







#golang面试知识点
##基础篇
-
go中有哪些关键字
package: 包声明
import: 引入包
func: 定义函数和方法
return: 从函数返回
defer: 在函数退出之前执行
var: 变量声明
const: 常量声明
interface: 声明接口类型
struct: 声明结构体类型
chan: 声明 channel类型
map: 声明map数据类型
type: 声明自定义类型
break, case, continue, for, fallthrough, else, if, switch, goto, default: 流程控制
range: 读取slice, map, channel数据
go: 创建goroutine
select: 选择不同类型的case通讯 -
go中有哪些数据类型:
基础数据类型:
1.数值类型
①整数类型
②小数类型
2.布尔类型
3.字符类型
4.字符串类型复杂数据类型:
1.指针
2.数组
3.结构体
4.管道
5.切片
6.接口
7.map
8.函数 -
go 方法与函数的区别?
函数是没有接收者的;
方法是有接收者的
方法:
func (t *T) add(a, b int) int {
return a + b
}
//其中T是自定义类型或者结构体, 不能是基础数据类型int等
函数:
func add(a, b int) int {
return a + b
}
- go 方法接收者 和 指针接收者的区别?
如果方法的接收者是指针类型, 无论调用者是对象还是对象指针, 修改的都是对象本身, 会影响调用者
如果方法的接收者是值类型, 无论调用者是对象还是对象指针, 修改的都是对象的副本, 不影响调用者
通常我们使用指针类型作为方法的接收者的理由:
* 使用指针类型能够修改调用者的值
* 使用指针类型可以避免每次调用函数复制参数, 更加高效
-
go 函数返回局部变量的指针是否内存安全?
go中是安全的.
编译器将会对每个局部变量进行逃逸分析. 如果发现局部变量的作用域超出该函数, 则不会分配在栈上,而是直接分配在堆上, 因为不在栈区, 即使释放函数, 其内容也不会受影响 -
go 函数参数传递到底是值传递还是引用传递?
其实都是值传递
参数如果是非引用类型(int, string, struct等这些), 这样就在函数中无法修改原内容数据;
如果是引用类型(指针,map,slice,chan等这些), 这样就可以修改原内容数据. -
go defer关键字的实现原理?
定义: defer能推迟某些函数调用, 推迟到当前函数返回前才执行, defer与panic和recover结合, 形成了 go语言的异常捕获机制.
使用场景: defer语句经常用于成对的操作, 如文件句柄关闭, 连接关闭, 释放锁实现原理: 编译器会直接将defer函数直接插入到函数的尾部
return和defer哪个先执行? defer如果修改return的值生效吗?
return先执行, 如果返回值有命名, 生效, 如果没有命名, 不生效
详见: https://blog.csdn.net/qq_37102984/article/details/128946146 -
go 内置函数 make和new 的区别?
new和make函数都是用来分配内存的
var声明值类型变量时, 系统默认为其分配内存空间, 并赋该类型的零值
比如布尔, 数字, 字符串, 结构体区别:
- make 只能用来分配及初始化类型为 slice, map, chan的数据
new 可以分配任意类型的数据, 并置零 - make函数返回的是 slice,map, chan类型本身
new函数返回一个指向该类型内存地址的指针
- make 只能用来分配及初始化类型为 slice, map, chan的数据
-
slice的底层实现原理
底层是数组. 结构体源码如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
slice占用24个字节
array: 指向底层数组的指针, 占用8个字节
len: 切片的长度, 占用8个字节
cap: 切片的容量, cap >= len, 占用8个字节
-
array和slice的区别?
1. 长度不同
数组初始化必须指定长度, 并且长度固定
切片长度不固定, 可以追加元素, 并随着追加进行扩容
2. 函数传参不同
数组为值类型, 切片为引用类型
3. 计算长度方式不同
数组需要遍历计算数组长度, 时间复杂度为O(n)
切片包含len字段, 直接获取切片长度, 时间复杂度为O(1) -
slice 的深拷贝和浅拷贝?
深拷贝: 拷贝的是数据本身, 创建一个新对象
实现深拷贝的方式:
1.copy(slice2, slice1)
2.遍历append赋值
浅拷贝: 拷贝的是数据地址, 只复制指向的对象的指针.
实现浅拷贝:
直接引用赋值
slice2 := slice1 -
slice扩容机制?
切片添加元素容量不足时发生扩容, 规则如下:
1. 如果新申请的容量比原有两倍还打, 直接扩容为新申请的容量
2. 如果原有 slice长度 < 1024, 那么库容为原来的 2倍
3. 如果原 slice长度大 >= 1024, 那么库容为原来的 1.25倍 -
slice是不是线程安全的?
不是. slice底层不支持并发读写. 但不会报错, 如果直接并发读写原生map会报错 -
map的底层实现原理?
map是一个指针, 占用8个字节, 指向 hmap结构体
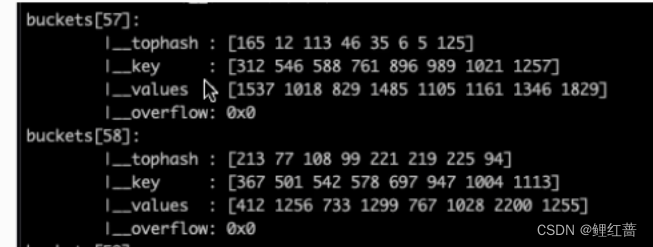
源码包中 src/runtime/map.go 定义了 hmap的数据结构:
hmap包含若干个结构为 bmap的数组,
每个 bmap底层都采用链表结构, bmap通常叫bucket(桶),
每个bucket(桶)存储8个键值对,
如果当前bucket(桶)已经满了, 但是还要向该桶添加元素, 就会以链表节点的形式, 创建一个溢出桶添加在当前桶后面

通过元素的哈希值低8位, 判断元素该放入哪个桶,
通过元素的哈希值高8位置, 判断放入该桶8个位置的哪个位置
在桶中key, value是分开放的, 目的是符合内存对齐, 减少内存浪费
- map遍历为什么是无序的
1. map在遍历时, 并不固定从0号桶开始遍历, 会随机选桶进行遍历, 再从8个位置中随机获取元素
2. map在扩容后, 发生 key搬迁, 当前桶中的key可能搬迁到其它桶中, 这样每次遍历的结果肯定不同了
map本身是无序的, 且遍历时顺序还会被随机化, 如果想顺序遍历map, 需对 mapkey先排序, 再按照 key的顺序遍历 map
16. map为什么是非线程安全的?
map默认为非线程安全的, 并发读写会直接报 panic.
原因: 多个 goroutine操作同一个 map的场景并不多, 设置为并发安全的会损失性能
如果要实现并发安全的map, 可以:
1. 使用 sync.RWMutex读写锁
2. 使用 sync.Map (并发安全的map)
17. map如何查找?
当map不存在该key,
带 comma的返回一个bool变量
不带 comma的返回一个 value的零值. 例如: int类型返回0, string类型返回空字符串
//不带 comma用法
value := m["name"]
fmt.Printf("value:%s", value)
//带 comma用法
value, ok := m["name"]
if ok {
fmt.Printf("value:%s", value)
}
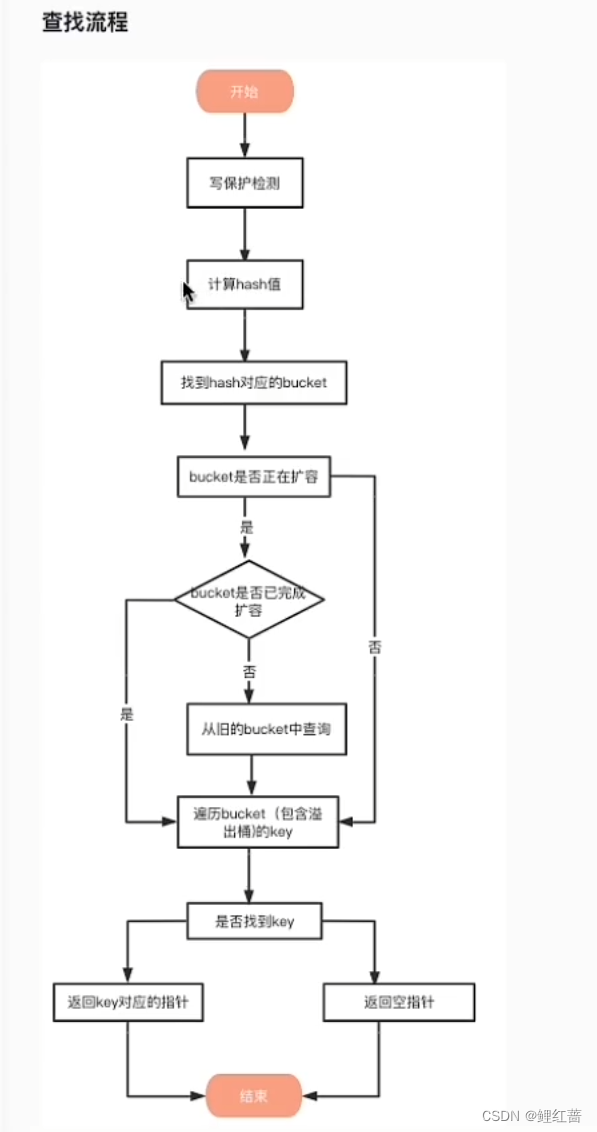
查找流程:
- map不能并发访问, 先进行写保护检测, 有并发访问直接报错
- 计算对应的 hash值, 找到对应的桶
- 判断 map是否在扩容, 如果正在扩容的过程中, 那么还是访问旧的 bucket, 如果已经扩容完毕, 那么就访问新的 bucket桶找对应的key.
- 如果找到了对应的 key, 就返回对应的指针, 如果没找到, 就返回空指针
18. map冲突的解决?
使用链地址法.
根据 hash值计算落哪个桶, 如果该桶中8个位置已经满了, 创建一个溢出桶, 以链表节点的方式链到该桶后面
19. map 的负载因子为什么是 6.5?
6.5能够使得元素更加均匀的根据hash值, 放到不同的桶中
重点: 当 map存储的元素个数 >= 6.5*桶个数时, 触发扩容
导致元素存放在桶中的位置不平均的原因:
1. 程序运行, 不断插入,删除等, 导致 bucket不均, 需要重新迁移
2. 程序运行, 出现负载因子过大, 需要做扩容, 解决 bucket过大问题
- map 如何进行扩容?
扩容条件:- 超过负载: map元素个数 > 6.5*桶个数
- 溢出桶个数太多
溢出桶总数 >= 桶总数时, 则认为溢出桶过多
扩容机制:
1. 双倍扩容: (针对超过负载):
新建一个 buckets数组, 新建的 buckets大小是原来的 2倍, 然后旧 buckets数据 迁移到新的 buckets中. 称为双倍扩容.
2. 等量扩容: (针对溢出桶过多)
并不扩大容量, buckets数量维持不变, 将元素根据 hash值重新计算桶的位置存放, 使得元素在桶中更加紧密平均
- map 和 sync.Map谁的性能更好? 为什么?
map性能更好.
map没有考虑并发安全. sync.Map操作元素有读写锁, 降低效率.
channel相关
- channel是一个队列, 先进先出, 负责协程之间的通信.
底层数据结构:
循环数组.
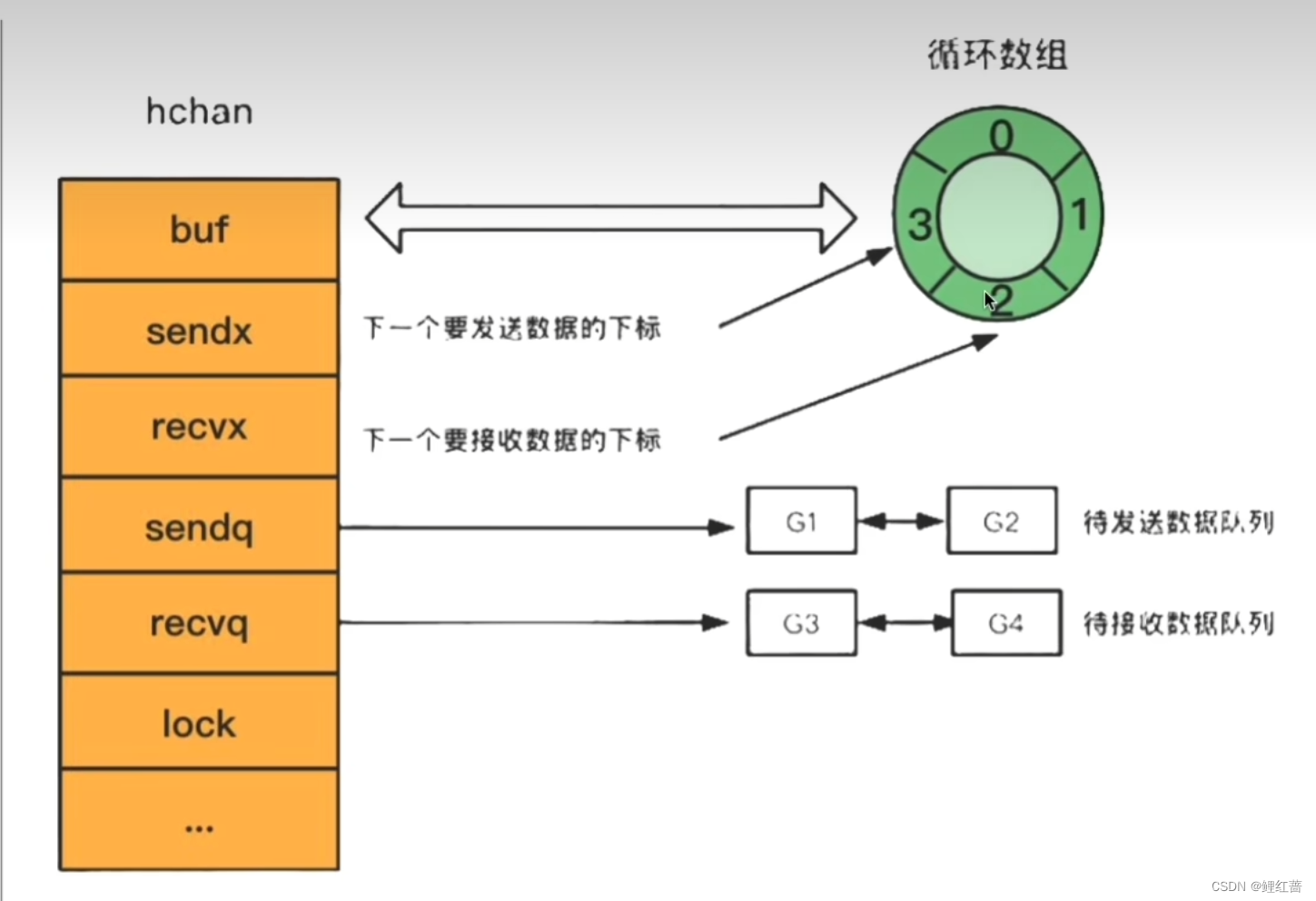
channel 结构体:
type hchan struct {
closed uint32 // channel是否关闭的标志
elemtype *_type // channel中的元素类型
// channel分为无缓冲和有缓冲两种
// 对于有缓冲的 channel存储数据, 使用了 ring buffer(环形数组)来缓存写入的数据
// 为啥是循环数组? 下标超过数组容量后回回到第一个位置, 方便记录当前读和写的位置
buf unsafe.Pointer // 指向底层循环数组的指针(环形数组)
qcount uint // 循环数组中的元素数量
dataqslz uint16 // 循环数组的长度
elesize uint16 // 元素的大小
sendx uint //下一次写下标的位置
recvx uint //下一次读下标的位置
// 尝试读取 channel或向 channel写入数据而被阻塞的 goroutine
recvq waitq // 读等待队列
sendq waitq // 写等待队列
lock mutex // 互斥锁, 保证读写 channel时不存在并发竞争问题
}
等待队列:
双向链表, 包含一个头节点和一个尾节点
每个节点是一个sudog结构体变量, 记录哪个协程在等待, 等待的是哪个 channel, 等待发送/接收的数据在哪里
等待队列节点: sudog 结构体:
type waitq struct {
first *sudog
last *sudog
}
type sudog struct {
g *g
next *sudog
prev *sudog
elem unsafe.Pointer
c *hchan
...
}
关于 channel的四种动作:
1. 创建
创建 channel有两种,
一种是带缓冲的 channel, 一种是不带缓冲的 channel
//带缓冲
ch := make(chan int, 3)
//不带缓冲
ch := make(chan int
创建时的策略:
1. 如果是无缓冲的 channel, 会直接给 hchan分配内存
2. 如果是有缓冲的 channel, 并且元素不包含指针, 那么会为 hchan和底层数组分配一段连续的地址
3. 如果有缓冲的 channel, 并且元素包含指针, 那么会为 hchan和底层数组分别分配地址
2. 发送
向 channel中发送数据时大概分为两大块:
检查和数据发送, 数据发送流程如下:
* 如果 channel的读等待队列存在接收者 goroutine
将数据直接发送给第一个等待的 goroutine, 唤醒接收的 goroutine
* 如果 channel的读等待队列不存在接收者 goroutine
* 如果循环数组 buf未满, 那么将会把数据发送到循环数组 buf的队尾
* 如果循环数组 buf已满, 这个时候就会走阻塞发送的流程, 将当前 goroutine加入写等待队列, 并挂起等待唤醒接收
3. 接收
向 channel中接收数据时大概分为两大类, 检查和数据发送, 而数据接收流程如下:
* 如果 channel的写等待队列存在发送者 goroutine
* 如果是无缓冲 channel, 直接从第一个发送者 goroutine那里把数据拷贝给接收变量, 唤醒发送的 goroutine
* 如果是有缓冲 channel(已满), 将循环数组 buf的队首元素拷贝给接收变量, 将第一个发送者 goroutine的数据拷贝到 buf循环数组队尾, 唤醒发送的 goroutine
* 如果 channel的写等待队列不存在发送者 goroutine
* 如果循环数组 buf为空, 将循环数组 buf的队首元素拷贝给接收变量
* 如果循环数组 buf为空, 这个时候会走阻塞接收的流程, 将当前 goroutine加入读等待队列, 并挂起等待唤醒
- channel的特点?
2种类型: 无缓冲, 有缓冲
3种模式: 可写, 可读, 双向
注意:
1. 一个 channel不能多次关闭, 会导致 panic
2. 多个 goroutine监听同一个 channel, channel上的数据可能随机被某一个 goroutine消费
3. 多个 goroutine监听同一个 channel, 如果这个 channel被关闭, 则所有 goroutine都能接收退出的信号
- channel 有无缓冲的区别?
无缓冲channel:
func loop(ch chan int) {
for {
select {
case i := <-ch:
fmt.Println("this value of unbuffer channel", i)
}
}
}
func main() {
ch := make(chan int)
ch <- 1
go loop(ch)
time.Sleep(1 * time.Millisecond)
}
这里会报错 deadlock, 因为 ch<-1发送了, 但是同时没有接收者, 导致主线程阻塞, 而且没有协程来解开阻塞
但如果把 ch<-1放到 go loop(ch)下面, 程序正常执行
缓冲channel:
func loop(ch chan int) {
for {
select {
case i := <-ch:
fmt.Println("this value of unbuffer channel", i)
}
}
}
func main() {
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
ch <- 4
go loop(ch)
time.Sleep(1 * time.Millisecond)
}
这里也会报 deadLock, 因为 channel大小为3, 但需要向里面装4个数据, 到这主线程阻塞.
解决方法:
-
将 channel长度调大
-
将 ch<-1代码移动到 go loop(ch)下面, 让 channel实时消费, 就不会导致阻塞了
-
channel 为什么是线程安全的?
原因: channel目的就是为了多线程通信, 保证数据一致性, 必须实现线程安全
实现方式: hchan结构体种采用 Mutex互斥锁, 对循环数组进行入队和出队时, 必须获取互斥锁 -
channel如何控制 goroutine并发执行顺序?
多个 goroutine并发执行, 并不是按照书写先后顺序执行.
思路: 使用 channel进行通信通知, 用 channel去传递信息, 从而控制并发执行顺序
var wg sync.WaitGroup
// 使用channel控制多个goroutine的执行顺序
func main() {
//声明3个管道
ch1 := make(chan struct{}, 1)
ch2 := make(chan struct{}, 1)
ch3 := make(chan struct{}, 1)
ch1 <- struct{}{}
wg.Add(3)
start := time.Now().Unix()
go Print("goroutine1", ch1, ch2)
go Print("goroutine2", ch2, ch3)
go Print("goroutine3", ch3, ch1)
wg.Wait()
end := time.Now().Unix()
fmt.Printf("duration: %d", end-start)
}
func Print(goroutine string, inputChan chan struct{}, outChan chan struct{}) {
//模拟内部操作耗时
time.Sleep(1 * time.Second)
select {
case <-inputChan:
fmt.Printf("%s \n", goroutine)
outChan <- struct{}{}
}
wg.Done()
}
-
channel 共享内存有什么优劣势?
优点: 解耦生产者和消费者, 降低并发种的耦合
缺点: 易出现死锁 -
channel 发送和接收什么情况下会发生死锁?
死锁:- 单个协程永久阻塞
- 两个或两个以上的协程, 由于竞争资源或通信造成阻塞
channel死锁场景:
* 非缓存 channel只写不读
func deadLock1() {
ch := make(chan int)
ch <- 3 // 这里会发生一直阻塞的情况,执行不到下一行
}
* 非缓存 channel读在写后面
//情况1:
func deadLock2(){
ch := make(chan int)
ch <-3 // 这里会发生一直阻塞的情况, 执行不到下面一句
num := <-ch
fmt.Println("num=", num)
}
func deadLock2() {
ch := make(chan int)
ch <- 100 // 这里会发生一直阻塞的情况, 执行不到下面一句
go func() {
num := <-ch
fmt.Println("num=", num)
}()
time.Sleep(time.Second)
}
* 缓存 channel写入超过缓冲区数量
func deadLock3(){
ch := make(chan int, 3)
ch <- 3
ch <- 4
ch <- 5
ch <- 6 // 这里会发生一直阻塞的情况
}
* 空读
func deadLock4() {
ch := make(chan int)
// ch := make(chan int, 1)
fmt.Println(<-ch) // 这里会发生一直阻塞的情况
}
* 多个协程互相等待
func deadLock5() {
ch1 := make(chan int)
ch2 := make(chan int)
// 互相等对方造成死锁
go func() {
for {
select {
case num := <-ch1:
fmt.Println("num=", num)
ch2 <- 100
}
}
}()
for {
select {
case num := <-ch2:
fmt.Println("num=", num)
ch1 <- 300
}
}
}
- 互斥锁的实现原理?
go sync包提供了两种锁类型: 互斥锁sync.Mutex和读写互斥锁sync.RWMutex, 都属于悲观锁
概念:
mutex是互斥锁, 当一个 goroutine获得了锁后, 其它 goroutine不能获取锁(只能存在一个写或者读, 不能同时读和写)
底层实现结构体:
互斥锁对应的底层结构是 sync.Mutex结构体, 位于 src/sync/mutex.go中
type Mutex struct {
state int32
sema uint32
}
state 表示锁的状态, 有锁定, 被唤醒, 饥饿模式等, 并且是用 state的二进制位来标识的, 不同模式下会有不同的处理方式
type Mutex struct {
state int32
sema uint32
}
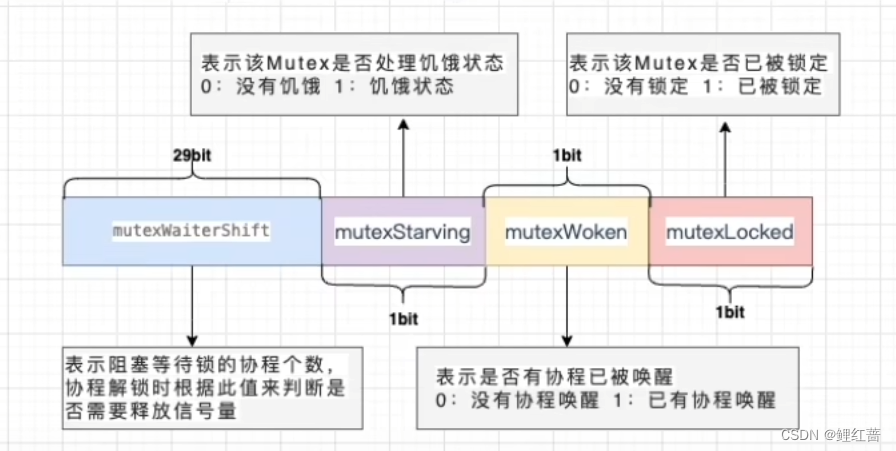
sema表示信号量, mutex阻塞队列的定位是通过这个变量来实现的, 从而实现 goroutine的阻塞和唤醒
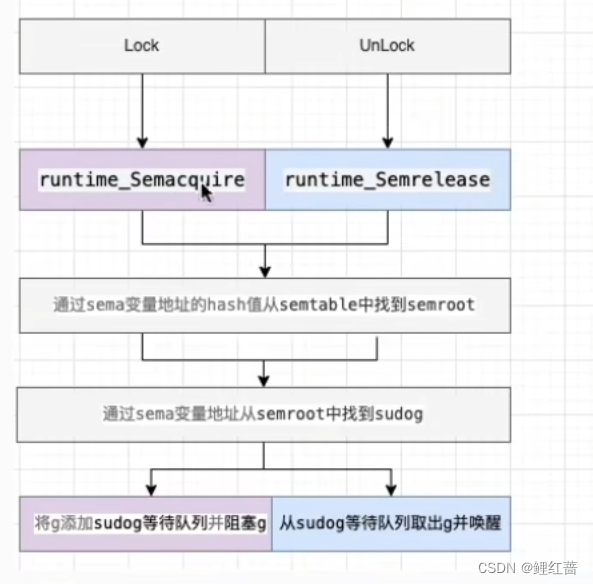
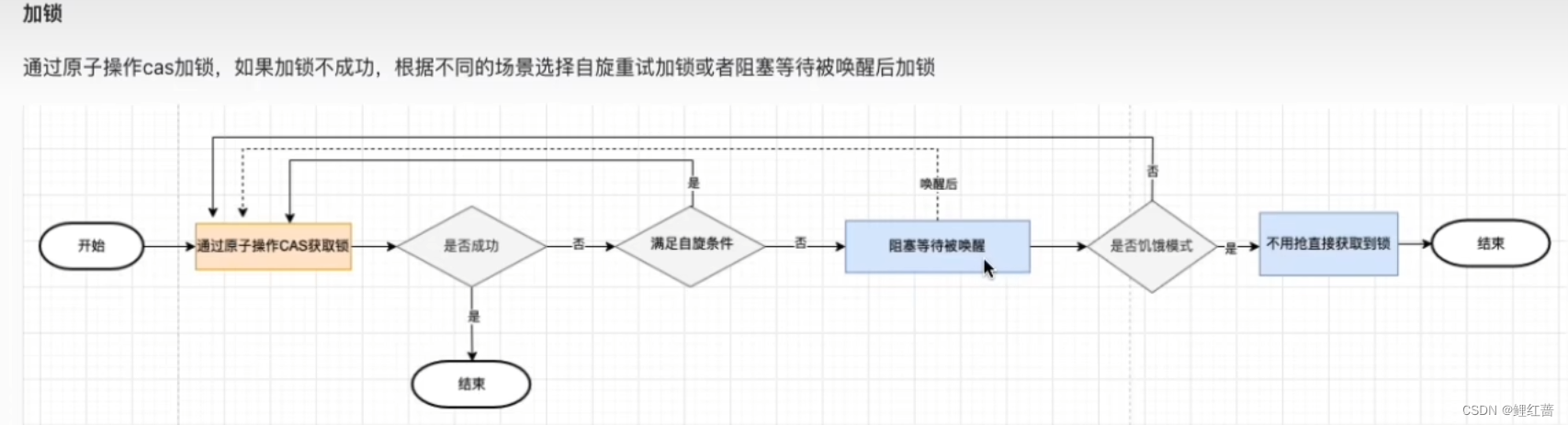
加锁的流程:
- 通过原子操作 cas获取锁, 能获取则直接成功. 获取不到说明有其它协程获取到了锁
- 没有获取到锁, 如果满足自旋条件, 进行自旋尝试获取锁
- 如果自旋次数达到4次, 进入阻塞, 进入等待队列进行等待.
- 当持有锁的协程释放锁后, 唤醒等待队列中的协程, 协程唤醒后, 和运行中的协程一起进行锁竞争, 获取锁的协程获得执行权
- 等待队列中的协程等待时间超过1ms没有获取到锁, 会直接标记位饥饿状态, 进入饥饿状态后, 等下次进行锁竞争时, 可以直接获取锁
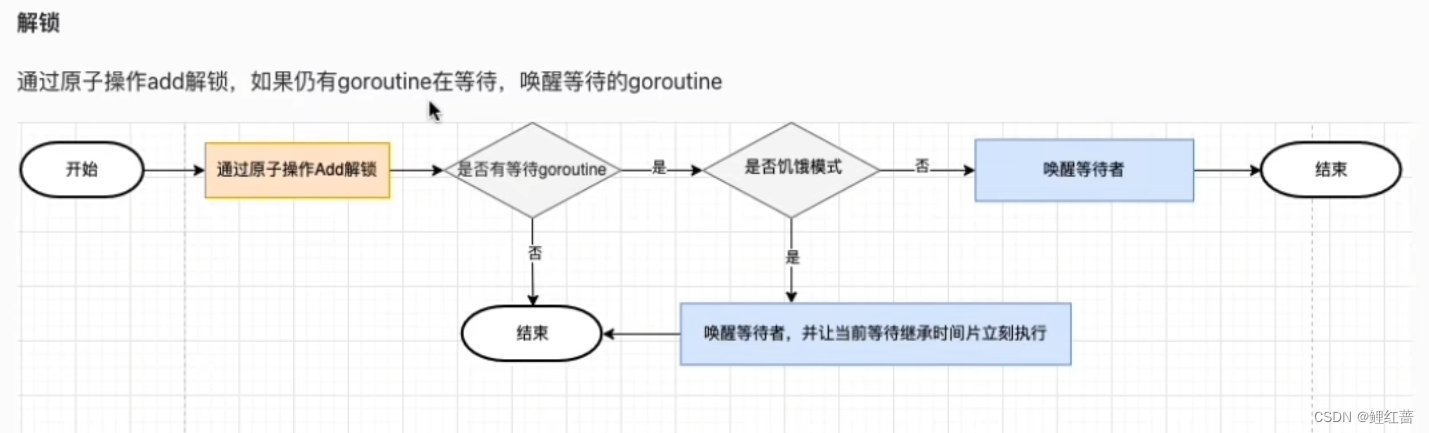
解锁流程:
6. 通过原子操作add解锁, 唤醒等待队列中的 goroutine
7. 如果被唤醒的协程是饥饿模式, 直接让该协程执行
8. 如果不是饥饿模式, 唤醒该协程即可, 让它和新加入的协程竞争锁
注意:
* Lock()之前使用 Unlock() 会导致 panic异常
* 使用 Lock()加锁后, 再次 Lock()会导致死锁(不支持重入), 需Unlock()解锁后才能再加锁
* 锁定状态与 goroutine没有关联, 一个 goroutine可以Lock, 另一个 goroutine可以Unlock
- 互斥锁正常模式和饥饿模式的区别?
正常模式(非公平锁)
在刚开始的时候, 处于正常模式, 也就是, 当一个G1持有着一个锁的时候, G2会自旋的去尝试获取这个锁
当自旋超过4次还没有能获取到锁的时候, 这个G2就会被加入到获取锁的等待队列中, 并阻塞等待唤醒.
饥饿模式(公平锁)
当一个 goroutine等待锁时间超过1毫秒时, 它可能遇到饥饿问题. 在饥饿模式下, 直接将锁交给等待队列中的第一位goroutine(队头)
当然, 也不可能说永远保持一个饥饿状态, 只要符合以下条件之一就会恢复正常模式:
-
G的执行时间小于1ms
-
等待队列已经全部清空了
-
互斥锁允许自旋的条件
1. 锁已被占用, 并且锁不处于饥饿模式
2. 积累的自旋次数 < 4次
3. cpu 核数 > 1
4. 有空闲的 P
5. 当前 goroutine所挂在的 P下, 本地待运行队列为空 -
go读写锁的实现原理?
进行读写计数
互斥锁和读写锁的区别:
* 读写锁区分读和写, 而互斥锁不区分
* 互斥锁同一时间只允许一个线程访问该对象. 无论读写; 读写锁同一时间只允许一个写, 但允许多个读访问
- 如何实现可重入锁?
go中没有实现可重入锁.
实现一个可重入锁需要以下两点:
* 记住持有锁的线程
* 统计重入的次数
type ReentrantLock struct {
sync.Mutex
recursion int32 // 这个goroutine 重入的次数
owner int64 // 当前持有锁的goroutine id
}
// Get returns the id of the current goroutine.
func GetGoroutineID() int64 {
var buf [64]byte
var s = buf[:runtime.Stack(buf[:], false)]
s = s[len("goroutine "):]
s = s[:bytes.IndexByte(s, ' ')]
gid, _ := strconv.ParseInt(string(s), 10, 64)
return gid
}
func NewReentrantLock() sync.Locker {
res := &ReentrantLock{
Mutex: sync.Mutex{},
recursion: 0,
owner: 0,
}
return res
}
// ReentrantMutex 包装一个Mutex,实现可重入
type ReentrantMutex struct {
sync.Mutex
owner int64 // 当前持有锁的goroutine id
recursion int32 // 这个goroutine 重入的次数
}
func (m *ReentrantMutex) Lock() {
gid := GetGoroutineID()
// 如果当前持有锁的goroutine就是这次调用的goroutine,说明是重入
if atomic.LoadInt64(&m.owner) == gid {
m.recursion++
return
}
m.Mutex.Lock()
// 获得锁的goroutine第一次调用,记录下它的goroutine id,调用次数加1
atomic.StoreInt64(&m.owner, gid)
m.recursion = 1
}
func (m *ReentrantMutex) Unlock() {
gid := GetGoroutineID()
// 非持有锁的goroutine尝试释放锁,错误的使用
if atomic.LoadInt64(&m.owner) != gid {
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.owner, gid))
}
// 调用次数减1
m.recursion--
if m.recursion != 0 { // 如果这个goroutine还没有完全释放,则直接返回
return
}
// 此goroutine最后一次调用,需要释放锁
atomic.StoreInt64(&m.owner, -1)
m.Mutex.Unlock()
}
func main() {
var mutex = &ReentrantMutex{}
mutex.Lock()
mutex.Lock()
fmt.Println(111)
mutex.Unlock()
mutex.Unlock()
}
- 原子操作有哪些?
常见操作:- 增减Add
func add(addr *int64, delta int64) {
atomic.AddInt64(addr, delta) //加从所
}
* 载入Load
func load(opts *int64) {
fmt.Println("load opts:", atomic.LoadInt64(opts))
}
* 比较并交换 CompareAndSwap
func compareAndSwap(addr *int64, oldValue int64, newValue int64){
if atomic.CompareAndSwapInt64(addr, oldValue, newValue) {
fmt.Println("cas opts:", *addr)
return
}
}
* 交换Swap
//相比于cas, 此操作更加暴力直接, 并不管旧值是否被改变, 直接赋予新值然后返回被替换的值
func swap(addr *int64, newValue int64) {
atomic.SwapInt64(addr, newValue)
fmt.Println("swap opts:", *addr)
}
* 存储Store
//此类操作确保了写变量的原子性, 避免其它操作读到了修改变量过程中的脏数据
func store(addr *int64, newValue int64){
atomic.StoreInt64(addr, newValue)
fmt.Println("store opts", *addr)
}
atomic操作的对象是一个地址, 你需要把可寻址的变量的地址作为参数传递给方法, 而不是把变量的值传递给方法
-
原子操作和锁的区别?
原子操作由底层硬件支持, 而锁是基于原子操作+信号量完成.
原子操作是单个指令的互斥操作: 互斥锁/读写锁是一种数据结构, 可以完成临界区(多个指令)的互斥操作, 扩大原子操作的范围
原子操作是无锁操作, 属于乐观锁 -
goroutine的底层实现原理?
type g struct {
goid int64 // 唯一的goroutine的ID
sched gobuf // goroutine切换时, 用于保存g的上下文
stack stack // 栈
gopc // pc of go statement that created this goroutine
startpc uintptr // pc of goroutine function
...
}
type gobuf struct {
sp uintptr // 栈指针位置
pc uintptr // 运行到的程序位置
g guintptr // 指向 goroutine
ret uintptr // 保存系统调用的返回值
...
}
type stack struct {
lo uintptr // 栈的下界内存地址
hi uintptr // 栈的上界内存地址
}
最终有一个 runtime.g 对象放入调度队列
状态流转:
空闲中_Gidle: G刚新建, 仍未初始化
待运行_Grunnable: 就绪状态, G在运行队列中, 等待M取出并运行
运行中_Grunning: M正在运行这个G, 这时候M会拥有一个P
系统调用中_Gsyscall: M正在运行这个G发起的系统调用, 这时候M并不拥有P
等待中_Gwaiting: G在等待某些条件完成, 这时候G不在运行也不在运行队列中(可能在channel的等待队列中)
已终止_Gdead: G未被使用, 可能已执行完毕
栈复制中_Gcopystack: G正在获取一个新的栈空间并把原来的内容复制过去(用于防止GC扫描)
g被创建后, 优先放进P的本地队列, 如果满了, 就放入全局队列
每个M开始执行P的本地队列中的 G时, goroutine会被设置为 running状态. 如果某个M把本地队列中的 G都执行完成之后, 然后就会去全局队列中拿G.
如果全局队列都被拿完了, 且当前M也没有更多 G可执行的时候, 它就会去其它 P的本地队列中拿任务, 这个机制称之为 work stealing机制.
- goroutine和线程的区别?

- gorotine泄漏的场景?
泄漏原因:
* goroutine 内进行 channel/mutex等读写操作被一直阻塞
* goroutine 内的业务逻辑进入死循环, 资源一直无法释放
* goroutine 内的业务逻辑进入长时间等待, 有不断新增的 goroutine进入等待
泄漏场景:
如果输出的 goroutines数量是在不断增加的, 就说明存在泄漏
具体场景示例:
示例1: nil channel:
channel如果忘记初始化, 那么无论你是读, 还是写操作, 都会造成阻塞.
func main() {
fmt.Println("before goroutines:", runtime.NumGoroutine())
block1()
time.Sleep(time.Second * 1)
fmt.Println("after goroutines:", runtime.NumGoroutine())
}
func block1() {
var ch chan int
for i:=0; i<10; i++ {
go func() {
<-ch
}()
}
}
示例2: 发送不接收
channel 发送数量 超过 channel接收数量, 造成阻塞
func block2 () {
ch := make(chan int)
for i:=0; i<10; i++ {
go func() {
ch<-1
}()
}
}
示例3:
func block3() {
ch := make(chan int)
for i:=0; i<10; i++ {
go func() {
<-ch
}()
}
}
示例4:
http request body未关闭:
resp.Body.Close() 未被调用时, goroutine不会退出
func requestWithNoClose() {
_, err := http.Get("https://www.baidu.com")
if err != nil {
fmt.Println("error occurred while fetching page, err:%s", err.Error())
}
}
func requestWithClose() {
resp, err := http.Get("https://www.baidu.com")
if err != nil {
fmt.Println("error occurred while fetching page, error:%s", err.Error())
return
}
defer resp.Body.Close()
}
func block4() {
for i:=0; i<10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
requestWithNoClose()
}()
}
}
var wg = sync.WaitGroup{}
func main() {
block4()
wg.Wait()
}
一般发起http请求时, 需要确保关闭body
示例5:
互斥锁忘记解锁:
// 互斥锁忘记解锁
// 第一个协程获取 sync.Mutex 加锁了, 但是他可能在处理业务逻辑, 又或是忘记Unlock了
// 因此导致后面的协程想加锁, 却因锁未释放被阻塞了
func block5() {
var mutex sync.Mutex
for i := 0; i < 10; i++ {
go func() {
mutex.Lock()
}()
}
}
示例5:
由于 wg.Add的数量与 wg.Done数量并不匹配, 因此在调用 wg.Wait方法后一直阻塞等待
func block6() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
go func() {
wg.Add(2)
wg.Done()
wg.Wait()
}()
}
}
- 如何查看正在执行的 goroutine数量?
程序中引入 pprof package:
* import _ “net/http/pprof”
程序中开启Http监听服务:
在这里插入代码片
- 如何控制并发的 goroutine数量?
为什么要控制 goroutine并发的数量?
如果滥用 goroutine, 会导致系统资源耗尽, 导致服务崩溃
如何控制 goroutine的并发数量?
方案1:
有缓冲 channel, 利用缓冲满时阻塞发送的特性
var wg = sync.WaitGroup{}
func main() {
//模拟用户请求数量
requestCount := 10
fmt.Println("goroutine_num", runtime.NumGoroutine())
//管道长度即最大并发数
ch := make(chan bool, 3)
for i := 0; i < requestCount; i++ {
wg.Add(1)
ch <- true
go Read(ch, i)
}
wg.Wait()
}
func Read(ch chan bool, i int) {
fmt.Printf("goroutine_num: %d, go func: %d", runtime.NumGoroutine(), i)
<-ch
wg.Done()
}
协程调度篇
41. 关于GMP模型?
基本概念:
1. 线程分为 "用户态"和 “内核态”, 用户态线程即协程必须绑定一个内核线程才能执行, 因为cpu只处理内核态的线程
2. 多个线程对应多个协程.
goroutine调度器:
1.线程是运行goroutine的实体, 调度器的功能是把可运行的goroutine分配到工作线程中
-
GMP和GM模型?
GMP是 go运行时调度层面的实现, 包含4个重要结构, 分别是G, M, P, Sched
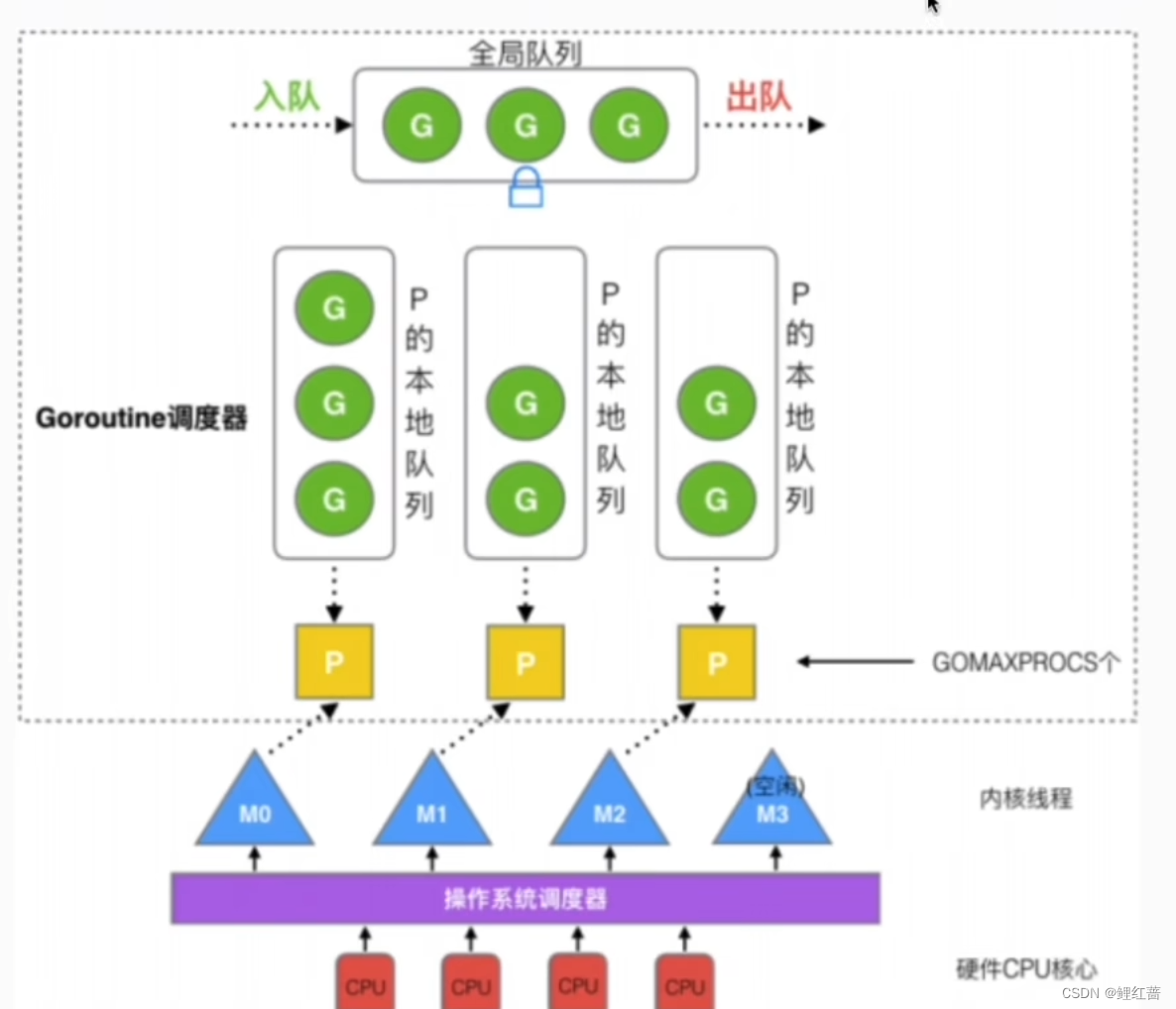
G: 就是 goroutine, 存储协程执行栈信息, 一个G初始栈大小为 2-4K
M: go对系统线程的封装. M的数量有限, 默认数量限制是 10000, 可以通过debug.SetMaxThreads()方法进行设置.
P: 执行M执行G时需要的上下文. P的数量决定了系统内最大可并行的G的数量. P的数量受本机的CPU核数影响, 可通过环境变量$GOMAXPROCS或在runtime.GOMAXPROCS()来设置, 默认为cpu核心数
Sched: 调度器结构, 它维护又存储M和G的全局队列, 以及调度器的一些状态信息 -
调度原理?
G的来源:
* P的runnext(只有一个G, 局部性原理, 永远会被最先调度执行)
* P的本地队列(数组, 最多256个G)
* 全局G队列(链表, 无限制)
* 网络轮询器network poller (存放网络调用被阻塞的G)
P的来源:
* 全局P队列(数组, GOMAXPROCS个P)
M的来源:
* 休眠线程队列 (未绑定P, 长时间休眠会等待GC回收销毁)
* 运行线程(绑定P, 指向P中的G)
* 自旋线程(绑定P, 指向M中的G0)
其中运行线程数+ 自旋线程数 <= P的数量(GOMAXPROCS), M个数>=P个数
调度策略:
使用什么策略来挑选下一个 gouroutine执行?
由于 P中的G分布在runnext, 本地队列, 全局队列, 网络轮询器中, 则需要挨个判断是否有可执行的G, 答题逻辑如下:
- 每执行61次调度, 从全局队列获取G, 若有则直接返回
- 从P上的runnext看是否有G, 若有直接返回
- 从P的本地队列看是否有G, 若有直接返回
- 上面都没找到, 则去全局队列, 网络轮询其查找或者从其它P中窃取, 一直阻塞直到获取到一个可用的G为止
-
work stealing机制?
M首先从P本地队列获取G, 如果本地队列为空,并且全局队列为空, 则从另一个本地队列偷取一半数量的G, 这种从其它P偷取G的方式称之为 work stealing -
hand off机制
也称P分离机制, 当本线程M因为G进行的系统调用阻塞时, 线程释放绑定的P, 把P转移给其它空闲的M执行, 也提高了线程利用率 -
go内存分配机制
分配组件:
go的内存管理组件主要有:
mspan: 内存分配的基本单元
mcache: 线程的本地缓存, 每个goroutine绑定一个mcche字段
mcentral: 中心缓存. mcentral管理全局的mspan供所有线程使用, 全局mheap包含字段central, 每个 mcentral结构都维护在mheap结构内
mheap: 管理go的所有动态分配内存, 是整个程序的堆空间, 全局唯一
分配对象:
- 微对象(0,16B): 先使用线程缓存上的微型分配器, 再依次尝试线程缓存, 中心缓存, 堆 分配内存
- 小对象[16B,32KB]: 依次尝试线程缓存, 中心缓存, 堆 分配内存
- 大对象(32KB,+无上限):直接尝试堆分配
分配流程:
- 首先通过计算使用的大小规格
- 然后使用 mcache中对应大小规格的块分配
- 如果 mcentral中没有可用的块, 则向 mheap申请, 并根据算法找到最合适的 mspan
- 如果申请到的 msapn超出申请大小, 将会根据需求进行切分, 以返回用户所需的页数. 剩余的页构成一个新的 mspan返回 mheap的空闲列表
- 如果 mheap中没有可用span, 则向操作系统申请一系列新的页(最小1Mb)

- 内存逃逸机制
编译器会根据变量是否被外部引用来决定是否逃逸:
1.如果函数外部没有引用, 则优先放到栈中
2.如果函数外部存在引用, 则必定放到堆中
3.如果栈上放不下, 则必定放到堆中
总结:
1.栈上分配内存比在堆中效率更高
2.栈上分配的内存不需要GC处理, 而堆需要
3.逃逸分析目的是决定内存分配地址是栈还是堆
4.逃逸分析在编译阶段完成
无论变量大小, 只要是指针变量,都会在堆上分配
-
内存对齐机制
是指内存地址是所存储数据大小(按字节为单位)的整数倍. 以便cpu可以一次将该数组从内存中读出来
优点: 提高内存的访问效率
缺点: 存在内存空间浪费, 以空间换时间 -
gc实现原理?
三色标记法+混合写屏障
灰色: 对线还在标记队列中等待
黑色: 对象已被标记 (不会被回收)
白色: 对象未被标记 (会被回收)
步骤:
1.创建: 白, 灰, 黑三个集合
2.将所有对象放入白色集合中
3.遍历所有root对象, 将其从白色放入灰色集合
4.遍历灰色集合, 沿着引用对象向下寻找, 自身标记为黑色
5.收集所有白色对象
-
gc如何调优?
1.少使用+连接string
2.slice提前分配足够的内存来降低扩容带来的拷贝
3.避免map key对象过多, 导致扫描时间增加
4.变量复用, 减少对象分配
5.增大GOGC的值, 降低GC的运行频率 -
= 和 :=的区别?
=是赋值变量, :=是定义变量 -
指针的作用:
- 获取变量的值
- 改变变量的值
- 用指针代替值传入方法擦书
-
go 允许多个返回值吗?
可以。 通常函数除了一般返回值还会返回一个error -
go 有异常类型吗?
有。 go用error类型代替try…catch语句- 可以用errors.New()来定义自己的异常。
- 可以实现Error()接口,实现自己的异常
-
什么是协程(goroutine):
是用户态轻量级线程,是线程调度的基本单位。通常在函数前加上go关键字就能实现并发。 一个goroutine会以一个很小的栈启动2kb或4kb,当遇到栈空间不足时,栈会自动伸缩,因此可以轻易实现成千上万goroutine同时启动。 -
如何高效拼接字符串
strings.Join ≈ strings.Builder > bytes.Buffer > + > fmt.Sprintf -
strings.join:
strings.join基于strings.builder来实现的,斌且可以自定义分隔符,在join方法内调用了b.Grow(n)方法,这个是进行初步的容量分配, 而且前面计算的n的长度就是我们要拼接的slice的长度,因为传入切片长度固定,所以提前进行容量分配可以减少内存分配, 很高效 -
strings.Builder
用WriteString()进行拼接,内部实现是指针+切片,同时string()返回拼接后的字符串,直接把[]byte转换为string, 从而避免变量拷贝 -
bytes.Buffer
bytes.Buffer是一个缓冲byte类型的缓冲器,这个缓冲器里存放的都是byte, bytes.buffer底层也是一个[]byte切片 -
+操作拼接,会对字符串进行遍历,计算并开辟新的空间来存储原来的两个字符串
-
fmt.Sprintf
由于采用了接口参数,必须要用反射获取值,因此有性能损耗
代码演示:
func main(){
a := []string{"a", "b", "c"}
//方式1:+
ret := a[0] + a[1] + a[2]
//方式2:fmt.Sprintf
ret := fmt.Sprintf("%s%s%s", a[0],a[1],a[2])
//方式3:strings.Builder
var sb strings.Builder
sb.WriteString(a[0])
sb.WriteString(a[1])
sb.WriteString(a[2])
ret := sb.String()
//方式4:bytes.Buffer
buf := new(bytes.Buffer)
buf.Write(a[0])
buf.Write(a[1])
buf.Write(a[2])
ret := buf.String()
//方式5:strings.Join
ret := strings.Join(a,"")
}
- 什么是 rune类型
书写系统的所有字符对应的标准编码,是int32类型的别名
sample := "我爱GO"
runeSamp := []rune(sample)
runeSamp[0] = '你'
fmt.Println(string(runeSamp)) // "你爱GO"
fmt.Println(len(runeSamp)) // 4
- 如何判断 map中是否包含某个 key?
var sampleMap map[int]int
if _, ok := sampleMap[10]; ok {
...
} else {
...
}
- go 支持默认参数或可选参数吗?
不支持。 但是可以利用结构体参数,或者…传入参数切片数组。
// 传入结构体参数
struct Options {
concurrent bool
}
func pread(offset int64, len int64, o *Options) {
...
}
// 这个函数可以传入任意数量的整型参数
func sumN(nums ...int) int {
total := 0
for _, num := range nums {
total += num
}
return total
}
-
defer 的执行顺序?
符合栈的先进后出。 defer在return之后执行,但在函数退出之前,defer可以修改返回值。 -
如何交换 2个变量的值?
对于变量而言a,b = b,a; 对于指针而言 *a,*b = *b, *a -
go 语言tag的用处?
可以为结构体成员提供属性。常见的:- json序列化或反序列化时字段的名称
- db: sqlx模块中对应的数据库字段名
-
如何获取一个结构体的所有tag?
import reflect
type Author struct {
Name int `json:Name`
Publications []string `json:Publication,omitempty`
}
func main() {
t := reflect.TypeOf(Author{})
for i := 0; i < t.NumField(); i++ {
name := t.Field(i).Name
s, _ := t.FieldByName(name)
fmt.Println(name, s.Tag)
}
}
上述例子中,reflect.TypeOf方法获取对象的类型,之后NumField()获取结构体成员的数量。 通过Field(i)获取第i个成员的名字。 再通过其Tag 方法获得标签。
-
如何判断 2个字符串切片是相等的?
reflect.DeepEqual(), 但反射非常影响性能 -
结构体打印时,%v和%+v的区别?
%v输出结构体各成员的值;
%+v输出结构体各成员的名称和值;
%#v输出结构体名称和结构体各成员的名称和值; -
go 语言中如何表示枚举值?
const (
B = 1 << (10 * iota)
KiB
MiB
GiB
TiB
PiB
EiB
)
- 空 struct{}的用途
- 用map模拟一个set, 那么就要把值置为struct{}, struct{}本身不占任何空间,可以避免任何多余的内存分配
type Set map[string]struct{}
func main() {
set := make(Set)
for _, item := range []string{"A", "A", "B", "C"} {
set[item] = struct{}{}
}
fmt.Println(len(set)) // 3
if _, ok := set["A"]; ok {
fmt.Println("A exists") // A exists
}
}
- 有时给通道发送一个空结构体,channel<-struct{}, 也是节省了空间。
func main() {
ch := make(chan struct{}, 1)
go func() {
<-ch
// do something
}()
ch <- struct{}{}
// ...
}
- 仅有方法的结构体
type Lamp struct{}
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- ff
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f
- f


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









