(Object, Object, BiFunction)}
* @param mapSupplier a function which returns a new, empty {@code Map} into
* which the results will be inserted
* @return a concurrent, unordered {@code Collector} which collects elements into a
* {@code ConcurrentMap} whose keys are the result of applying a key mapping
* function to the input elements, and whose values are the result of
* applying a value mapping function to all input elements equal to the key
* and combining them using the merge function
*
* @see #toConcurrentMap(Function, Function)
* @see #toConcurrentMap(Function, Function, BinaryOperator)
* @see #toMap(Function, Function, BinaryOperator, Supplier)
*/
public static <T, K, U, M extends ConcurrentMap<K, U>>
Collector<T, ?, M> toConcurrentMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
BiConsumer<M, T> accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_CONCURRENT_ID);
}
/**
* Returns a {@code Collector} which applies an {@code int}-producing
* mapping function to each input element, and returns summary statistics
* for the resulting values.
*
* @param <T> the type of the input elements
* @param mapper a mapping function to apply to each element
* @return a {@code Collector} implementing the summary-statistics reduction
*
* @see #summarizingDouble(ToDoubleFunction)
* @see #summarizingLong(ToLongFunction)
*/
public static <T>
Collector<T, ?, IntSummaryStatistics> summarizingInt(ToIntFunction<? super T> mapper) {
return new CollectorImpl<T, IntSummaryStatistics, IntSummaryStatistics>(
IntSummaryStatistics::new,
(r, t) -> r.accept(mapper.applyAsInt(t)),
(l, r) -> { l.combine(r); return l; }, CH_ID);
}
/**
* Returns a {@code Collector} which applies an {@code long}-producing
* mapping function to each input element, and returns summary statistics
* for the resulting values.
*
* @param <T> the type of the input elements
* @param mapper the mapping function to apply to each element
* @return a {@code Collector} implementing the summary-statistics reduction
*
* @see #summarizingDouble(ToDoubleFunction)
* @see #summarizingInt(ToIntFunction)
*/
public static <T>
Collector<T, ?, LongSummaryStatistics> summarizingLong(ToLongFunction<? super T> mapper) {
return new CollectorImpl<T, LongSummaryStatistics, LongSummaryStatistics>(
LongSummaryStatistics::new,
(r, t) -> r.accept(mapper.applyAsLong(t)),
(l, r) -> { l.combine(r); return l; }, CH_ID);
}
/**
* Returns a {@code Collector} which applies an {@code double}-producing
* mapping function to each input element, and returns summary statistics
* for the resulting values.
*
* @param <T> the type of the input elements
* @param mapper a mapping function to apply to each element
* @return a {@code Collector} implementing the summary-statistics reduction
*
* @see #summarizingLong(ToLongFunction)
* @see #summarizingInt(ToIntFunction)
*/
public static <T>
Collector<T, ?, DoubleSummaryStatistics> summarizingDouble(ToDoubleFunction<? super T> mapper) {
return new CollectorImpl<T, DoubleSummaryStatistics, DoubleSummaryStatistics>(
DoubleSummaryStatistics::new,
(r, t) -> r.accept(mapper.applyAsDouble(t)),
(l, r) -> { l.combine(r); return l; }, CH_ID);
}
/**
* Implementation class used by partitioningBy.
*/
private static final class Partition<T>
extends AbstractMap<Boolean, T>
implements Map<Boolean, T> {
final T forTrue;
final T forFalse;
Partition(T forTrue, T forFalse) {
this.forTrue = forTrue;
this.forFalse = forFalse;
}
@Override
public Set<Map.Entry<Boolean, T>> entrySet() {
return new AbstractSet<Map.Entry<Boolean, T>>() {
@Override
public Iterator<Map.Entry<Boolean, T>> iterator() {
Map.Entry<Boolean, T> falseEntry = new SimpleImmutableEntry<>(false, forFalse);
Map.Entry<Boolean, T> trueEntry = new SimpleImmutableEntry<>(true, forTrue);
return Arrays.asList(falseEntry, trueEntry).iterator();
}
@Override
public int size() {
return 2;
}
};
}
}
}
; }, CH_ID);
}
/**
* Returns a {@code Collector} which applies an {@code long}-producing
* mapping function to each input element, and returns summary statistics
* for the resulting values.
*
* @param <T> the type of the input elements
* @param mapper the mapping function to apply to each element
* @return a {@code Collector} implementing the summary-statistics reduction
*
* @see #summarizingDouble(ToDoubleFunction)
* @see #summarizingInt(ToIntFunction)
*/
public static <T>
Collector<T, ?, LongSummaryStatistics> summarizingLong(ToLongFunction<? super T> mapper) {
return new CollectorImpl<T, LongSummaryStatistics, LongSummaryStatistics>(
LongSummaryStatistics::new,
(r, t) -> r.accept(mapper.applyAsLong(t)),
(l, r) -> { l.combine(r); return l; }, CH_ID);
}
/**
* Returns a {@code Collector} which applies an {@code double}-producing
* mapping function to each input element, and returns summary statistics
* for the resulting values.
*
* @param <T> the type of the input elements
* @param mapper a mapping function to apply to each element
* @return a {@code Collector} implementing the summary-statistics reduction
*
* @see #summarizingLong(ToLongFunction)
* @see #summarizingInt(ToIntFunction)
*/
public static <T>
Collector<T, ?, DoubleSummaryStatistics> summarizingDouble(ToDoubleFunction<? super T> mapper) {
return new CollectorImpl<T, DoubleSummaryStatistics, DoubleSummaryStatistics>(
DoubleSummaryStatistics::new,
(r, t) -> r.accept(mapper.applyAsDouble(t)),
(l, r) -> { l.combine(r); return l; }, CH_ID);
}
/**
* Implementation class used by partitioningBy.
*/
private static final class Partition<T>
extends AbstractMap<Boolean, T>
implements Map<Boolean, T> {
final T forTrue;
final T forFalse;
Partition(T forTrue, T forFalse) {
this.forTrue = forTrue;
this.forFalse = forFalse;
}
@Override
public Set<Map.Entry<Boolean, T>> entrySet() {
return new AbstractSet<Map.Entry<Boolean, T>>() {
@Override
public Iterator<Map.Entry<Boolean, T>> iterator() {
Map.Entry<Boolean, T> falseEntry = new SimpleImmutableEntry<>(false, forFalse);
Map.Entry<Boolean, T> trueEntry = new SimpleImmutableEntry<>(true, forTrue);
return Arrays.asList(falseEntry, trueEntry).iterator();
}
@Override
public int size() {
return 2;
}
};
}
}
}















 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









